 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNonparametric Bellman Mappings for Value Iteration in Distributed Reinforcement Learning
Mar 20, 2025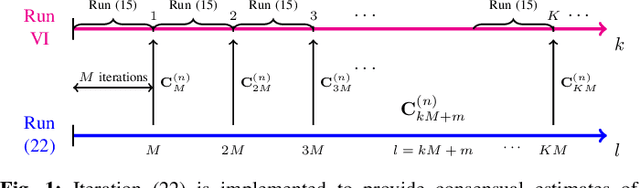
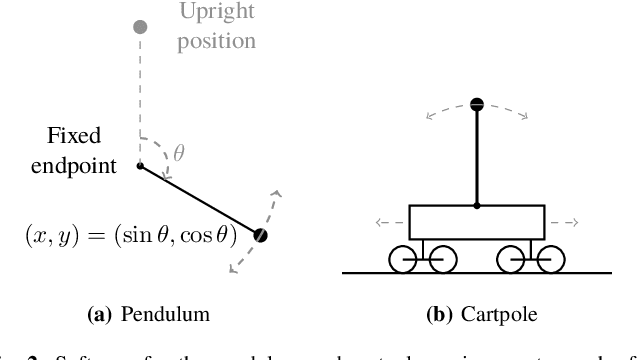
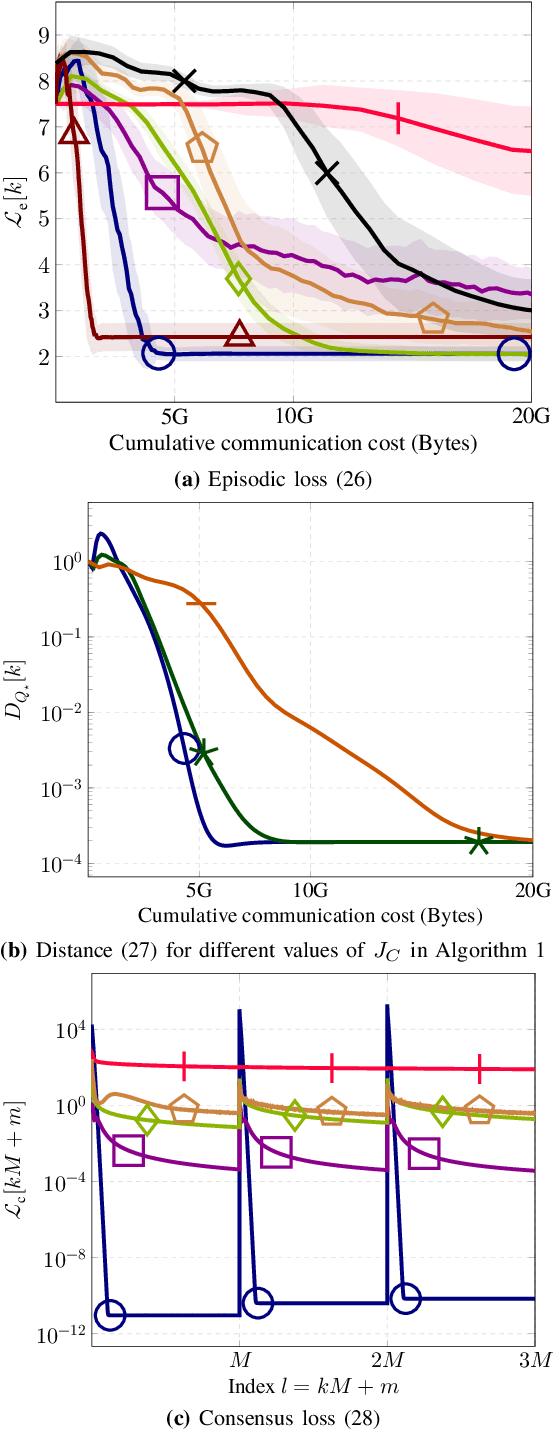
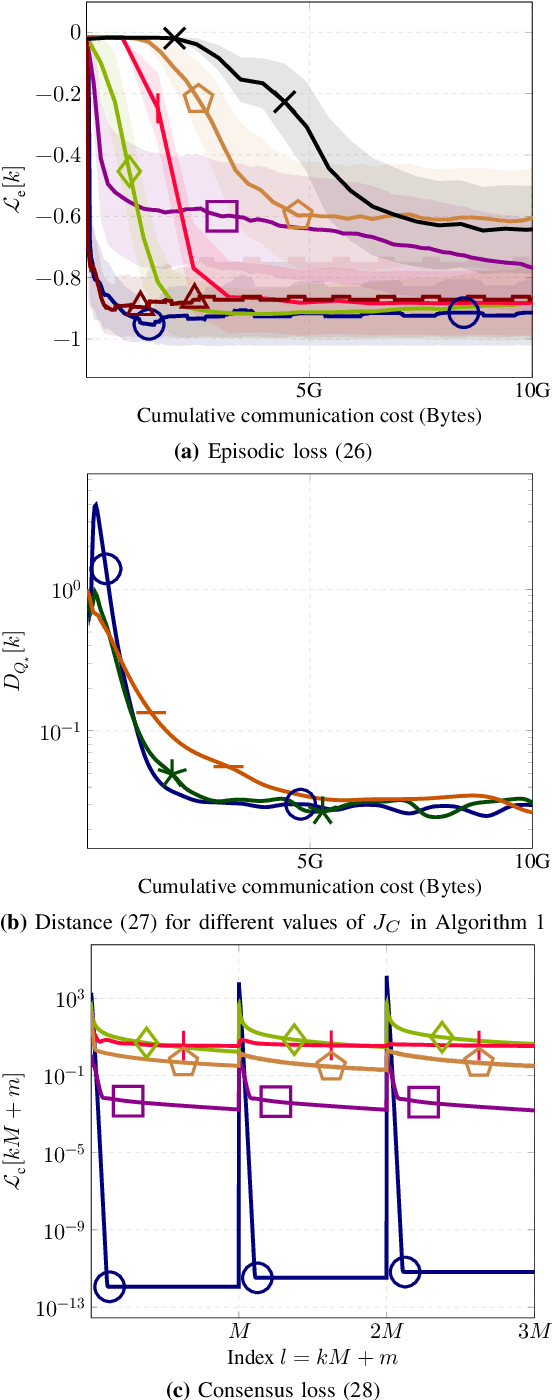
This paper introduces novel Bellman mappings (B-Maps) for value iteration (VI) in distributed reinforcement learning (DRL), where multiple agents operate over a network without a centralized fusion node. Each agent constructs its own nonparametric B-Map for VI while communicating only with direct neighbors to achieve consensus. These B-Maps operate on Q-functions represented in a reproducing kernel Hilbert space, enabling a nonparametric formulation that allows for flexible, agent-specific basis function design. Unlike existing DRL methods that restrict information exchange to Q-function estimates, the proposed framework also enables agents to share basis information in the form of covariance matrices, capturing additional structural details. A theoretical analysis establishes linear convergence rates for both Q-function and covariance-matrix estimates toward their consensus values. The optimal learning rates for consensus-based updates are dictated by the ratio of the smallest positive eigenvalue to the largest one of the network's Laplacian matrix. Furthermore, each nodal Q-function estimate is shown to lie very close to the fixed point of a centralized nonparametric B-Map, effectively allowing the proposed DRL design to approximate the performance of a centralized fusion center. Numerical experiments on two well-known control problems demonstrate the superior performance of the proposed nonparametric B-Maps compared to prior methods. Notably, the results reveal a counter-intuitive finding: although the proposed approach involves greater information exchange -- specifically through the sharing of covariance matrices -- it achieves the desired performance with lower cumulative communication cost than existing DRL schemes, highlighting the crucial role of basis information in accelerating the learning process.
Nonparametric Bellman Mappings for Reinforcement Learning: Application to Robust Adaptive Filtering
Mar 29, 2024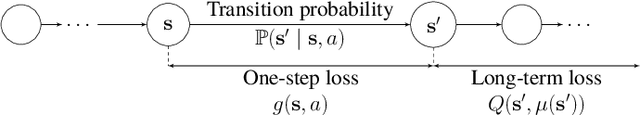
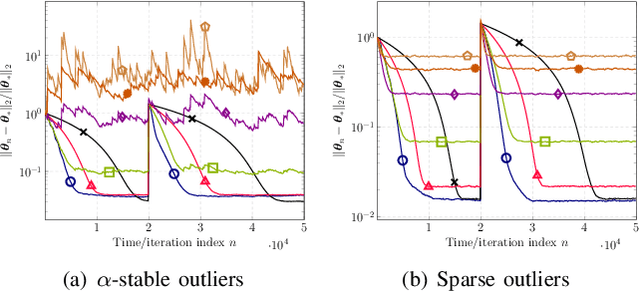
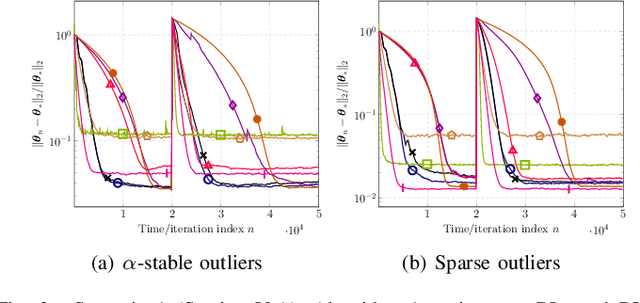
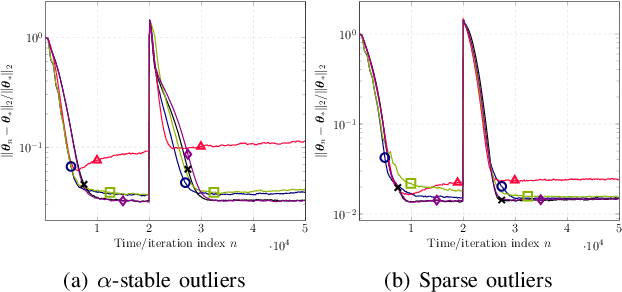
This paper designs novel nonparametric Bellman mappings in reproducing kernel Hilbert spaces (RKHSs) for reinforcement learning (RL). The proposed mappings benefit from the rich approximating properties of RKHSs, adopt no assumptions on the statistics of the data owing to their nonparametric nature, require no knowledge on transition probabilities of Markov decision processes, and may operate without any training data. Moreover, they allow for sampling on-the-fly via the design of trajectory samples, re-use past test data via experience replay, effect dimensionality reduction by random Fourier features, and enable computationally lightweight operations to fit into efficient online or time-adaptive learning. The paper offers also a variational framework to design the free parameters of the proposed Bellman mappings, and shows that appropriate choices of those parameters yield several popular Bellman-mapping designs. As an application, the proposed mappings are employed to offer a novel solution to the problem of countering outliers in adaptive filtering. More specifically, with no prior information on the statistics of the outliers and no training data, a policy-iteration algorithm is introduced to select online, per time instance, the ``optimal'' coefficient p in the least-mean-p-power-error method. Numerical tests on synthetic data showcase, in most of the cases, the superior performance of the proposed solution over several RL and non-RL schemes.
Proximal Bellman mappings for reinforcement learning and their application to robust adaptive filtering
Sep 14, 2023


This paper aims at the algorithmic/theoretical core of reinforcement learning (RL) by introducing the novel class of proximal Bellman mappings. These mappings are defined in reproducing kernel Hilbert spaces (RKHSs), to benefit from the rich approximation properties and inner product of RKHSs, they are shown to belong to the powerful Hilbertian family of (firmly) nonexpansive mappings, regardless of the values of their discount factors, and possess ample degrees of design freedom to even reproduce attributes of the classical Bellman mappings and to pave the way for novel RL designs. An approximate policy-iteration scheme is built on the proposed class of mappings to solve the problem of selecting online, at every time instance, the "optimal" exponent $p$ in a $p$-norm loss to combat outliers in linear adaptive filtering, without training data and any knowledge on the statistical properties of the outliers. Numerical tests on synthetic data showcase the superior performance of the proposed framework over several non-RL and kernel-based RL schemes.
Dynamic selection of p-norm in linear adaptive filtering via online kernel-based reinforcement learning
Oct 20, 2022

This study addresses the problem of selecting dynamically, at each time instance, the ``optimal'' p-norm to combat outliers in linear adaptive filtering without any knowledge on the potentially time-varying probability distribution function of the outliers. To this end, an online and data-driven framework is designed via kernel-based reinforcement learning (KBRL). Novel Bellman mappings on reproducing kernel Hilbert spaces (RKHSs) are introduced that need no knowledge on transition probabilities of Markov decision processes, and are nonexpansive with respect to the underlying Hilbertian norm. An approximate policy-iteration framework is finally offered via the introduction of a finite-dimensional affine superset of the fixed-point set of the proposed Bellman mappings. The well-known ``curse of dimensionality'' in RKHSs is addressed by building a basis of vectors via an approximate linear dependency criterion. Numerical tests on synthetic data demonstrate that the proposed framework selects always the ``optimal'' p-norm for the outlier scenario at hand, outperforming at the same time several non-RL and KBRL schemes.