 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExternal Division of Two Bregman Proximity Operators for Poisson Inverse Problems
Feb 12, 2026This paper presents a novel method for recovering sparse vectors from linear models corrupted by Poisson noise. The contribution is twofold. First, an operator defined via the external division of two Bregman proximity operators is introduced to promote sparse solutions while mitigating the estimation bias induced by classical $\ell_1$-norm regularization. This operator is then embedded into the already established NoLips algorithm, replacing the standard Bregman proximity operator in a plug-and-play manner. Second, the geometric structure of the proposed external-division operator is elucidated through two complementary reformulations, which provide clear interpretations in terms of the primal and dual spaces of the Poisson inverse problem. Numerical tests show that the proposed method exhibits more stable convergence behavior than conventional Kullback-Leibler (KL)-based approaches and achieves significantly superior performance on synthetic data and an image restoration problem.
Gaussian-Mixture-Model Q-Functions for Policy Iteration in Reinforcement Learning
Dec 21, 2025Unlike their conventional use as estimators of probability density functions in reinforcement learning (RL), this paper introduces a novel function-approximation role for Gaussian mixture models (GMMs) as direct surrogates for Q-function losses. These parametric models, termed GMM-QFs, possess substantial representational capacity, as they are shown to be universal approximators over a broad class of functions. They are further embedded within Bellman residuals, where their learnable parameters -- a fixed number of mixing weights, together with Gaussian mean vectors and covariance matrices -- are inferred from data via optimization on a Riemannian manifold. This geometric perspective on the parameter space naturally incorporates Riemannian optimization into the policy-evaluation step of standard policy-iteration frameworks. Rigorous theoretical results are established, and supporting numerical tests show that, even without access to experience data, GMM-QFs deliver competitive performance and, in some cases, outperform state-of-the-art approaches across a range of benchmark RL tasks, all while maintaining a significantly smaller computational footprint than deep-learning methods that rely on experience data.
Kernel Regression of Multi-Way Data via Tensor Trains with Hadamard Overparametrization: The Dynamic Graph Flow Case
Sep 26, 2025A regression-based framework for interpretable multi-way data imputation, termed Kernel Regression via Tensor Trains with Hadamard overparametrization (KReTTaH), is introduced. KReTTaH adopts a nonparametric formulation by casting imputation as regression via reproducing kernel Hilbert spaces. Parameter efficiency is achieved through tensors of fixed tensor-train (TT) rank, which reside on low-dimensional Riemannian manifolds, and is further enhanced via Hadamard overparametrization, which promotes sparsity within the TT parameter space. Learning is accomplished by solving a smooth inverse problem posed on the Riemannian manifold of fixed TT-rank tensors. As a representative application, the estimation of dynamic graph flows is considered. In this setting, KReTTaH exhibits flexibility by seamlessly incorporating graph-based (topological) priors via its inverse problem formulation. Numerical tests on real-world graph datasets demonstrate that KReTTaH consistently outperforms state-of-the-art alternatives-including a nonparametric tensor- and a neural-network-based methods-for imputing missing, time-varying edge flows.
Nonconvex Regularization for Feature Selection in Reinforcement Learning
Sep 19, 2025This work proposes an efficient batch algorithm for feature selection in reinforcement learning (RL) with theoretical convergence guarantees. To mitigate the estimation bias inherent in conventional regularization schemes, the first contribution extends policy evaluation within the classical least-squares temporal-difference (LSTD) framework by formulating a Bellman-residual objective regularized with the sparsity-inducing, nonconvex projected minimax concave (PMC) penalty. Owing to the weak convexity of the PMC penalty, this formulation can be interpreted as a special instance of a general nonmonotone-inclusion problem. The second contribution establishes novel convergence conditions for the forward-reflected-backward splitting (FRBS) algorithm to solve this class of problems. Numerical experiments on benchmark datasets demonstrate that the proposed approach substantially outperforms state-of-the-art feature-selection methods, particularly in scenarios with many noisy features.
Online reinforcement learning via sparse Gaussian mixture model Q-functions
Sep 18, 2025This paper introduces a structured and interpretable online policy-iteration framework for reinforcement learning (RL), built around the novel class of sparse Gaussian mixture model Q-functions (S-GMM-QFs). Extending earlier work that trained GMM-QFs offline, the proposed framework develops an online scheme that leverages streaming data to encourage exploration. Model complexity is regulated through sparsification by Hadamard overparametrization, which mitigates overfitting while preserving expressiveness. The parameter space of S-GMM-QFs is naturally endowed with a Riemannian manifold structure, allowing for principled parameter updates via online gradient descent on a smooth objective. Numerical tests show that S-GMM-QFs match the performance of dense deep RL (DeepRL) methods on standard benchmarks while using significantly fewer parameters, and maintain strong performance even in low-parameter-count regimes where sparsified DeepRL methods fail to generalize.
Nonparametric Bellman Mappings for Value Iteration in Distributed Reinforcement Learning
Mar 20, 2025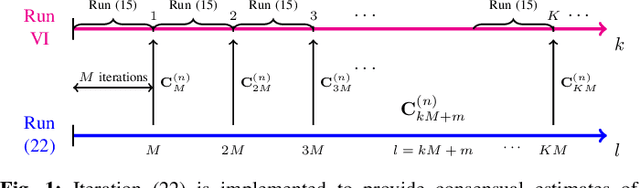
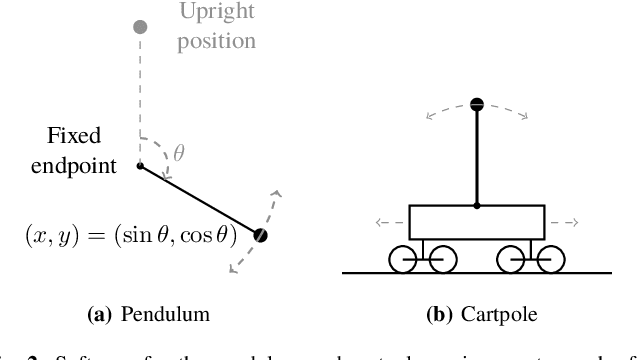
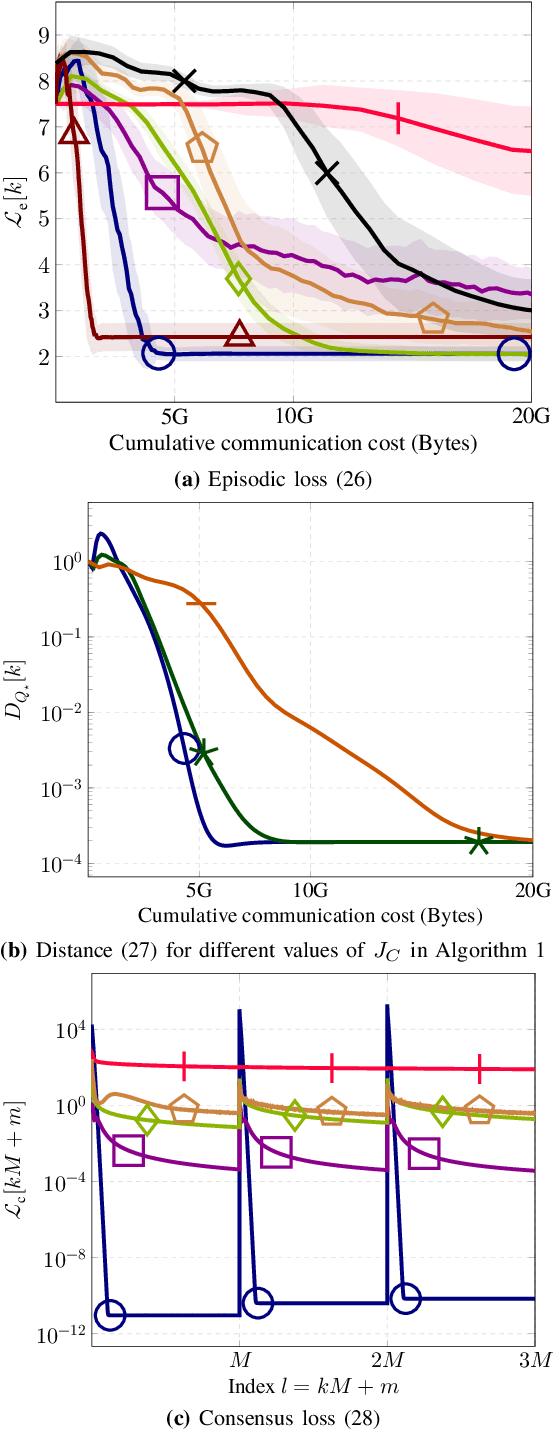
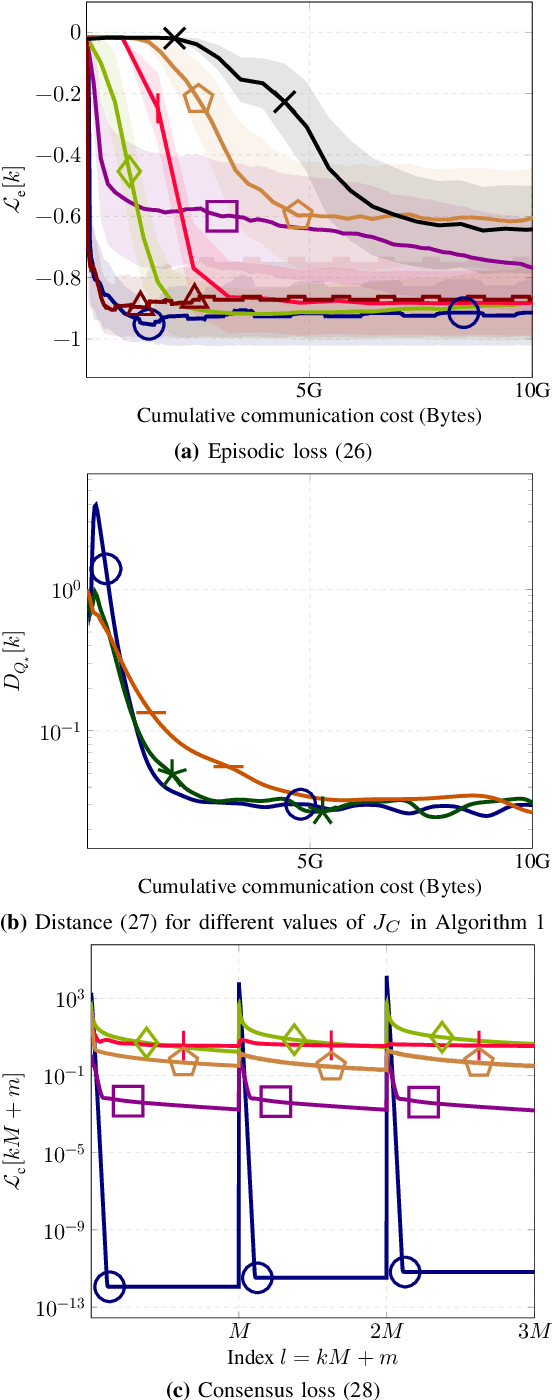
This paper introduces novel Bellman mappings (B-Maps) for value iteration (VI) in distributed reinforcement learning (DRL), where multiple agents operate over a network without a centralized fusion node. Each agent constructs its own nonparametric B-Map for VI while communicating only with direct neighbors to achieve consensus. These B-Maps operate on Q-functions represented in a reproducing kernel Hilbert space, enabling a nonparametric formulation that allows for flexible, agent-specific basis function design. Unlike existing DRL methods that restrict information exchange to Q-function estimates, the proposed framework also enables agents to share basis information in the form of covariance matrices, capturing additional structural details. A theoretical analysis establishes linear convergence rates for both Q-function and covariance-matrix estimates toward their consensus values. The optimal learning rates for consensus-based updates are dictated by the ratio of the smallest positive eigenvalue to the largest one of the network's Laplacian matrix. Furthermore, each nodal Q-function estimate is shown to lie very close to the fixed point of a centralized nonparametric B-Map, effectively allowing the proposed DRL design to approximate the performance of a centralized fusion center. Numerical experiments on two well-known control problems demonstrate the superior performance of the proposed nonparametric B-Maps compared to prior methods. Notably, the results reveal a counter-intuitive finding: although the proposed approach involves greater information exchange -- specifically through the sharing of covariance matrices -- it achieves the desired performance with lower cumulative communication cost than existing DRL schemes, highlighting the crucial role of basis information in accelerating the learning process.
Model-Free Adversarial Purification via Coarse-To-Fine Tensor Network Representation
Feb 25, 2025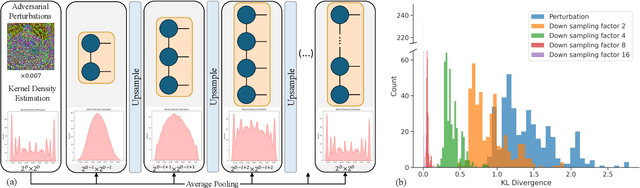
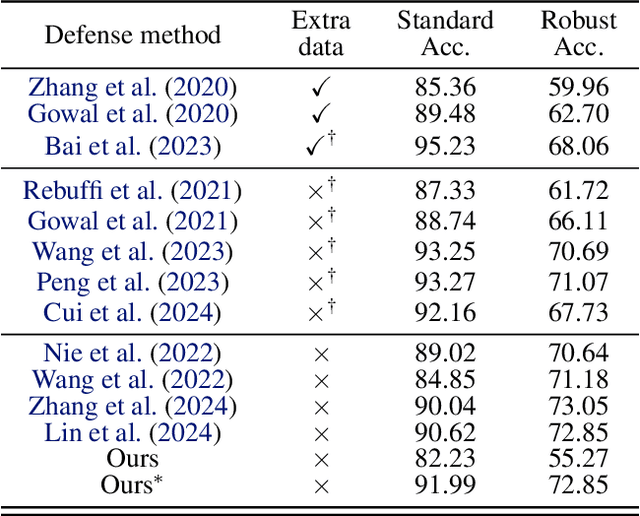
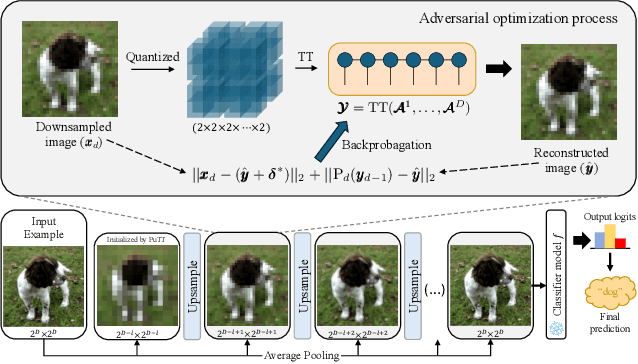
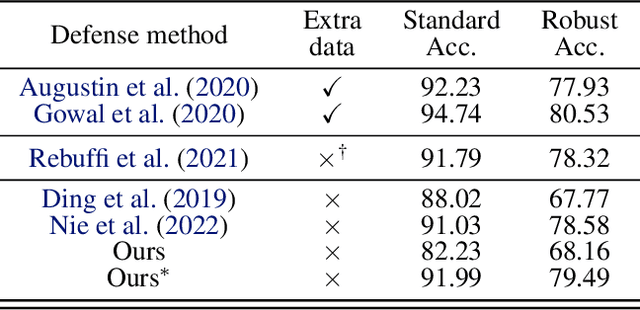
Deep neural networks are known to be vulnerable to well-designed adversarial attacks. Although numerous defense strategies have been proposed, many are tailored to the specific attacks or tasks and often fail to generalize across diverse scenarios. In this paper, we propose Tensor Network Purification (TNP), a novel model-free adversarial purification method by a specially designed tensor network decomposition algorithm. TNP depends neither on the pre-trained generative model nor the specific dataset, resulting in strong robustness across diverse adversarial scenarios. To this end, the key challenge lies in relaxing Gaussian-noise assumptions of classical decompositions and accommodating the unknown distribution of adversarial perturbations. Unlike the low-rank representation of classical decompositions, TNP aims to reconstruct the unobserved clean examples from an adversarial example. Specifically, TNP leverages progressive downsampling and introduces a novel adversarial optimization objective to address the challenge of minimizing reconstruction error but without inadvertently restoring adversarial perturbations. Extensive experiments conducted on CIFAR-10, CIFAR-100, and ImageNet demonstrate that our method generalizes effectively across various norm threats, attack types, and tasks, providing a versatile and promising adversarial purification technique.
Gaussian-Mixture-Model Q-Functions for Reinforcement Learning by Riemannian Optimization
Sep 10, 2024This paper establishes a novel role for Gaussian-mixture models (GMMs) as functional approximators of Q-function losses in reinforcement learning (RL). Unlike the existing RL literature, where GMMs play their typical role as estimates of probability density functions, GMMs approximate here Q-function losses. The new Q-function approximators, coined GMM-QFs, are incorporated in Bellman residuals to promote a Riemannian-optimization task as a novel policy-evaluation step in standard policy-iteration schemes. The paper demonstrates how the hyperparameters (means and covariance matrices) of the Gaussian kernels are learned from the data, opening thus the door of RL to the powerful toolbox of Riemannian optimization. Numerical tests show that with no use of experienced data, the proposed design outperforms state-of-the-art methods, even deep Q-networks which use experienced data, on benchmark RL tasks.
Imputation of Time-varying Edge Flows in Graphs by Multilinear Kernel Regression and Manifold Learning
Sep 08, 2024
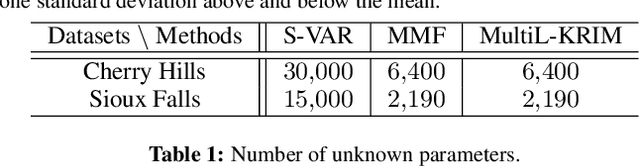
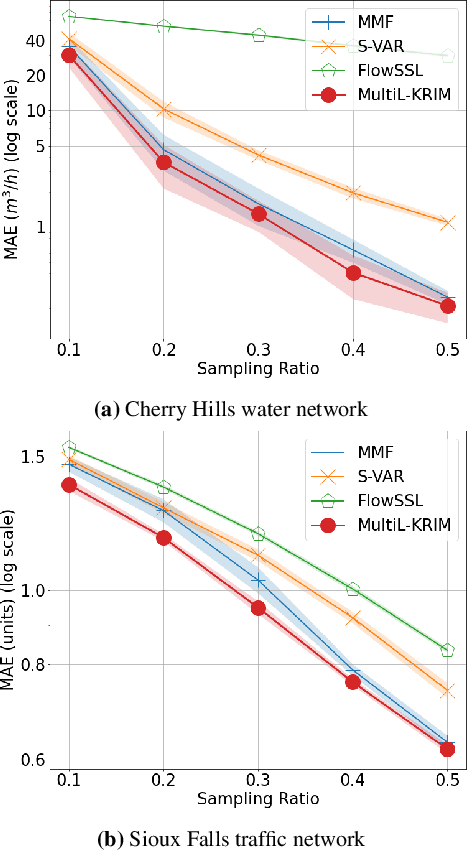
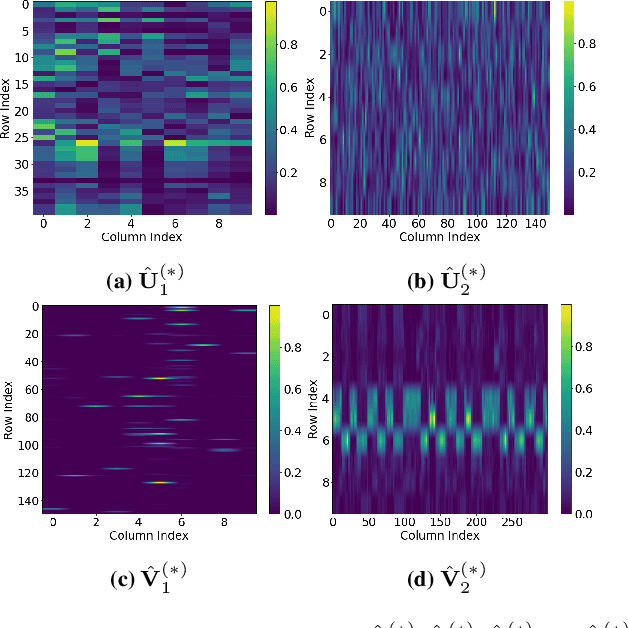
This paper extends the recently developed framework of multilinear kernel regression and imputation via manifold learning (MultiL-KRIM) to impute time-varying edge flows in a graph. MultiL-KRIM uses simplicial-complex arguments and Hodge Laplacians to incorporate the graph topology, and exploits manifold-learning arguments to identify latent geometries within features which are modeled as a point-cloud around a smooth manifold embedded in a reproducing kernel Hilbert space (RKHS). Following the concept of tangent spaces to smooth manifolds, linear approximating patches are used to add a collaborative-filtering flavor to the point-cloud approximations. Together with matrix factorizations, MultiL-KRIM effects dimensionality reduction, and enables efficient computations, without any training data or additional information. Numerical tests on real-network time-varying edge flows demonstrate noticeable improvements of MultiL-KRIM over several state-of-the-art schemes.
Nonparametric Bellman Mappings for Reinforcement Learning: Application to Robust Adaptive Filtering
Mar 29, 2024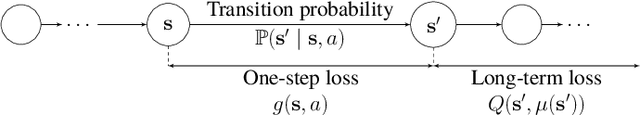
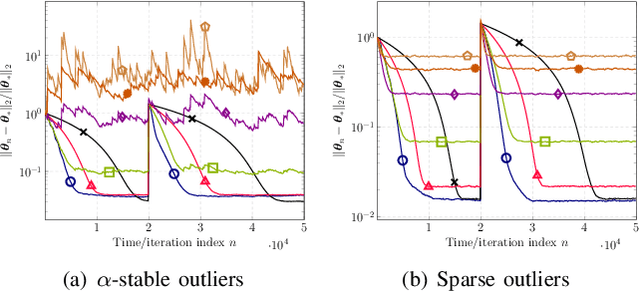
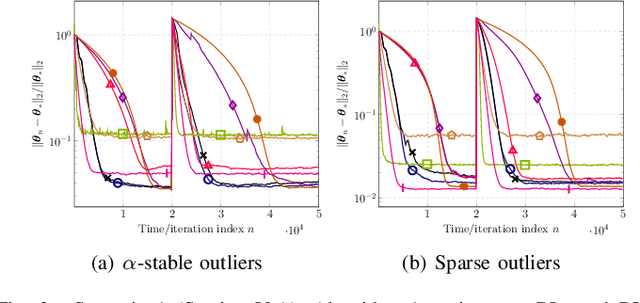
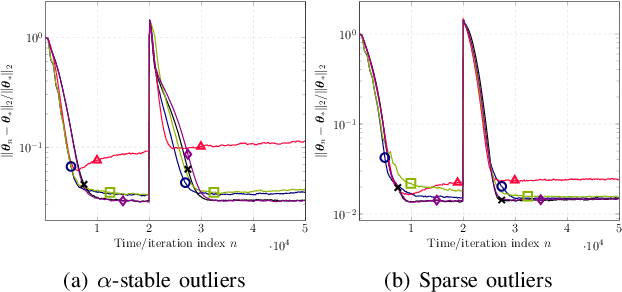
This paper designs novel nonparametric Bellman mappings in reproducing kernel Hilbert spaces (RKHSs) for reinforcement learning (RL). The proposed mappings benefit from the rich approximating properties of RKHSs, adopt no assumptions on the statistics of the data owing to their nonparametric nature, require no knowledge on transition probabilities of Markov decision processes, and may operate without any training data. Moreover, they allow for sampling on-the-fly via the design of trajectory samples, re-use past test data via experience replay, effect dimensionality reduction by random Fourier features, and enable computationally lightweight operations to fit into efficient online or time-adaptive learning. The paper offers also a variational framework to design the free parameters of the proposed Bellman mappings, and shows that appropriate choices of those parameters yield several popular Bellman-mapping designs. As an application, the proposed mappings are employed to offer a novel solution to the problem of countering outliers in adaptive filtering. More specifically, with no prior information on the statistics of the outliers and no training data, a policy-iteration algorithm is introduced to select online, per time instance, the ``optimal'' coefficient p in the least-mean-p-power-error method. Numerical tests on synthetic data showcase, in most of the cases, the superior performance of the proposed solution over several RL and non-RL schemes.