 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking Popular Classification Models' Robustness to Random and Targeted Corruptions
Paper and Code

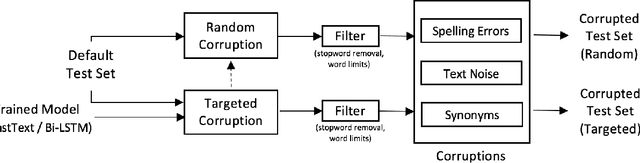

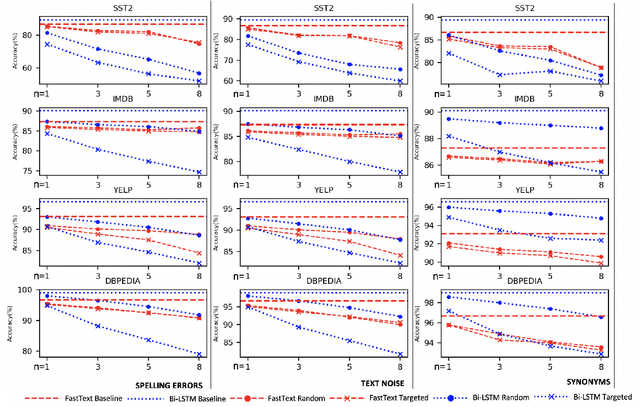
Text classification models, especially neural networks based models, have reached very high accuracy on many popular benchmark datasets. Yet, such models when deployed in real world applications, tend to perform badly. The primary reason is that these models are not tested against sufficient real world natural data. Based on the application users, the vocabulary and the style of the model's input may greatly vary. This emphasizes the need for a model agnostic test dataset, which consists of various corruptions that are natural to appear in the wild. Models trained and tested on such benchmark datasets, will be more robust against real world data. However, such data sets are not easily available. In this work, we address this problem, by extending the benchmark datasets along naturally occurring corruptions such as Spelling Errors, Text Noise and Synonyms and making them publicly available. Through extensive experiments, we compare random and targeted corruption strategies using Local Interpretable Model-Agnostic Explanations(LIME). We report the vulnerabilities in two popular text classification models along these corruptions and also find that targeted corruptions can expose vulnerabilities of a model better than random choices in most cases.