 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHostility Detection and Covid-19 Fake News Detection in Social Media
Jan 15, 2021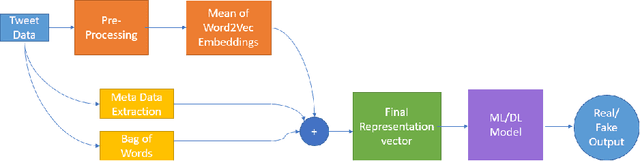
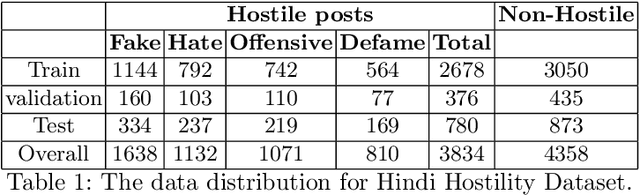

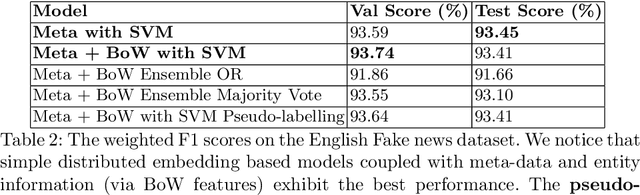
Withtheadventofsocialmedia,therehasbeenanextremely rapid increase in the content shared online. Consequently, the propagation of fake news and hostile messages on social media platforms has also skyrocketed. In this paper, we address the problem of detecting hostile and fake content in the Devanagari (Hindi) script as a multi-class, multi-label problem. Using NLP techniques, we build a model that makes use of an abusive language detector coupled with features extracted via Hindi BERT and Hindi FastText models and metadata. Our model achieves a 0.97 F1 score on coarse grain evaluation on Hostility detection task. Additionally, we built models to identify fake news related to Covid-19 in English tweets. We leverage entity information extracted from the tweets along with textual representations learned from word embeddings and achieve a 0.93 F1 score on the English fake news detection task.
Two Stage Transformer Model for COVID-19 Fake News Detection and Fact Checking
Nov 26, 2020

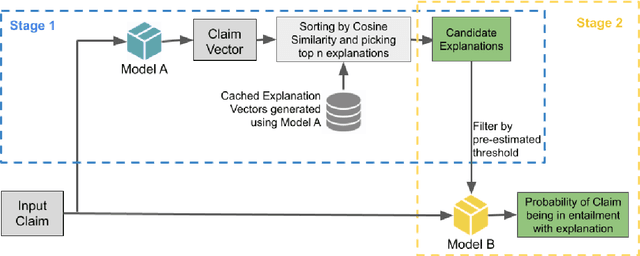
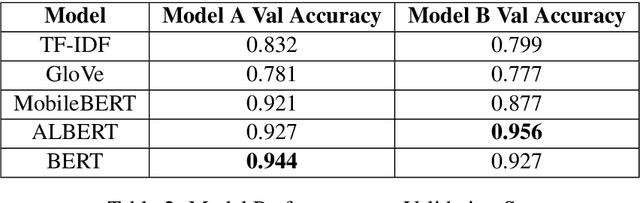
The rapid advancement of technology in online communication via social media platforms has led to a prolific rise in the spread of misinformation and fake news. Fake news is especially rampant in the current COVID-19 pandemic, leading to people believing in false and potentially harmful claims and stories. Detecting fake news quickly can alleviate the spread of panic, chaos and potential health hazards. We developed a two stage automated pipeline for COVID-19 fake news detection using state of the art machine learning models for natural language processing. The first model leverages a novel fact checking algorithm that retrieves the most relevant facts concerning user claims about particular COVID-19 claims. The second model verifies the level of truth in the claim by computing the textual entailment between the claim and the true facts retrieved from a manually curated COVID-19 dataset. The dataset is based on a publicly available knowledge source consisting of more than 5000 COVID-19 false claims and verified explanations, a subset of which was internally annotated and cross-validated to train and evaluate our models. We evaluate a series of models based on classical text-based features to more contextual Transformer based models and observe that a model pipeline based on BERT and ALBERT for the two stages respectively yields the best results.
Exploiting Spectral Augmentation for Code-Switched Spoken Language Identification
Oct 14, 2020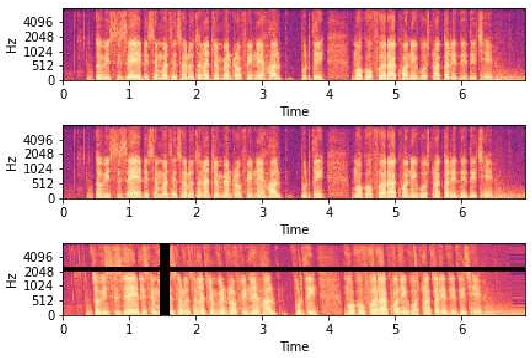
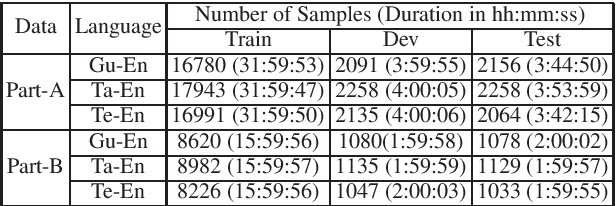
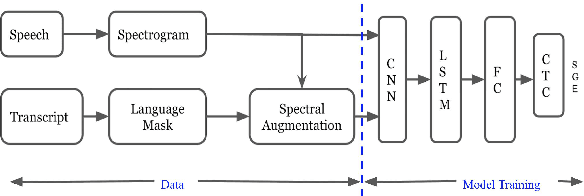
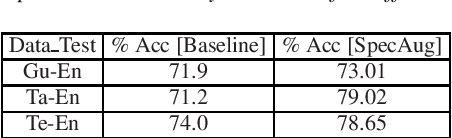
Spoken language Identification (LID) systems are needed to identify the language(s) present in a given audio sample, and typically could be the first step in many speech processing related tasks such as automatic speech recognition (ASR). Automatic identification of the languages present in a speech signal is not only scientifically interesting, but also of practical importance in a multilingual country such as India. In many of the Indian cities, when people interact with each other, as many as three languages may get mixed. These may include the official language of that province, Hindi and English (at times the languages of the neighboring provinces may also get mixed during these interactions). This makes the spoken LID task extremely challenging in Indian context. While quite a few LID systems in the context of Indian languages have been implemented, most such systems have used small scale speech data collected internally within an organization. In the current work, we perform spoken LID on three Indian languages (Gujarati, Telugu, and Tamil) code-mixed with English. This task was organized by the Microsoft research team as a spoken LID challenge. In our work, we modify the usual spectral augmentation approach and propose a language mask that discriminates the language ID pairs, which leads to a noise robust spoken LID system. The proposed method gives a relative improvement of approximately 3-5% in the LID accuracy over a baseline system proposed by Microsoft on the three language pairs for two shared tasks suggested in the challenge.