 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRB2: Robotic Manipulation Benchmarking with a Twist
Mar 15, 2022
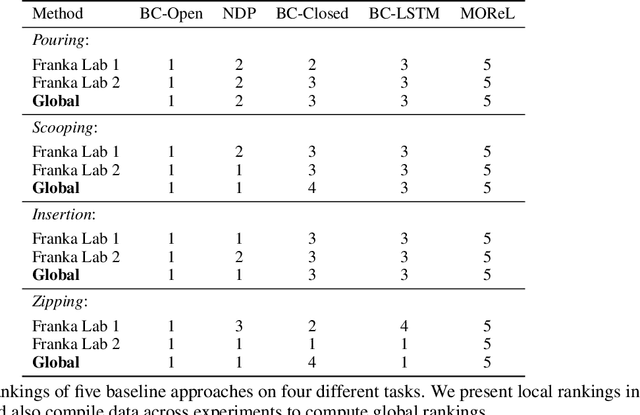

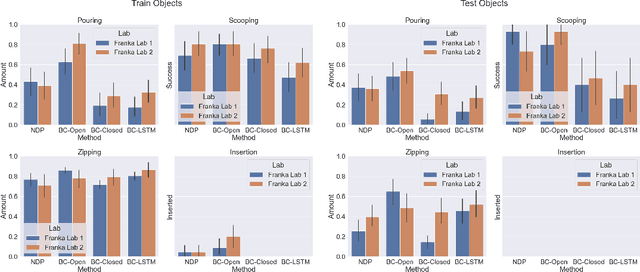
Benchmarks offer a scientific way to compare algorithms using objective performance metrics. Good benchmarks have two features: (a) they should be widely useful for many research groups; (b) and they should produce reproducible findings. In robotic manipulation research, there is a trade-off between reproducibility and broad accessibility. If the benchmark is kept restrictive (fixed hardware, objects), the numbers are reproducible but the setup becomes less general. On the other hand, a benchmark could be a loose set of protocols (e.g. object sets) but the underlying variation in setups make the results non-reproducible. In this paper, we re-imagine benchmarking for robotic manipulation as state-of-the-art algorithmic implementations, alongside the usual set of tasks and experimental protocols. The added baseline implementations will provide a way to easily recreate SOTA numbers in a new local robotic setup, thus providing credible relative rankings between existing approaches and new work. However, these local rankings could vary between different setups. To resolve this issue, we build a mechanism for pooling experimental data between labs, and thus we establish a single global ranking for existing (and proposed) SOTA algorithms. Our benchmark, called Ranking-Based Robotics Benchmark (RB2), is evaluated on tasks that are inspired from clinically validated Southampton Hand Assessment Procedures. Our benchmark was run across two different labs and reveals several surprising findings. For example, extremely simple baselines like open-loop behavior cloning, outperform more complicated models (e.g. closed loop, RNN, Offline-RL, etc.) that are preferred by the field. We hope our fellow researchers will use RB2 to improve their research's quality and rigor.
The State of Knowledge Distillation for Classification
Dec 20, 2019

We survey various knowledge distillation (KD) strategies for simple classification tasks and implement a set of techniques that claim state-of-the-art accuracy. Our experiments using standardized model architectures, fixed compute budgets, and consistent training schedules indicate that many of these distillation results are hard to reproduce. This is especially apparent with methods using some form of feature distillation. Further examination reveals a lack of generalizability where these techniques may only succeed for specific architectures and training settings. We observe that appropriately tuned classical distillation in combination with a data augmentation training scheme gives an orthogonal improvement over other techniques. We validate this approach and open-source our code.
Hydra: A Peer to Peer Distributed Training & Data Collection Framework
Nov 24, 2018The world needs diverse and unbiased data to train deep learning models. Currently data comes from a variety of sources that are unmoderated to a large extent. The outcomes of training neural networks with unverified data yields biased models with various strains of homophobia, sexism and racism. Another trend observed in the world of deep learning is the rise of distributed training. Although cloud companies provide high performance compute for training models in the form of GPU's connected with a low latency network, using these services comes at a high cost. We propose Hydra, a system that seeks to solve both of these problems in a novel manner by proposing a decentralized distributed framework which utilizes the substantial amount of idle compute of everyday electronic devices like smartphones and desktop computers for training and data collection purposes. Hydra couples a specialized distributed training framework on a network of these low powered devices with a reward scheme that incentivizes users to provide high quality data to unleash the compute capability on this training framework. Such a system has the ability to capture data from a wide variety of diverse sources which has been an issue in the current scenario of deep learning. Hydra brings in several new innovations in training on low powered devices including a fault tolerant version of the All Reduce algorithm. Furthermore we introduce a reinforcement learning policy to decide the size of training jobs on different machines on a heterogeneous cluster of devices with varying network latencies for Synchronous SGD. The novel thing about such a network is the ability of each machine to shut down and resume training capabilities at any point of time without restarting the overall training. To enable such an asynchronous behaviour we propose a communication framework inspired by the Bittorrent protocol and the Kademlia DHT.
A Hitchhiker's Guide On Distributed Training of Deep Neural Networks
Oct 28, 2018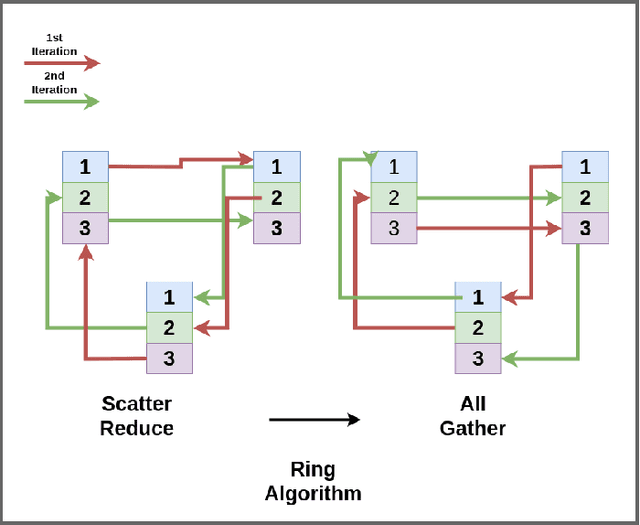
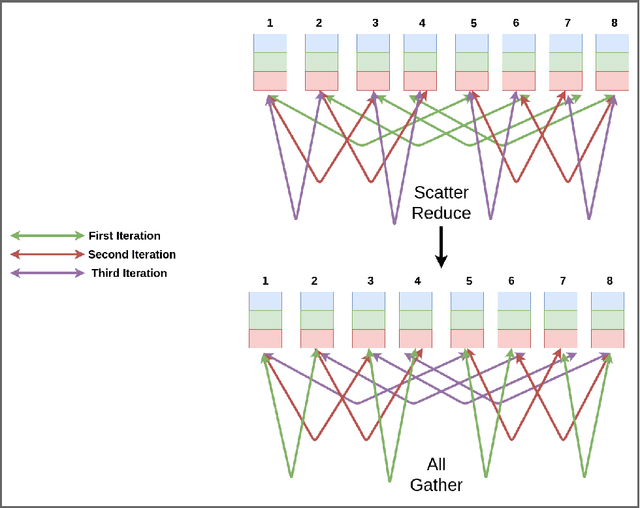
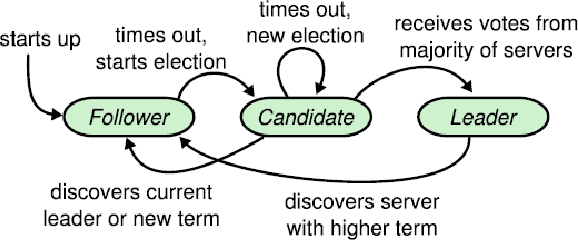
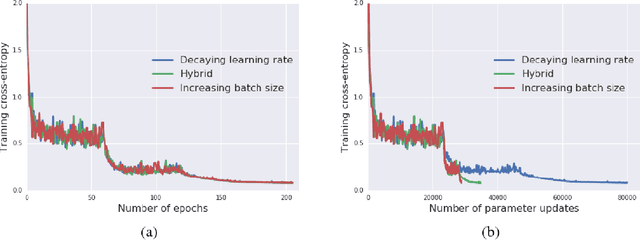
Deep learning has led to tremendous advancements in the field of Artificial Intelligence. One caveat however is the substantial amount of compute needed to train these deep learning models. Training a benchmark dataset like ImageNet on a single machine with a modern GPU can take upto a week, distributing training on multiple machines has been observed to drastically bring this time down. Recent work has brought down ImageNet training time to a time as low as 4 minutes by using a cluster of 2048 GPUs. This paper surveys the various algorithms and techniques used to distribute training and presents the current state of the art for a modern distributed training framework. More specifically, we explore the synchronous and asynchronous variants of distributed Stochastic Gradient Descent, various All Reduce gradient aggregation strategies and best practices for obtaining higher throughout and lower latency over a cluster such as mixed precision training, large batch training and gradient compression.