 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePatch-wise Features for Blur Image Classification
Apr 06, 2023



Images captured through smartphone cameras often suffer from degradation, blur being one of the major ones, posing a challenge in processing these images for downstream tasks. In this paper we propose low-compute lightweight patch-wise features for image quality assessment. Using our method we can discriminate between blur vs sharp image degradation. To this end, we train a decision-tree based XGBoost model on various intuitive image features like gray level variance, first and second order gradients, texture features like local binary patterns. Experiments conducted on an open dataset show that the proposed low compute method results in 90.1% mean accuracy on the validation set, which is comparable to the accuracy of a compute-intensive VGG16 network with 94% mean accuracy fine-tuned to this task. To demonstrate the generalizability of our proposed features and model we test the model on BHBID dataset and an internal dataset where we attain accuracy of 98% and 91%, respectively. The proposed method is 10x faster than the VGG16 based model on CPU and scales linearly to the input image size making it suitable to be implemented on low compute edge devices.
Multi-class Text Classification using BERT-based Active Learning
Apr 27, 2021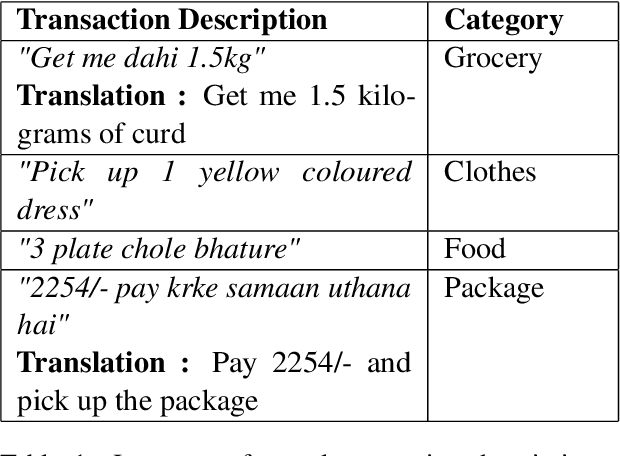
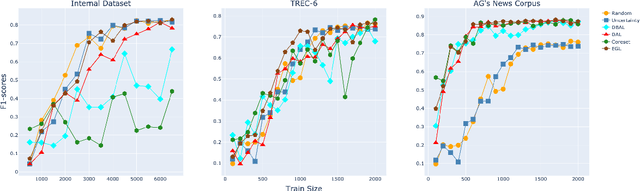
Text Classification finds interesting applications in the pickup and delivery services industry where customers require one or more items to be picked up from a location and delivered to a certain destination. Classifying these customer transactions into multiple categories helps understand the market needs for different customer segments. Each transaction is accompanied by a text description provided by the customer to describe the products being picked up and delivered which can be used to classify the transaction. BERT-based models have proven to perform well in Natural Language Understanding. However, the product descriptions provided by the customers tend to be short, incoherent and code-mixed (Hindi-English) text which demands fine-tuning of such models with manually labelled data to achieve high accuracy. Collecting this labelled data can prove to be expensive. In this paper, we explore Active Learning strategies to label transaction descriptions cost effectively while using BERT to train a transaction classification model. On TREC-6, AG's News Corpus and an internal dataset, we benchmark the performance of BERT across different Active Learning strategies in Multi-Class Text Classification.
Unsupervised Contextual Paraphrase Generation using Lexical Control and Reinforcement Learning
Mar 23, 2021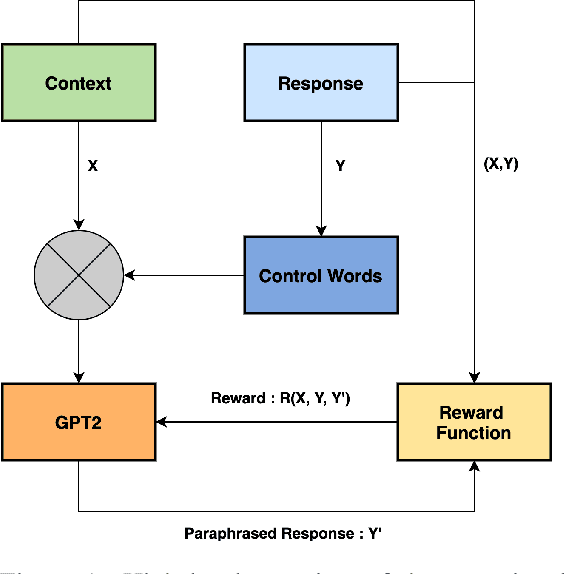



Customer support via chat requires agents to resolve customer queries with minimum wait time and maximum customer satisfaction. Given that the agents as well as the customers can have varying levels of literacy, the overall quality of responses provided by the agents tend to be poor if they are not predefined. But using only static responses can lead to customer detraction as the customers tend to feel that they are no longer interacting with a human. Hence, it is vital to have variations of the static responses to reduce monotonicity of the responses. However, maintaining a list of such variations can be expensive. Given the conversation context and the agent response, we propose an unsupervised frame-work to generate contextual paraphrases using autoregressive models. We also propose an automated metric based on Semantic Similarity, Textual Entailment, Expression Diversity and Fluency to evaluate the quality of contextual paraphrases and demonstrate performance improvement with Reinforcement Learning (RL) fine-tuning using the automated metric as the reward function.
Exploiting Spectral Augmentation for Code-Switched Spoken Language Identification
Oct 14, 2020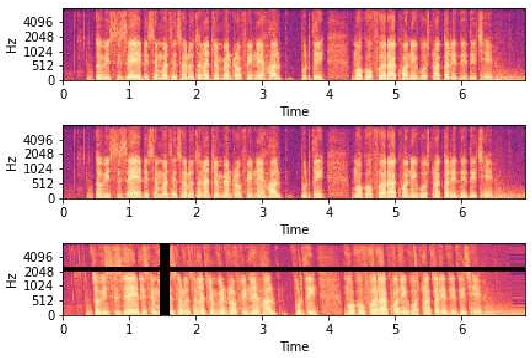
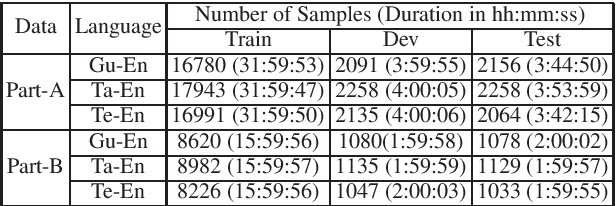
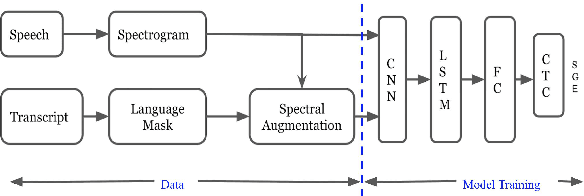
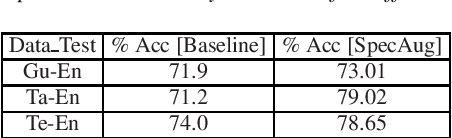
Spoken language Identification (LID) systems are needed to identify the language(s) present in a given audio sample, and typically could be the first step in many speech processing related tasks such as automatic speech recognition (ASR). Automatic identification of the languages present in a speech signal is not only scientifically interesting, but also of practical importance in a multilingual country such as India. In many of the Indian cities, when people interact with each other, as many as three languages may get mixed. These may include the official language of that province, Hindi and English (at times the languages of the neighboring provinces may also get mixed during these interactions). This makes the spoken LID task extremely challenging in Indian context. While quite a few LID systems in the context of Indian languages have been implemented, most such systems have used small scale speech data collected internally within an organization. In the current work, we perform spoken LID on three Indian languages (Gujarati, Telugu, and Tamil) code-mixed with English. This task was organized by the Microsoft research team as a spoken LID challenge. In our work, we modify the usual spectral augmentation approach and propose a language mask that discriminates the language ID pairs, which leads to a noise robust spoken LID system. The proposed method gives a relative improvement of approximately 3-5% in the LID accuracy over a baseline system proposed by Microsoft on the three language pairs for two shared tasks suggested in the challenge.