 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting Spectral Augmentation for Code-Switched Spoken Language Identification
Oct 14, 2020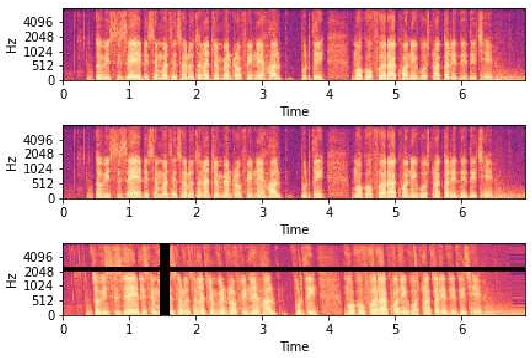
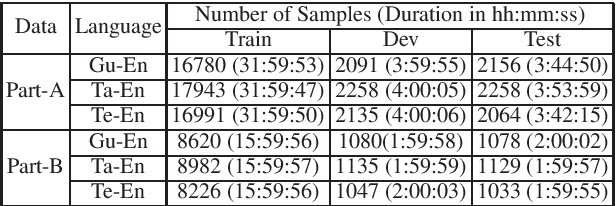
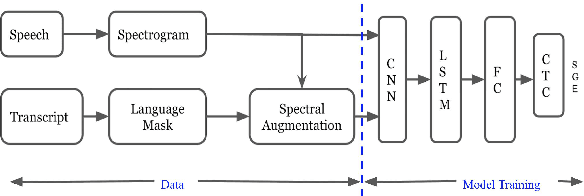
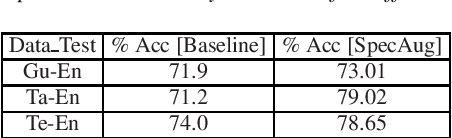
Spoken language Identification (LID) systems are needed to identify the language(s) present in a given audio sample, and typically could be the first step in many speech processing related tasks such as automatic speech recognition (ASR). Automatic identification of the languages present in a speech signal is not only scientifically interesting, but also of practical importance in a multilingual country such as India. In many of the Indian cities, when people interact with each other, as many as three languages may get mixed. These may include the official language of that province, Hindi and English (at times the languages of the neighboring provinces may also get mixed during these interactions). This makes the spoken LID task extremely challenging in Indian context. While quite a few LID systems in the context of Indian languages have been implemented, most such systems have used small scale speech data collected internally within an organization. In the current work, we perform spoken LID on three Indian languages (Gujarati, Telugu, and Tamil) code-mixed with English. This task was organized by the Microsoft research team as a spoken LID challenge. In our work, we modify the usual spectral augmentation approach and propose a language mask that discriminates the language ID pairs, which leads to a noise robust spoken LID system. The proposed method gives a relative improvement of approximately 3-5% in the LID accuracy over a baseline system proposed by Microsoft on the three language pairs for two shared tasks suggested in the challenge.
Beam Search Decoding using Manner of Articulation Detection Knowledge Derived from Connectionist Temporal Classification
Nov 16, 2018

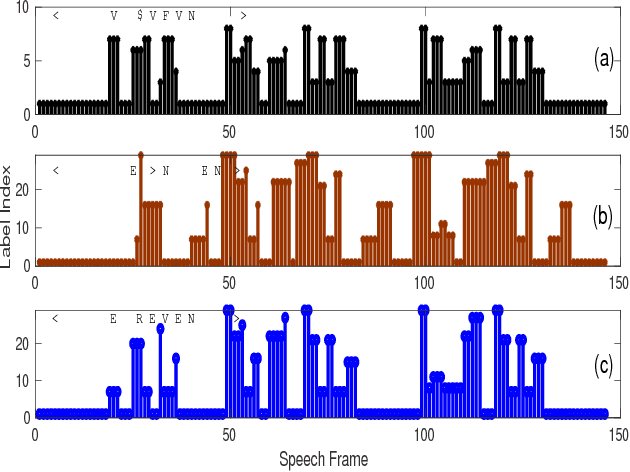

Manner of articulation detection using deep neural networks require a priori knowledge of the attribute discriminative features or the decent phoneme alignments. However generating an appropriate phoneme alignment is complex and its performance depends on the choice of optimal number of senones, Gaussians, etc. In the first part of our work, we exploit the manner of articulation detection using connectionist temporal classification (CTC) which doesn't need any phoneme alignment. Later we modify the state-of-the-art character based posteriors generated by CTC using the manner of articulation CTC detector. Beam search decoding is performed on the modified posteriors and it's impact on open source datasets such as AN4 and LibriSpeech is observed.