 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Robustness of Linear Classifiers to Targeted Data Poisoning
Nov 16, 2025
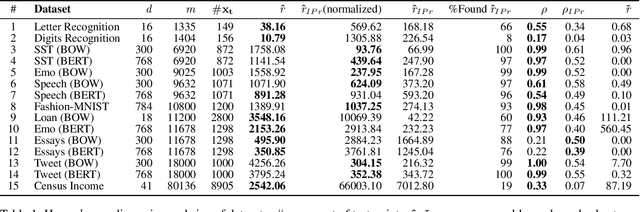
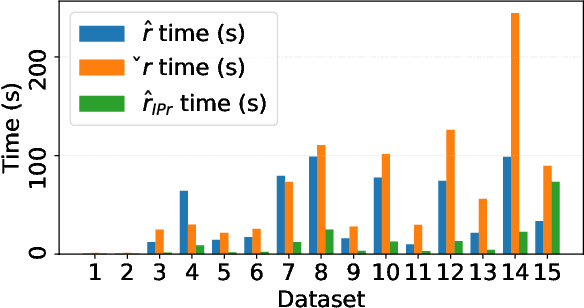
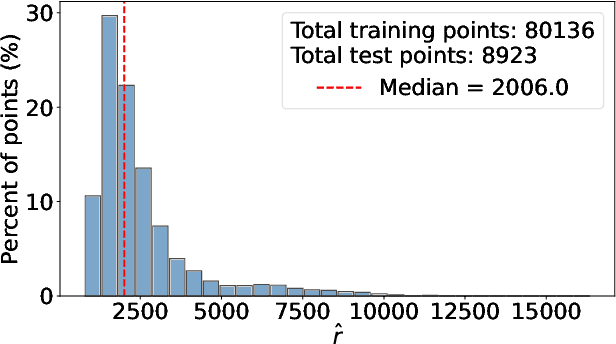
Data poisoning is a training-time attack that undermines the trustworthiness of learned models. In a targeted data poisoning attack, an adversary manipulates the training dataset to alter the classification of a targeted test point. Given the typically large size of training dataset, manual detection of poisoning is difficult. An alternative is to automatically measure a dataset's robustness against such an attack, which is the focus of this paper. We consider a threat model wherein an adversary can only perturb the labels of the training dataset, with knowledge limited to the hypothesis space of the victim's model. In this setting, we prove that finding the robustness is an NP-Complete problem, even when hypotheses are linear classifiers. To overcome this, we present a technique that finds lower and upper bounds of robustness. Our implementation of the technique computes these bounds efficiently in practice for many publicly available datasets. We experimentally demonstrate the effectiveness of our approach. Specifically, a poisoning exceeding the identified robustness bounds significantly impacts test point classification. We are also able to compute these bounds in many more cases where state-of-the-art techniques fail.
PEDAL: Enhancing Greedy Decoding with Large Language Models using Diverse Exemplars
Aug 16, 2024
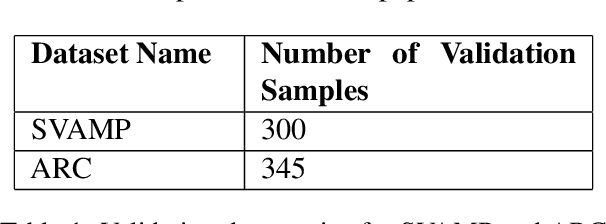
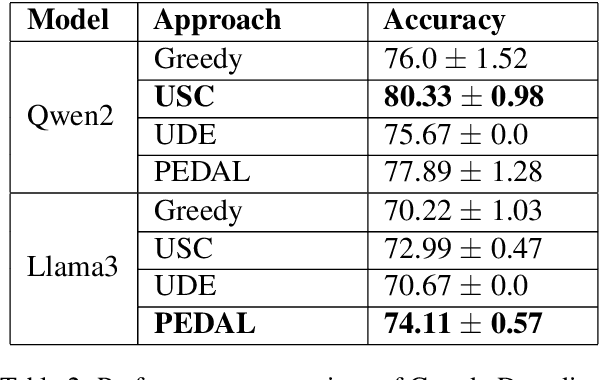
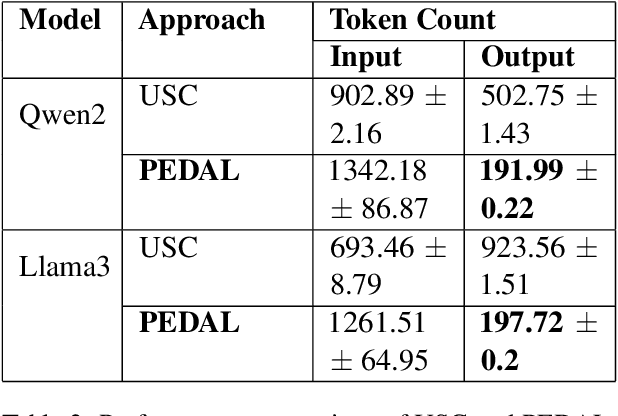
Self-ensembling techniques with diverse reasoning paths such as Self-Consistency have demonstrated remarkable gains in accuracy for Large Language Models (LLMs). However, such techniques depend on the availability of an accurate answer extraction process to aggregate across multiple outputs. Moreover, they acquire higher inference cost, in comparison to Greedy Decoding, due to generation of relatively higher number of output tokens. Research has shown that the free form text outputs from Self-Consistency can be aggregated reliably using LLMs to produce the final output. Additionally, recent advancements in LLM inference have demonstrated that usage of diverse exemplars in prompts have the ability to induce diversity in the LLM outputs. Such proven techniques can be easily extended to self-ensembling based approaches to achieve enhanced results in text generation. In this paper, we introduce PEDAL (Prompts based on Exemplar Diversity Aggregated using LLMs), a hybrid self-ensembling approach, that combines the strengths of diverse exemplar based prompts and LLM based aggregation to achieve improvement in overall performance. On the publicly available SVAMP and ARC datasets, our experiments reveal that PEDAL can achieve better accuracy than Greedy Decoding based strategies with lower inference cost compared to Self Consistency based approaches.
Multi-class Text Classification using BERT-based Active Learning
Apr 27, 2021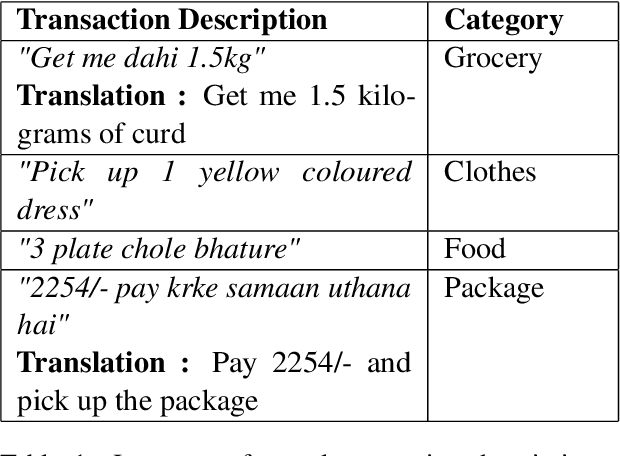
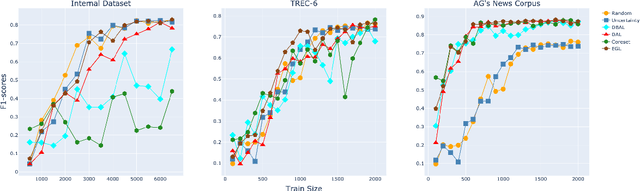
Text Classification finds interesting applications in the pickup and delivery services industry where customers require one or more items to be picked up from a location and delivered to a certain destination. Classifying these customer transactions into multiple categories helps understand the market needs for different customer segments. Each transaction is accompanied by a text description provided by the customer to describe the products being picked up and delivered which can be used to classify the transaction. BERT-based models have proven to perform well in Natural Language Understanding. However, the product descriptions provided by the customers tend to be short, incoherent and code-mixed (Hindi-English) text which demands fine-tuning of such models with manually labelled data to achieve high accuracy. Collecting this labelled data can prove to be expensive. In this paper, we explore Active Learning strategies to label transaction descriptions cost effectively while using BERT to train a transaction classification model. On TREC-6, AG's News Corpus and an internal dataset, we benchmark the performance of BERT across different Active Learning strategies in Multi-Class Text Classification.
Unsupervised Contextual Paraphrase Generation using Lexical Control and Reinforcement Learning
Mar 23, 2021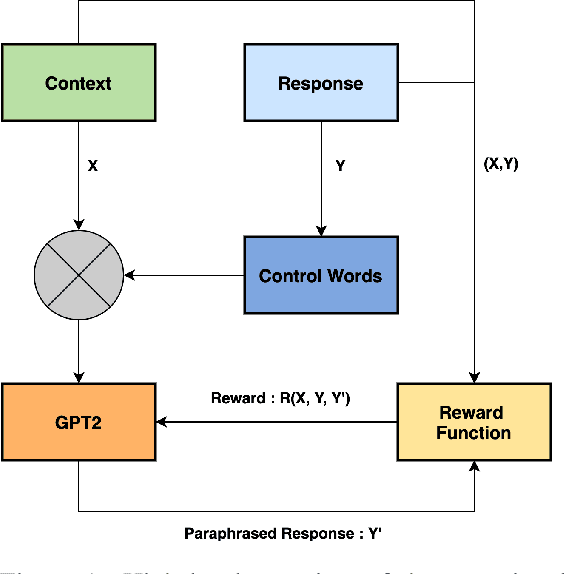



Customer support via chat requires agents to resolve customer queries with minimum wait time and maximum customer satisfaction. Given that the agents as well as the customers can have varying levels of literacy, the overall quality of responses provided by the agents tend to be poor if they are not predefined. But using only static responses can lead to customer detraction as the customers tend to feel that they are no longer interacting with a human. Hence, it is vital to have variations of the static responses to reduce monotonicity of the responses. However, maintaining a list of such variations can be expensive. Given the conversation context and the agent response, we propose an unsupervised frame-work to generate contextual paraphrases using autoregressive models. We also propose an automated metric based on Semantic Similarity, Textual Entailment, Expression Diversity and Fluency to evaluate the quality of contextual paraphrases and demonstrate performance improvement with Reinforcement Learning (RL) fine-tuning using the automated metric as the reward function.