 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePatch-wise Features for Blur Image Classification
Apr 06, 2023



Images captured through smartphone cameras often suffer from degradation, blur being one of the major ones, posing a challenge in processing these images for downstream tasks. In this paper we propose low-compute lightweight patch-wise features for image quality assessment. Using our method we can discriminate between blur vs sharp image degradation. To this end, we train a decision-tree based XGBoost model on various intuitive image features like gray level variance, first and second order gradients, texture features like local binary patterns. Experiments conducted on an open dataset show that the proposed low compute method results in 90.1% mean accuracy on the validation set, which is comparable to the accuracy of a compute-intensive VGG16 network with 94% mean accuracy fine-tuned to this task. To demonstrate the generalizability of our proposed features and model we test the model on BHBID dataset and an internal dataset where we attain accuracy of 98% and 91%, respectively. The proposed method is 10x faster than the VGG16 based model on CPU and scales linearly to the input image size making it suitable to be implemented on low compute edge devices.
Gaze-based Autism Detection for Adolescents and Young Adults using Prosaic Videos
May 26, 2020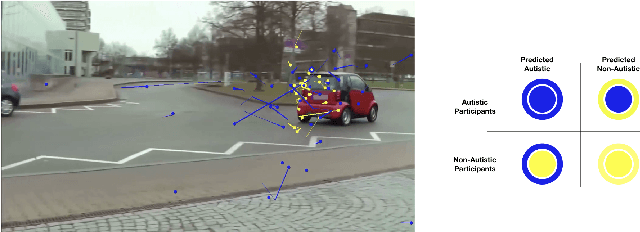


Autism often remains undiagnosed in adolescents and adults. Prior research has indicated that an autistic individual often shows atypical fixation and gaze patterns. In this short paper, we demonstrate that by monitoring a user's gaze as they watch commonplace (i.e., not specialized, structured or coded) video, we can identify individuals with autism spectrum disorder. We recruited 35 autistic and 25 non-autistic individuals, and captured their gaze using an off-the-shelf eye tracker connected to a laptop. Within 15 seconds, our approach was 92.5% accurate at identifying individuals with an autism diagnosis. We envision such automatic detection being applied during e.g., the consumption of web media, which could allow for passive screening and adaptation of user interfaces.
Bi-Linear Modeling of Data Manifolds for Dynamic-MRI Recovery
Dec 27, 2018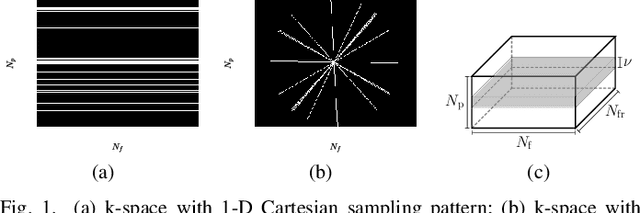
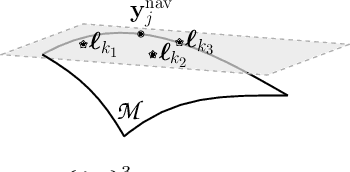
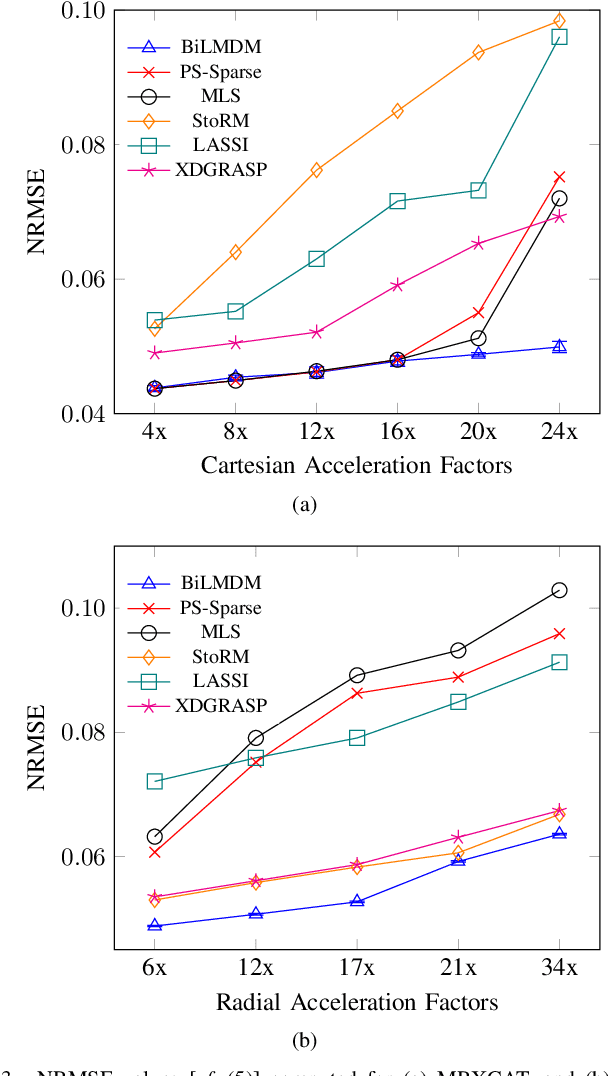
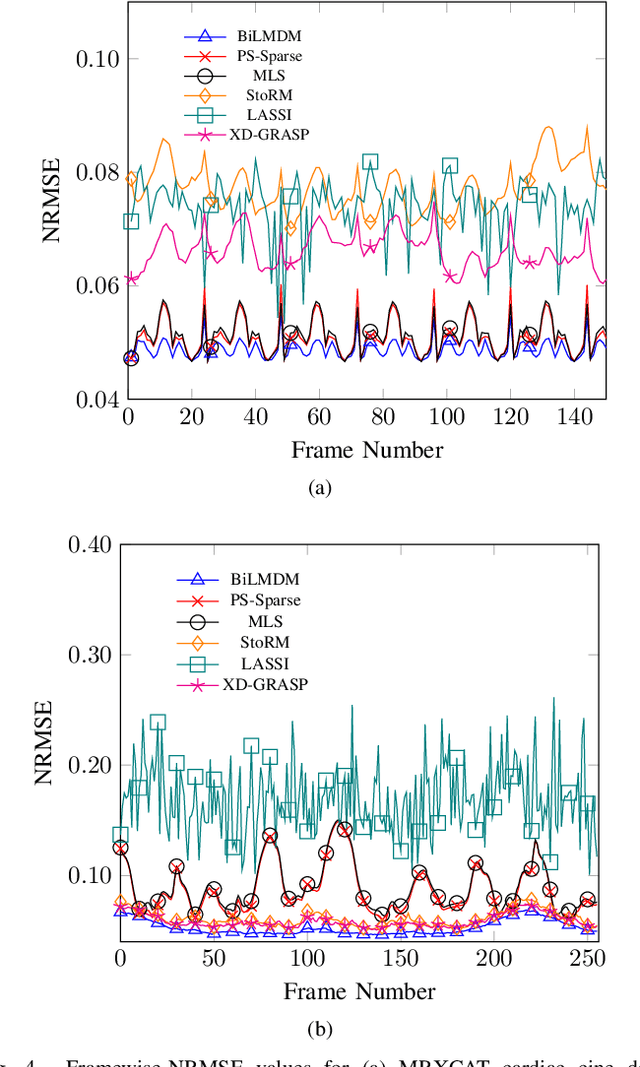
This paper puts forth a novel bi-linear modeling framework for data recovery via manifold-learning and sparse-approximation arguments and considers its application to dynamic magnetic-resonance imaging (dMRI). Each temporal-domain MR image is viewed as a point that lies onto or close to a smooth manifold, and landmark points are identified to describe the point cloud concisely. To facilitate computations, a dimensionality reduction module generates low-dimensional/compressed renditions of the landmark points. Recovery of the high-fidelity MRI data is realized by solving a non-convex minimization task for the linear decompression operator and those affine combinations of landmark points which locally approximate the latent manifold geometry. An algorithm with guaranteed convergence to stationary solutions of the non-convex minimization task is also provided. The aforementioned framework exploits the underlying spatio-temporal patterns and geometry of the acquired data without any prior training on external data or information. Extensive numerical results on simulated as well as real cardiac-cine and perfusion MRI data illustrate noteworthy improvements of the advocated machine-learning framework over state-of-the-art reconstruction techniques.