 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGemini Robotics: Bringing AI into the Physical World
Mar 25, 2025Recent advancements in large multimodal models have led to the emergence of remarkable generalist capabilities in digital domains, yet their translation to physical agents such as robots remains a significant challenge. This report introduces a new family of AI models purposefully designed for robotics and built upon the foundation of Gemini 2.0. We present Gemini Robotics, an advanced Vision-Language-Action (VLA) generalist model capable of directly controlling robots. Gemini Robotics executes smooth and reactive movements to tackle a wide range of complex manipulation tasks while also being robust to variations in object types and positions, handling unseen environments as well as following diverse, open vocabulary instructions. We show that with additional fine-tuning, Gemini Robotics can be specialized to new capabilities including solving long-horizon, highly dexterous tasks, learning new short-horizon tasks from as few as 100 demonstrations and adapting to completely novel robot embodiments. This is made possible because Gemini Robotics builds on top of the Gemini Robotics-ER model, the second model we introduce in this work. Gemini Robotics-ER (Embodied Reasoning) extends Gemini's multimodal reasoning capabilities into the physical world, with enhanced spatial and temporal understanding. This enables capabilities relevant to robotics including object detection, pointing, trajectory and grasp prediction, as well as multi-view correspondence and 3D bounding box predictions. We show how this novel combination can support a variety of robotics applications. We also discuss and address important safety considerations related to this new class of robotics foundation models. The Gemini Robotics family marks a substantial step towards developing general-purpose robots that realizes AI's potential in the physical world.
Proc4Gem: Foundation models for physical agency through procedural generation
Mar 11, 2025



In robot learning, it is common to either ignore the environment semantics, focusing on tasks like whole-body control which only require reasoning about robot-environment contacts, or conversely to ignore contact dynamics, focusing on grounding high-level movement in vision and language. In this work, we show that advances in generative modeling, photorealistic rendering, and procedural generation allow us to tackle tasks requiring both. By generating contact-rich trajectories with accurate physics in semantically-diverse simulations, we can distill behaviors into large multimodal models that directly transfer to the real world: a system we call Proc4Gem. Specifically, we show that a foundation model, Gemini, fine-tuned on only simulation data, can be instructed in language to control a quadruped robot to push an object with its body to unseen targets in unseen real-world environments. Our real-world results demonstrate the promise of using simulation to imbue foundation models with physical agency. Videos can be found at our website: https://sites.google.com/view/proc4gem
Speech Emotion Recognition Via CNN-Transforemr and Multidimensional Attention Mechanism
Mar 07, 2024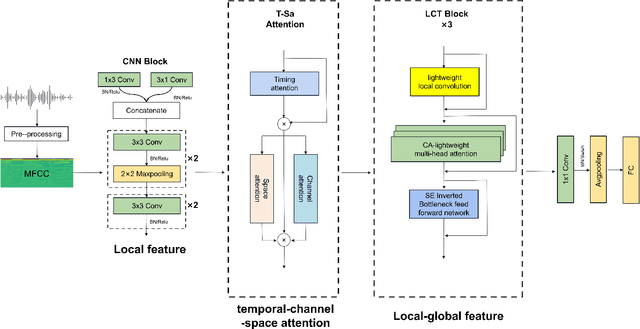
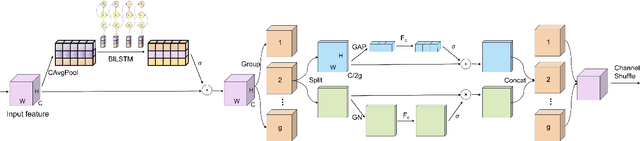
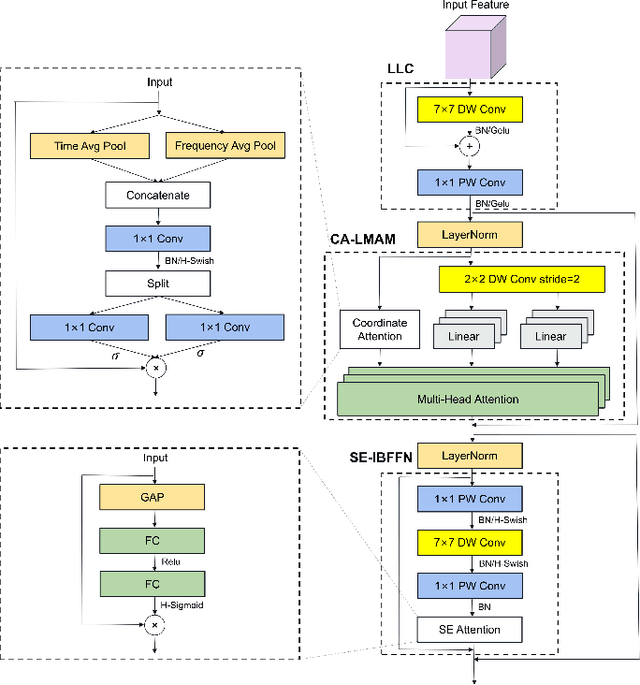
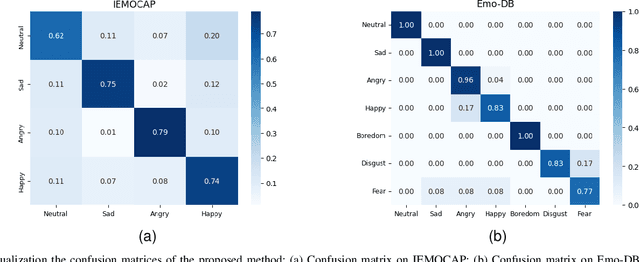
Speech Emotion Recognition (SER) is crucial in human-machine interactions. Mainstream approaches utilize Convolutional Neural Networks or Recurrent Neural Networks to learn local energy feature representations of speech segments from speech information, but struggle with capturing global information such as the duration of energy in speech. Some use Transformers to capture global information, but there is room for improvement in terms of parameter count and performance. Furthermore, existing attention mechanisms focus on spatial or channel dimensions, hindering learning of important temporal information in speech. In this paper, to model local and global information at different levels of granularity in speech and capture temporal, spatial and channel dependencies in speech signals, we propose a Speech Emotion Recognition network based on CNN-Transformer and multi-dimensional attention mechanisms. Specifically, a stack of CNN blocks is dedicated to capturing local information in speech from a time-frequency perspective. In addition, a time-channel-space attention mechanism is used to enhance features across three dimensions. Moreover, we model local and global dependencies of feature sequences using large convolutional kernels with depthwise separable convolutions and lightweight Transformer modules. We evaluate the proposed method on IEMOCAP and Emo-DB datasets and show our approach significantly improves the performance over the state-of-the-art methods. Our code is available on https://github.com/SCNU-RISLAB/CNN-Transforemr-and-Multidimensional-Attention-Mechanism
Masked Trajectory Models for Prediction, Representation, and Control
May 04, 2023



We introduce Masked Trajectory Models (MTM) as a generic abstraction for sequential decision making. MTM takes a trajectory, such as a state-action sequence, and aims to reconstruct the trajectory conditioned on random subsets of the same trajectory. By training with a highly randomized masking pattern, MTM learns versatile networks that can take on different roles or capabilities, by simply choosing appropriate masks at inference time. For example, the same MTM network can be used as a forward dynamics model, inverse dynamics model, or even an offline RL agent. Through extensive experiments in several continuous control tasks, we show that the same MTM network -- i.e. same weights -- can match or outperform specialized networks trained for the aforementioned capabilities. Additionally, we find that state representations learned by MTM can significantly accelerate the learning speed of traditional RL algorithms. Finally, in offline RL benchmarks, we find that MTM is competitive with specialized offline RL algorithms, despite MTM being a generic self-supervised learning method without any explicit RL components. Code is available at https://github.com/facebookresearch/mtm
Where are we in the search for an Artificial Visual Cortex for Embodied Intelligence?
Mar 31, 2023



We present the largest and most comprehensive empirical study of pre-trained visual representations (PVRs) or visual 'foundation models' for Embodied AI. First, we curate CortexBench, consisting of 17 different tasks spanning locomotion, navigation, dexterous, and mobile manipulation. Next, we systematically evaluate existing PVRs and find that none are universally dominant. To study the effect of pre-training data scale and diversity, we combine over 4,000 hours of egocentric videos from 7 different sources (over 5.6M images) and ImageNet to train different-sized vision transformers using Masked Auto-Encoding (MAE) on slices of this data. Contrary to inferences from prior work, we find that scaling dataset size and diversity does not improve performance universally (but does so on average). Our largest model, named VC-1, outperforms all prior PVRs on average but does not universally dominate either. Finally, we show that task or domain-specific adaptation of VC-1 leads to substantial gains, with VC-1 (adapted) achieving competitive or superior performance than the best known results on all of the benchmarks in CortexBench. These models required over 10,000 GPU-hours to train and can be found on our website for the benefit of the research community.
MoDem: Accelerating Visual Model-Based Reinforcement Learning with Demonstrations
Dec 12, 2022



Poor sample efficiency continues to be the primary challenge for deployment of deep Reinforcement Learning (RL) algorithms for real-world applications, and in particular for visuo-motor control. Model-based RL has the potential to be highly sample efficient by concurrently learning a world model and using synthetic rollouts for planning and policy improvement. However, in practice, sample-efficient learning with model-based RL is bottlenecked by the exploration challenge. In this work, we find that leveraging just a handful of demonstrations can dramatically improve the sample-efficiency of model-based RL. Simply appending demonstrations to the interaction dataset, however, does not suffice. We identify key ingredients for leveraging demonstrations in model learning -- policy pretraining, targeted exploration, and oversampling of demonstration data -- which forms the three phases of our model-based RL framework. We empirically study three complex visuo-motor control domains and find that our method is 150%-250% more successful in completing sparse reward tasks compared to prior approaches in the low data regime (100K interaction steps, 5 demonstrations). Code and videos are available at: https://nicklashansen.github.io/modemrl
Transformers are Adaptable Task Planners
Jul 06, 2022
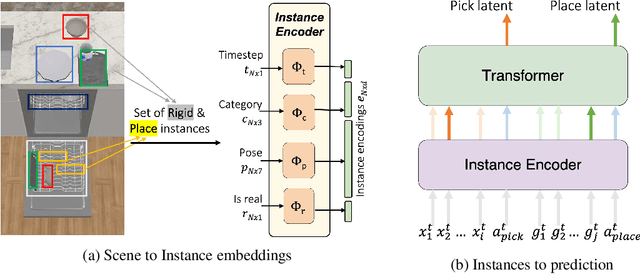
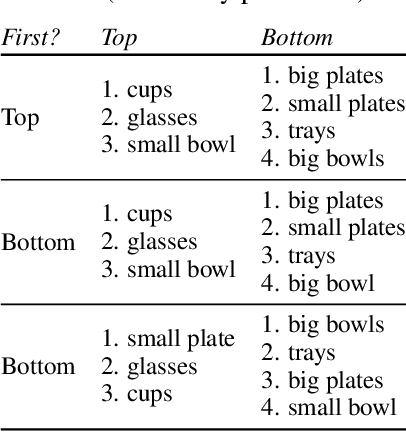
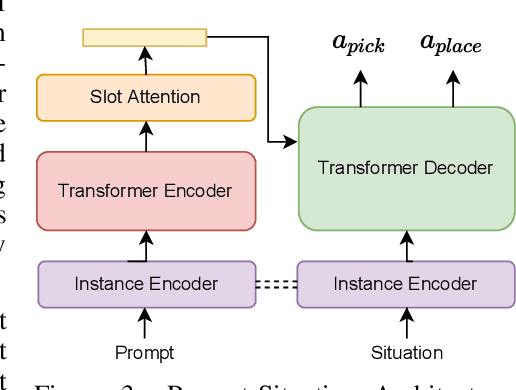
Every home is different, and every person likes things done in their particular way. Therefore, home robots of the future need to both reason about the sequential nature of day-to-day tasks and generalize to user's preferences. To this end, we propose a Transformer Task Planner(TTP) that learns high-level actions from demonstrations by leveraging object attribute-based representations. TTP can be pre-trained on multiple preferences and shows generalization to unseen preferences using a single demonstration as a prompt in a simulated dishwasher loading task. Further, we demonstrate real-world dish rearrangement using TTP with a Franka Panda robotic arm, prompted using a single human demonstration.
RB2: Robotic Manipulation Benchmarking with a Twist
Mar 15, 2022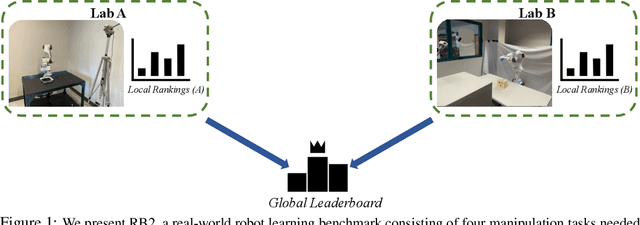
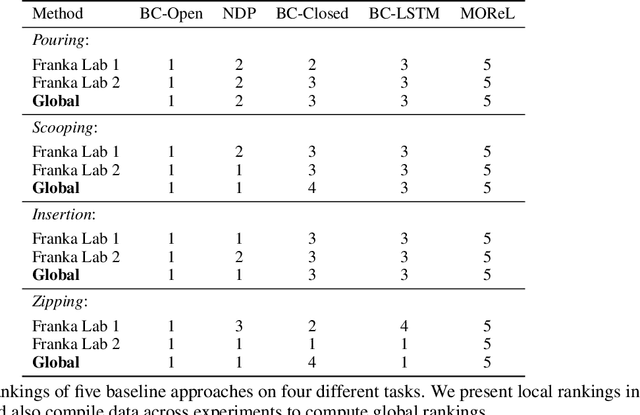

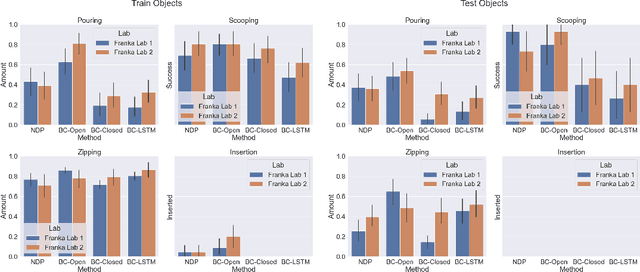
Benchmarks offer a scientific way to compare algorithms using objective performance metrics. Good benchmarks have two features: (a) they should be widely useful for many research groups; (b) and they should produce reproducible findings. In robotic manipulation research, there is a trade-off between reproducibility and broad accessibility. If the benchmark is kept restrictive (fixed hardware, objects), the numbers are reproducible but the setup becomes less general. On the other hand, a benchmark could be a loose set of protocols (e.g. object sets) but the underlying variation in setups make the results non-reproducible. In this paper, we re-imagine benchmarking for robotic manipulation as state-of-the-art algorithmic implementations, alongside the usual set of tasks and experimental protocols. The added baseline implementations will provide a way to easily recreate SOTA numbers in a new local robotic setup, thus providing credible relative rankings between existing approaches and new work. However, these local rankings could vary between different setups. To resolve this issue, we build a mechanism for pooling experimental data between labs, and thus we establish a single global ranking for existing (and proposed) SOTA algorithms. Our benchmark, called Ranking-Based Robotics Benchmark (RB2), is evaluated on tasks that are inspired from clinically validated Southampton Hand Assessment Procedures. Our benchmark was run across two different labs and reveals several surprising findings. For example, extremely simple baselines like open-loop behavior cloning, outperform more complicated models (e.g. closed loop, RNN, Offline-RL, etc.) that are preferred by the field. We hope our fellow researchers will use RB2 to improve their research's quality and rigor.
Differentiable and Learnable Robot Models
Feb 22, 2022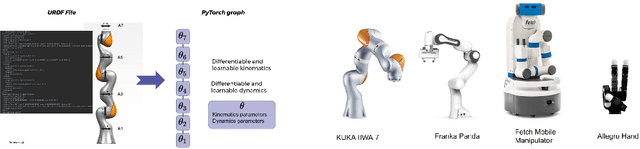
Building differentiable simulations of physical processes has recently received an increasing amount of attention. Specifically, some efforts develop differentiable robotic physics engines motivated by the computational benefits of merging rigid body simulations with modern differentiable machine learning libraries. Here, we present a library that focuses on the ability to combine data driven methods with analytical rigid body computations. More concretely, our library \emph{Differentiable Robot Models} implements both \emph{differentiable} and \emph{learnable} models of the kinematics and dynamics of robots in Pytorch. The source-code is available at \url{https://github.com/facebookresearch/differentiable-robot-model}
Efficient and Interpretable Robot Manipulation with Graph Neural Networks
Feb 25, 2021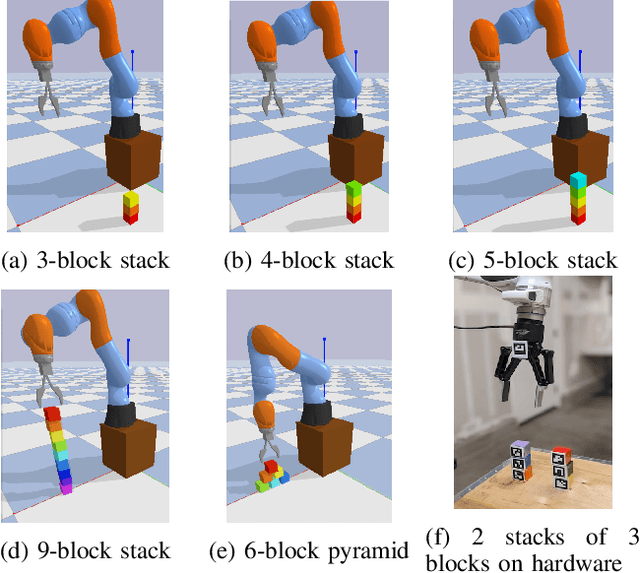


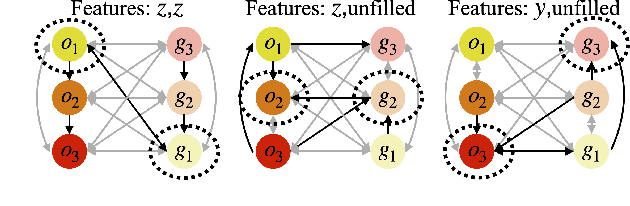
Many manipulation tasks can be naturally cast as a sequence of spatial relationships and constraints between objects. We aim to discover and scale these task-specific spatial relationships by representing manipulation tasks as operations over graphs. To do this, we pose manipulating a large, variable number of objects as a probabilistic classification problem over actions, objects and goals, learned using graph neural networks (GNNs). Our formulation first transforms the environment into a graph representation, then applies a trained GNN policy to predict which object to manipulate towards which goal state. Our GNN policies are trained using very few expert demonstrations on simple tasks, and exhibits generalization over number and configurations of objects in the environment and even to new, more complex tasks, and provide interpretable explanations for their decision-making. We present experiments which show that a single learned GNN policy can solve a variety of blockstacking tasks in both simulation and real hardware.