 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNBF at SemEval-2025 Task 5: Light-Burst Attention Enhanced System for Multilingual Subject Recommendation
May 06, 2025We present our system submission for SemEval 2025 Task 5, which focuses on cross-lingual subject classification in the English and German academic domains. Our approach leverages bilingual data during training, employing negative sampling and a margin-based retrieval objective. We demonstrate that a dimension-as-token self-attention mechanism designed with significantly reduced internal dimensions can effectively encode sentence embeddings for subject retrieval. In quantitative evaluation, our system achieved an average recall rate of 32.24% in the general quantitative setting (all subjects), 43.16% and 31.53% of the general qualitative evaluation methods with minimal GPU usage, highlighting their competitive performance. Our results demonstrate that our approach is effective in capturing relevant subject information under resource constraints, although there is still room for improvement.
Text Simplification for Comprehension-based Question-Answering
Sep 28, 2021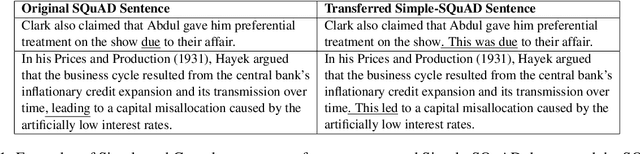
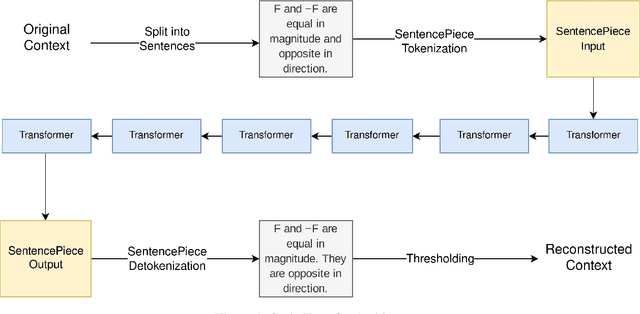
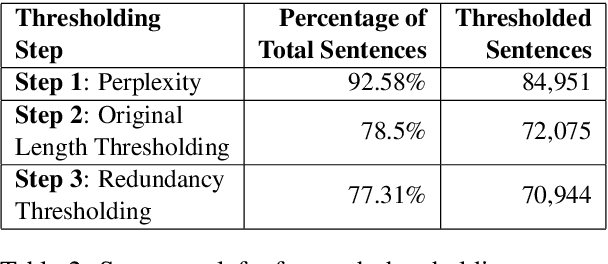
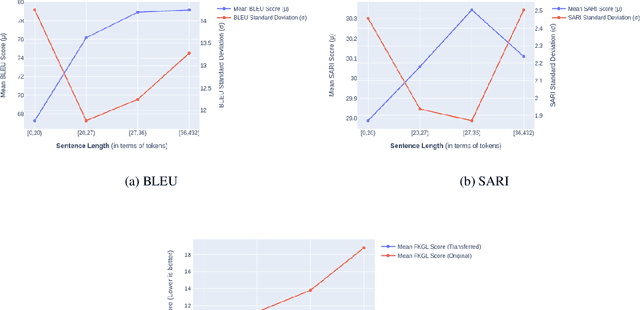
Text simplification is the process of splitting and rephrasing a sentence to a sequence of sentences making it easier to read and understand while preserving the content and approximating the original meaning. Text simplification has been exploited in NLP applications like machine translation, summarization, semantic role labeling, and information extraction, opening a broad avenue for its exploitation in comprehension-based question-answering downstream tasks. In this work, we investigate the effect of text simplification in the task of question-answering using a comprehension context. We release Simple-SQuAD, a simplified version of the widely-used SQuAD dataset. Firstly, we outline each step in the dataset creation pipeline, including style transfer, thresholding of sentences showing correct transfer, and offset finding for each answer. Secondly, we verify the quality of the transferred sentences through various methodologies involving both automated and human evaluation. Thirdly, we benchmark the newly created corpus and perform an ablation study for examining the effect of the simplification process in the SQuAD-based question answering task. Our experiments show that simplification leads to up to 2.04% and 1.74% increase in Exact Match and F1, respectively. Finally, we conclude with an analysis of the transfer process, investigating the types of edits made by the model, and the effect of sentence length on the transfer model.
IIITG-ADBU@HASOC-Dravidian-CodeMix-FIRE2020: Offensive Content Detection in Code-Mixed Dravidian Text
Jul 29, 2021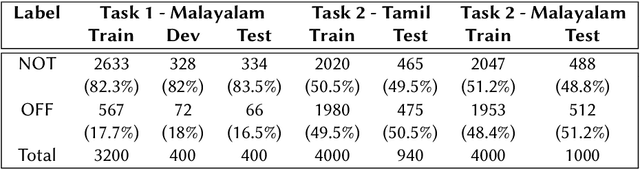
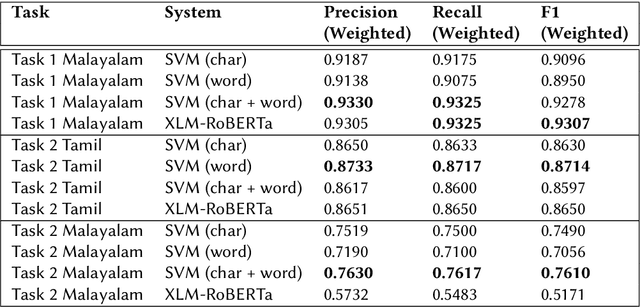
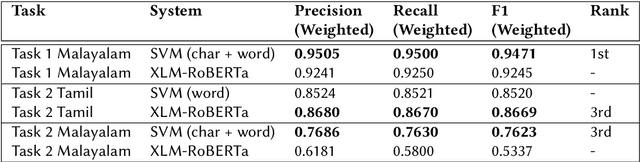
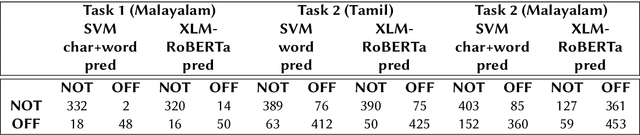
This paper presents the results obtained by our SVM and XLM-RoBERTa based classifiers in the shared task Dravidian-CodeMix-HASOC 2020. The SVM classifier trained using TF-IDF features of character and word n-grams performed the best on the code-mixed Malayalam text. It obtained a weighted F1 score of 0.95 (1st Rank) and 0.76 (3rd Rank) on the YouTube and Twitter dataset respectively. The XLM-RoBERTa based classifier performed the best on the code-mixed Tamil text. It obtained a weighted F1 score of 0.87 (3rd Rank) on the code-mixed Tamil Twitter dataset.
Gaze-based Autism Detection for Adolescents and Young Adults using Prosaic Videos
May 26, 2020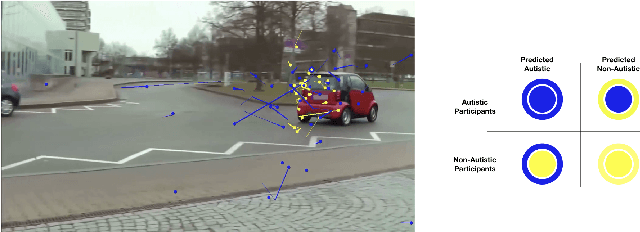


Autism often remains undiagnosed in adolescents and adults. Prior research has indicated that an autistic individual often shows atypical fixation and gaze patterns. In this short paper, we demonstrate that by monitoring a user's gaze as they watch commonplace (i.e., not specialized, structured or coded) video, we can identify individuals with autism spectrum disorder. We recruited 35 autistic and 25 non-autistic individuals, and captured their gaze using an off-the-shelf eye tracker connected to a laptop. Within 15 seconds, our approach was 92.5% accurate at identifying individuals with an autism diagnosis. We envision such automatic detection being applied during e.g., the consumption of web media, which could allow for passive screening and adaptation of user interfaces.
A Hitchhiker's Guide On Distributed Training of Deep Neural Networks
Oct 28, 2018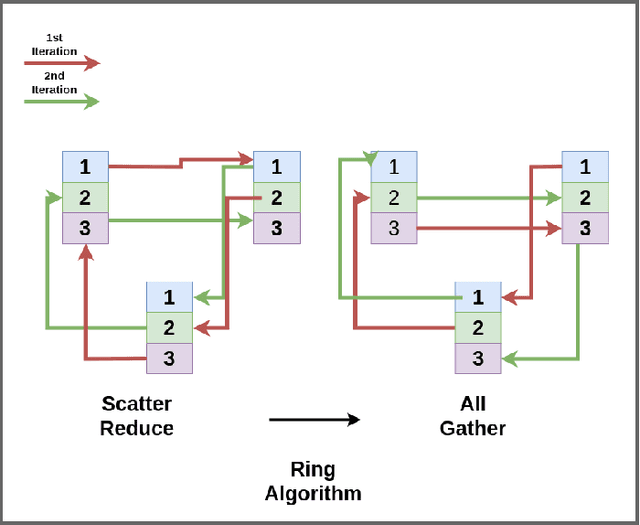
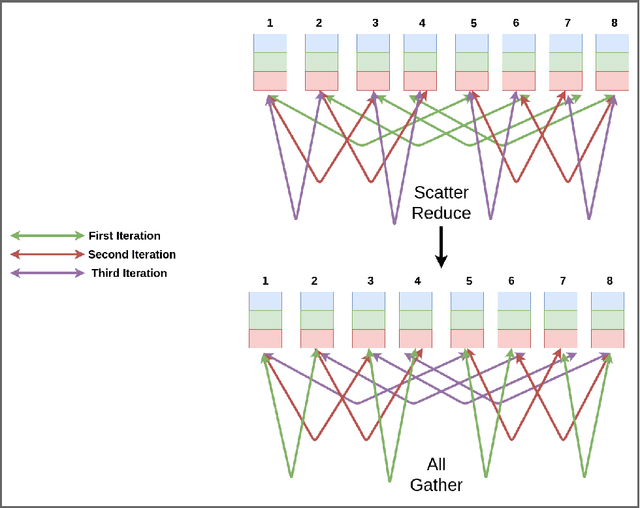
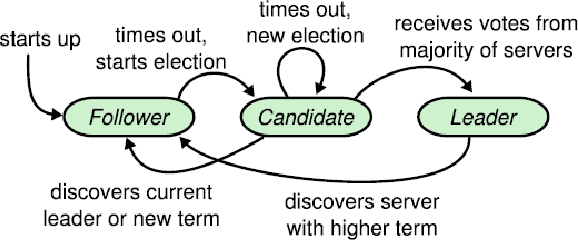
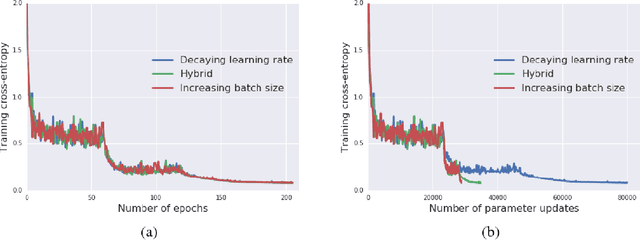
Deep learning has led to tremendous advancements in the field of Artificial Intelligence. One caveat however is the substantial amount of compute needed to train these deep learning models. Training a benchmark dataset like ImageNet on a single machine with a modern GPU can take upto a week, distributing training on multiple machines has been observed to drastically bring this time down. Recent work has brought down ImageNet training time to a time as low as 4 minutes by using a cluster of 2048 GPUs. This paper surveys the various algorithms and techniques used to distribute training and presents the current state of the art for a modern distributed training framework. More specifically, we explore the synchronous and asynchronous variants of distributed Stochastic Gradient Descent, various All Reduce gradient aggregation strategies and best practices for obtaining higher throughout and lower latency over a cluster such as mixed precision training, large batch training and gradient compression.
AI Fairness 360: An Extensible Toolkit for Detecting, Understanding, and Mitigating Unwanted Algorithmic Bias
Oct 03, 2018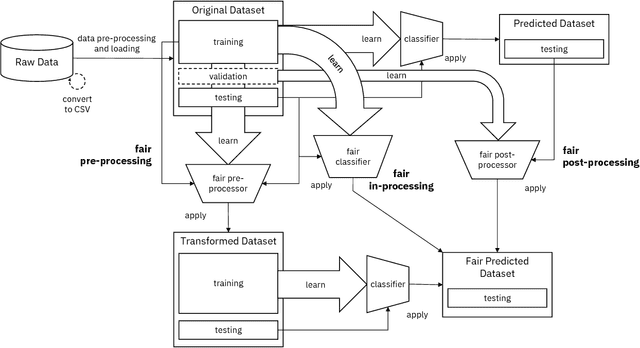
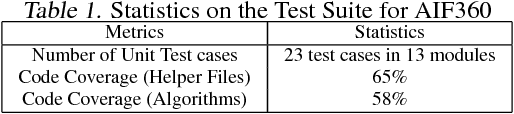
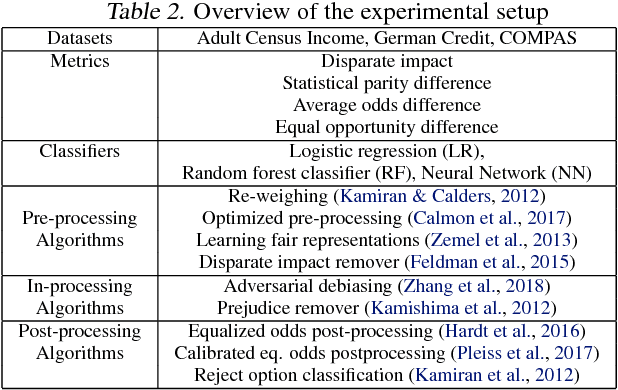
Fairness is an increasingly important concern as machine learning models are used to support decision making in high-stakes applications such as mortgage lending, hiring, and prison sentencing. This paper introduces a new open source Python toolkit for algorithmic fairness, AI Fairness 360 (AIF360), released under an Apache v2.0 license {https://github.com/ibm/aif360). The main objectives of this toolkit are to help facilitate the transition of fairness research algorithms to use in an industrial setting and to provide a common framework for fairness researchers to share and evaluate algorithms. The package includes a comprehensive set of fairness metrics for datasets and models, explanations for these metrics, and algorithms to mitigate bias in datasets and models. It also includes an interactive Web experience (https://aif360.mybluemix.net) that provides a gentle introduction to the concepts and capabilities for line-of-business users, as well as extensive documentation, usage guidance, and industry-specific tutorials to enable data scientists and practitioners to incorporate the most appropriate tool for their problem into their work products. The architecture of the package has been engineered to conform to a standard paradigm used in data science, thereby further improving usability for practitioners. Such architectural design and abstractions enable researchers and developers to extend the toolkit with their new algorithms and improvements, and to use it for performance benchmarking. A built-in testing infrastructure maintains code quality.
Automated Test Generation to Detect Individual Discrimination in AI Models
Sep 10, 2018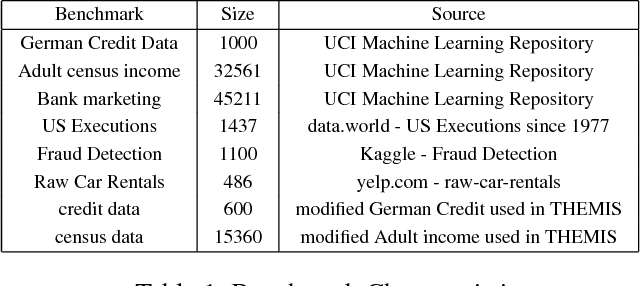

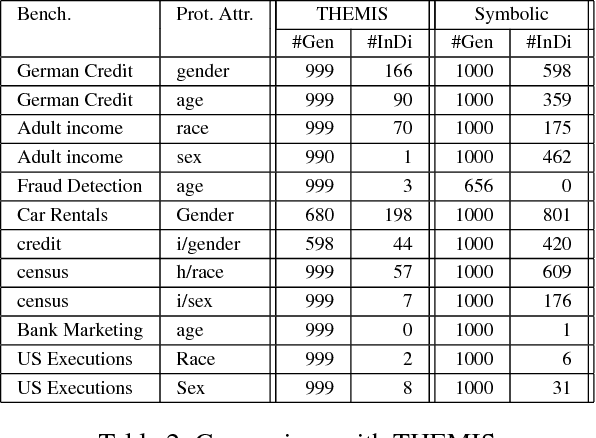
Dependability on AI models is of utmost importance to ensure full acceptance of the AI systems. One of the key aspects of the dependable AI system is to ensure that all its decisions are fair and not biased towards any individual. In this paper, we address the problem of detecting whether a model has an individual discrimination. Such a discrimination exists when two individuals who differ only in the values of their protected attributes (such as, gender/race) while the values of their non-protected ones are exactly the same, get different decisions. Measuring individual discrimination requires an exhaustive testing, which is infeasible for a non-trivial system. In this paper, we present an automated technique to generate test inputs, which is geared towards finding individual discrimination. Our technique combines the well-known technique called symbolic execution along with the local explainability for generation of effective test cases. Our experimental results clearly demonstrate that our technique produces 3.72 times more successful test cases than the existing state-of-the-art across all our chosen benchmarks.
A Survey of Modern Object Detection Literature using Deep Learning
Aug 22, 2018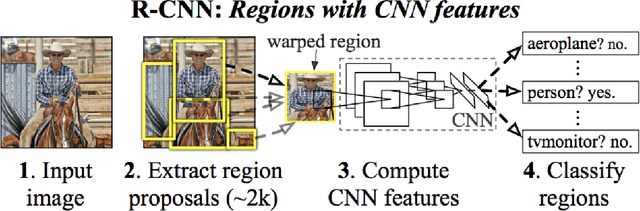
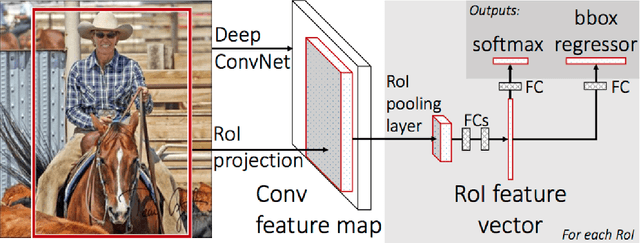
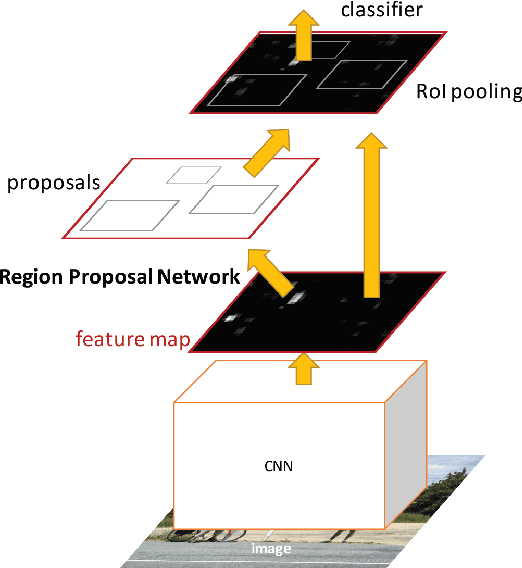
Object detection is the identification of an object in the image along with its localisation and classification. It has wide spread applications and is a critical component for vision based software systems. This paper seeks to perform a rigorous survey of modern object detection algorithms that use deep learning. As part of the survey, the topics explored include various algorithms, quality metrics, speed/size trade offs and training methodologies. This paper focuses on the two types of object detection algorithms- the SSD class of single step detectors and the Faster R-CNN class of two step detectors. Techniques to construct detectors that are portable and fast on low powered devices are also addressed by exploring new lightweight convolutional base architectures. Ultimately, a rigorous review of the strengths and weaknesses of each detector leads us to the present state of the art.
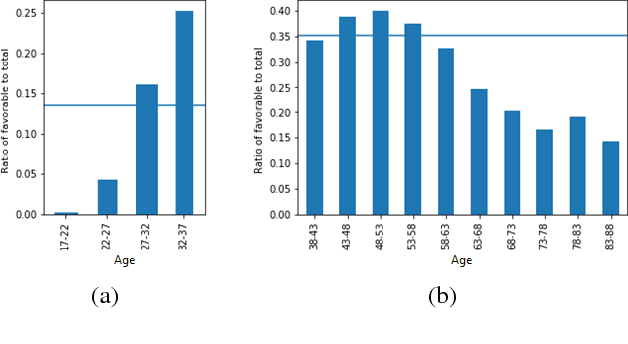
Topical Stance Detection for Twitter: A Two-Phase LSTM Model Using Attention
Jan 09, 2018
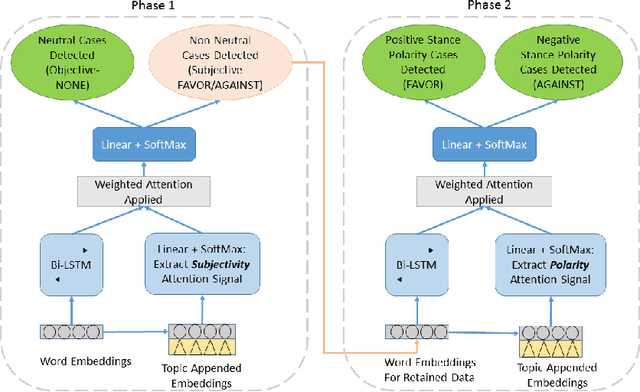
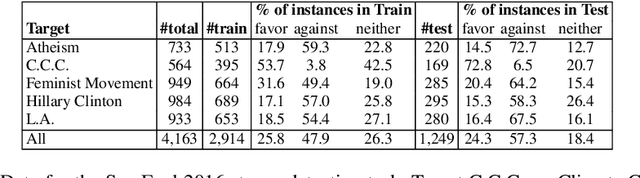

The topical stance detection problem addresses detecting the stance of the text content with respect to a given topic: whether the sentiment of the given text content is in FAVOR of (positive), is AGAINST (negative), or is NONE (neutral) towards the given topic. Using the concept of attention, we develop a two-phase solution. In the first phase, we classify subjectivity - whether a given tweet is neutral or subjective with respect to the given topic. In the second phase, we classify sentiment of the subjective tweets (ignoring the neutral tweets) - whether a given subjective tweet has a FAVOR or AGAINST stance towards the topic. We propose a Long Short-Term memory (LSTM) based deep neural network for each phase, and embed attention at each of the phases. On the SemEval 2016 stance detection Twitter task dataset, we obtain a best-case macro F-score of 68.84% and a best-case accuracy of 60.2%, outperforming the existing deep learning based solutions. Our framework, T-PAN, is the first in the topical stance detection literature, that uses deep learning within a two-phase architecture.
EmTaggeR: A Word Embedding Based Novel Method for Hashtag Recommendation on Twitter
Dec 05, 2017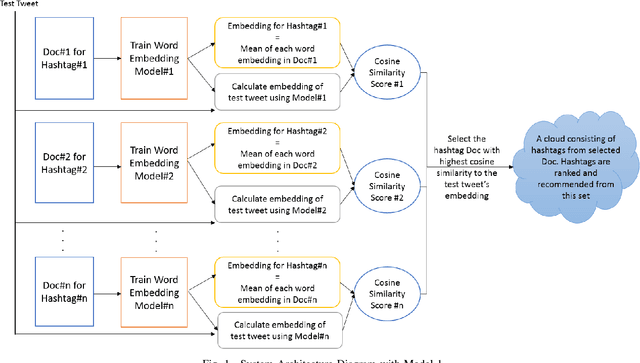
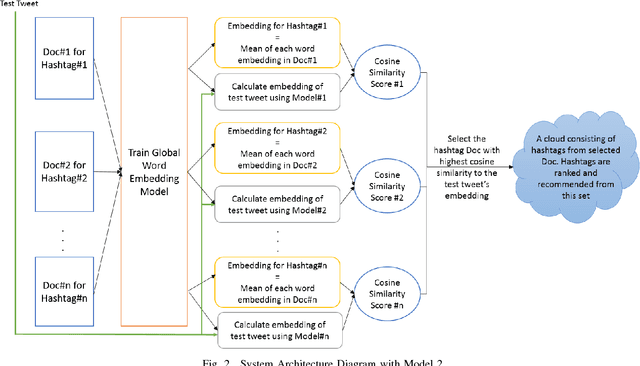
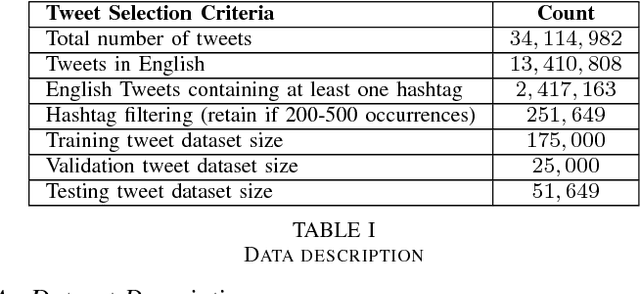

The hashtag recommendation problem addresses recommending (suggesting) one or more hashtags to explicitly tag a post made on a given social network platform, based upon the content and context of the post. In this work, we propose a novel methodology for hashtag recommendation for microblog posts, specifically Twitter. The methodology, EmTaggeR, is built upon a training-testing framework that builds on the top of the concept of word embedding. The training phase comprises of learning word vectors associated with each hashtag, and deriving a word embedding for each hashtag. We provide two training procedures, one in which each hashtag is trained with a separate word embedding model applicable in the context of that hashtag, and another in which each hashtag obtains its embedding from a global context. The testing phase constitutes computing the average word embedding of the test post, and finding the similarity of this embedding with the known embeddings of the hashtags. The tweets that contain the most-similar hashtag are extracted, and all the hashtags that appear in these tweets are ranked in terms of embedding similarity scores. The top-K hashtags that appear in this ranked list, are recommended for the given test post. Our system produces F1 score of 50.83%, improving over the LDA baseline by around 6.53 times, outperforming the best-performing system known in the literature that provides a lift of 6.42 times. EmTaggeR is a fast, scalable and lightweight system, which makes it practical to deploy in real-life applications.