 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel Adaptation for ASR in low-resource Indian Languages
Jul 16, 2023Automatic speech recognition (ASR) performance has improved drastically in recent years, mainly enabled by self-supervised learning (SSL) based acoustic models such as wav2vec2 and large-scale multi-lingual training like Whisper. A huge challenge still exists for low-resource languages where the availability of both audio and text is limited. This is further complicated by the presence of multiple dialects like in Indian languages. However, many Indian languages can be grouped into the same families and share the same script and grammatical structure. This is where a lot of adaptation and fine-tuning techniques can be applied to overcome the low-resource nature of the data by utilising well-resourced similar languages. In such scenarios, it is important to understand the extent to which each modality, like acoustics and text, is important in building a reliable ASR. It could be the case that an abundance of acoustic data in a language reduces the need for large text-only corpora. Or, due to the availability of various pretrained acoustic models, the vice-versa could also be true. In this proposed special session, we encourage the community to explore these ideas with the data in two low-resource Indian languages of Bengali and Bhojpuri. These approaches are not limited to Indian languages, the solutions are potentially applicable to various languages spoken around the world.
Multilingual and code-switching ASR challenges for low resource Indian languages
Apr 01, 2021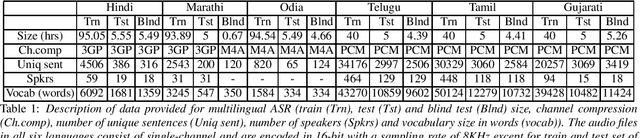
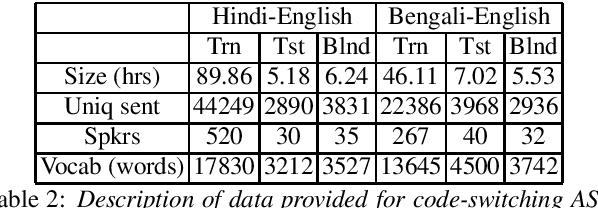
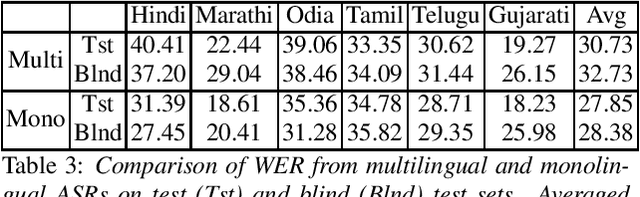
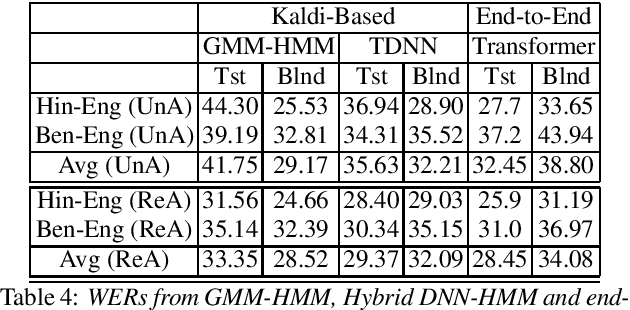
Recently, there is increasing interest in multilingual automatic speech recognition (ASR) where a speech recognition system caters to multiple low resource languages by taking advantage of low amounts of labeled corpora in multiple languages. With multilingualism becoming common in today's world, there has been increasing interest in code-switching ASR as well. In code-switching, multiple languages are freely interchanged within a single sentence or between sentences. The success of low-resource multilingual and code-switching ASR often depends on the variety of languages in terms of their acoustics, linguistic characteristics as well as the amount of data available and how these are carefully considered in building the ASR system. In this challenge, we would like to focus on building multilingual and code-switching ASR systems through two different subtasks related to a total of seven Indian languages, namely Hindi, Marathi, Odia, Tamil, Telugu, Gujarati and Bengali. For this purpose, we provide a total of ~600 hours of transcribed speech data, comprising train and test sets, in these languages including two code-switched language pairs, Hindi-English and Bengali-English. We also provide a baseline recipe for both the tasks with a WER of 30.73% and 32.45% on the test sets of multilingual and code-switching subtasks, respectively.