 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProc4Gem: Foundation models for physical agency through procedural generation
Mar 11, 2025



In robot learning, it is common to either ignore the environment semantics, focusing on tasks like whole-body control which only require reasoning about robot-environment contacts, or conversely to ignore contact dynamics, focusing on grounding high-level movement in vision and language. In this work, we show that advances in generative modeling, photorealistic rendering, and procedural generation allow us to tackle tasks requiring both. By generating contact-rich trajectories with accurate physics in semantically-diverse simulations, we can distill behaviors into large multimodal models that directly transfer to the real world: a system we call Proc4Gem. Specifically, we show that a foundation model, Gemini, fine-tuned on only simulation data, can be instructed in language to control a quadruped robot to push an object with its body to unseen targets in unseen real-world environments. Our real-world results demonstrate the promise of using simulation to imbue foundation models with physical agency. Videos can be found at our website: https://sites.google.com/view/proc4gem
Real-World Fluid Directed Rigid Body Control via Deep Reinforcement Learning
Feb 08, 2024

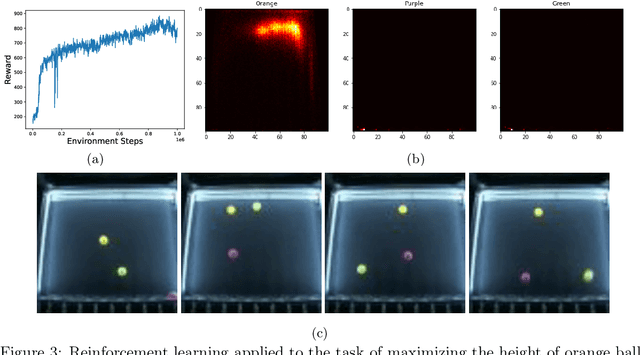
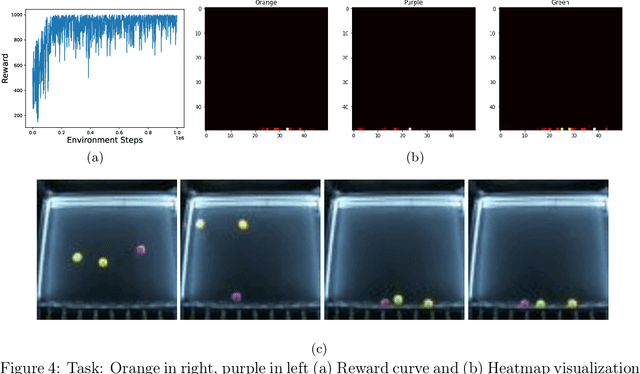
Recent advances in real-world applications of reinforcement learning (RL) have relied on the ability to accurately simulate systems at scale. However, domains such as fluid dynamical systems exhibit complex dynamic phenomena that are hard to simulate at high integration rates, limiting the direct application of modern deep RL algorithms to often expensive or safety critical hardware. In this work, we introduce "Box o Flows", a novel benchtop experimental control system for systematically evaluating RL algorithms in dynamic real-world scenarios. We describe the key components of the Box o Flows, and through a series of experiments demonstrate how state-of-the-art model-free RL algorithms can synthesize a variety of complex behaviors via simple reward specifications. Furthermore, we explore the role of offline RL in data-efficient hypothesis testing by reusing past experiences. We believe that the insights gained from this preliminary study and the availability of systems like the Box o Flows support the way forward for developing systematic RL algorithms that can be generally applied to complex, dynamical systems. Supplementary material and videos of experiments are available at https://sites.google.com/view/box-o-flows/home.
Barkour: Benchmarking Animal-level Agility with Quadruped Robots
May 24, 2023
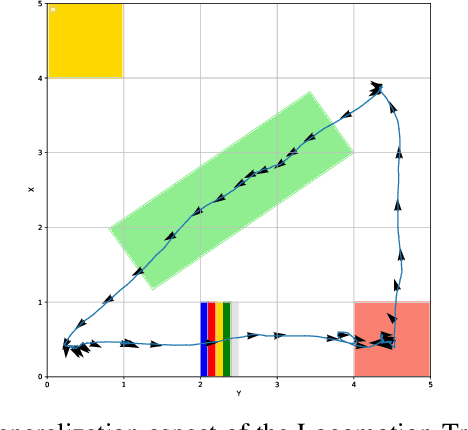
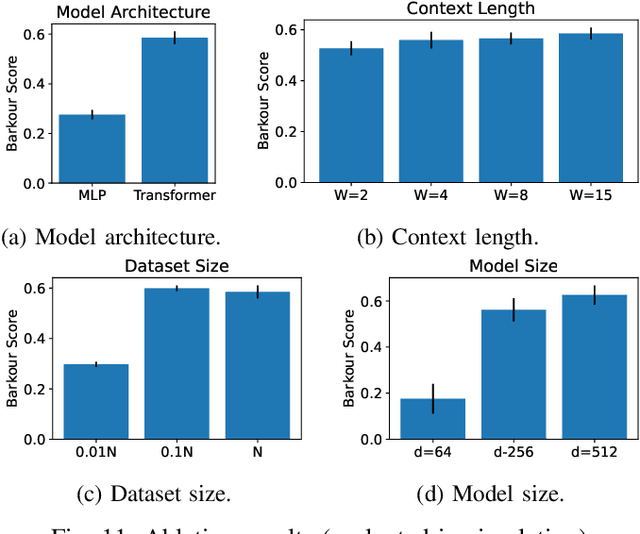

Animals have evolved various agile locomotion strategies, such as sprinting, leaping, and jumping. There is a growing interest in developing legged robots that move like their biological counterparts and show various agile skills to navigate complex environments quickly. Despite the interest, the field lacks systematic benchmarks to measure the performance of control policies and hardware in agility. We introduce the Barkour benchmark, an obstacle course to quantify agility for legged robots. Inspired by dog agility competitions, it consists of diverse obstacles and a time based scoring mechanism. This encourages researchers to develop controllers that not only move fast, but do so in a controllable and versatile way. To set strong baselines, we present two methods for tackling the benchmark. In the first approach, we train specialist locomotion skills using on-policy reinforcement learning methods and combine them with a high-level navigation controller. In the second approach, we distill the specialist skills into a Transformer-based generalist locomotion policy, named Locomotion-Transformer, that can handle various terrains and adjust the robot's gait based on the perceived environment and robot states. Using a custom-built quadruped robot, we demonstrate that our method can complete the course at half the speed of a dog. We hope that our work represents a step towards creating controllers that enable robots to reach animal-level agility.
Imitate and Repurpose: Learning Reusable Robot Movement Skills From Human and Animal Behaviors
Mar 31, 2022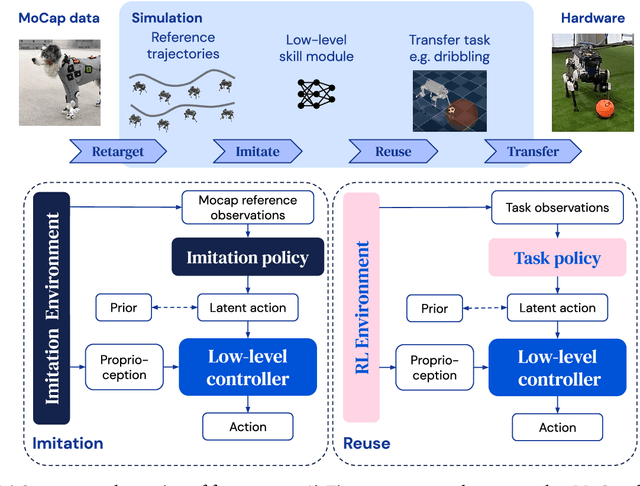

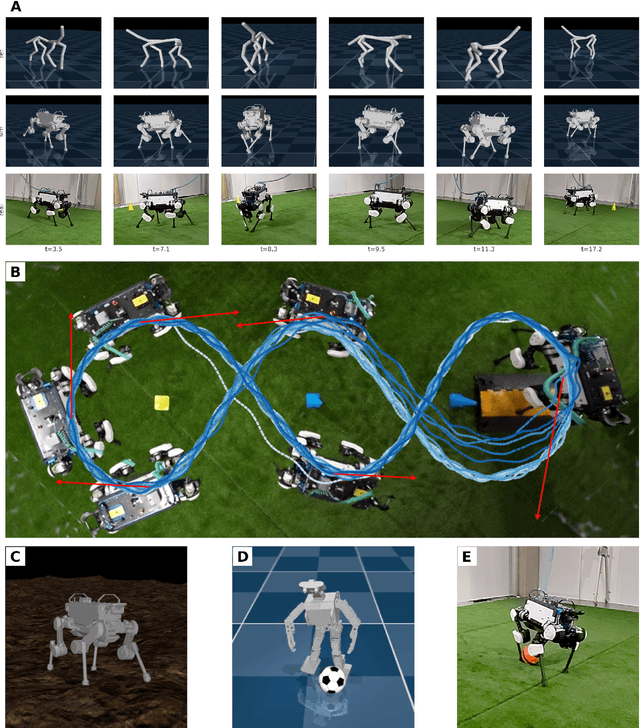
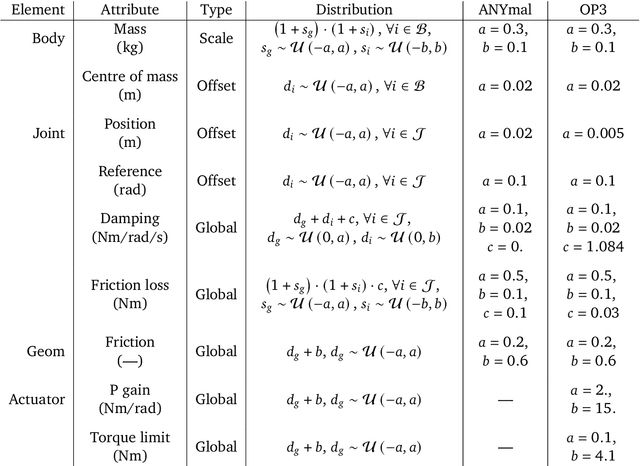
We investigate the use of prior knowledge of human and animal movement to learn reusable locomotion skills for real legged robots. Our approach builds upon previous work on imitating human or dog Motion Capture (MoCap) data to learn a movement skill module. Once learned, this skill module can be reused for complex downstream tasks. Importantly, due to the prior imposed by the MoCap data, our approach does not require extensive reward engineering to produce sensible and natural looking behavior at the time of reuse. This makes it easy to create well-regularized, task-oriented controllers that are suitable for deployment on real robots. We demonstrate how our skill module can be used for imitation, and train controllable walking and ball dribbling policies for both the ANYmal quadruped and OP3 humanoid. These policies are then deployed on hardware via zero-shot simulation-to-reality transfer. Accompanying videos are available at https://bit.ly/robot-npmp.
Continuous-Discrete Reinforcement Learning for Hybrid Control in Robotics
Jan 02, 2020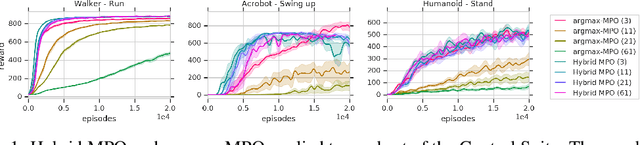



Many real-world control problems involve both discrete decision variables - such as the choice of control modes, gear switching or digital outputs - as well as continuous decision variables - such as velocity setpoints, control gains or analogue outputs. However, when defining the corresponding optimal control or reinforcement learning problem, it is commonly approximated with fully continuous or fully discrete action spaces. These simplifications aim at tailoring the problem to a particular algorithm or solver which may only support one type of action space. Alternatively, expert heuristics are used to remove discrete actions from an otherwise continuous space. In contrast, we propose to treat hybrid problems in their 'native' form by solving them with hybrid reinforcement learning, which optimizes for discrete and continuous actions simultaneously. In our experiments, we first demonstrate that the proposed approach efficiently solves such natively hybrid reinforcement learning problems. We then show, both in simulation and on robotic hardware, the benefits of removing possibly imperfect expert-designed heuristics. Lastly, hybrid reinforcement learning encourages us to rethink problem definitions. We propose reformulating control problems, e.g. by adding meta actions, to improve exploration or reduce mechanical wear and tear.
Modelling Generalized Forces with Reinforcement Learning for Sim-to-Real Transfer
Oct 21, 2019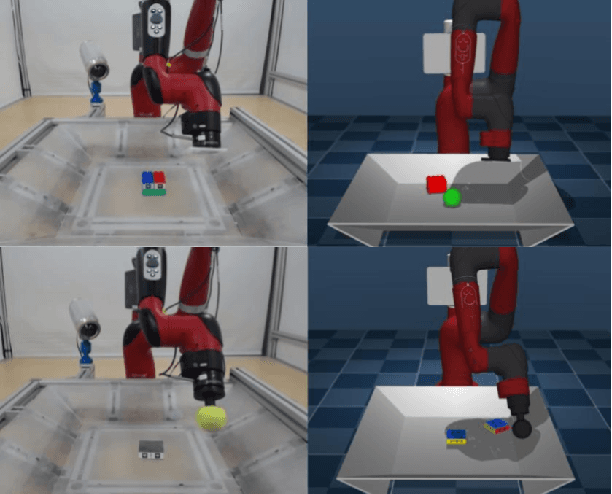
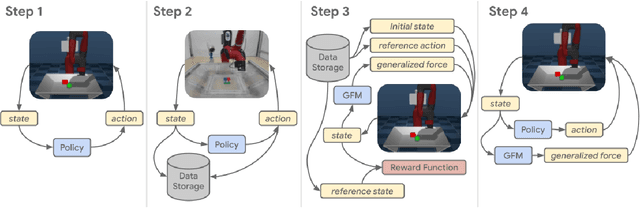
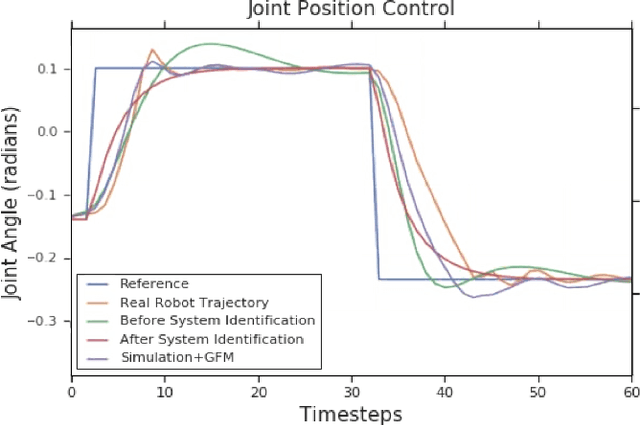

Learning robotic control policies in the real world gives rise to challenges in data efficiency, safety, and controlling the initial condition of the system. On the other hand, simulations are a useful alternative as they provide an abundant source of data without the restrictions of the real world. Unfortunately, simulations often fail to accurately model complex real-world phenomena. Traditional system identification techniques are limited in expressiveness by the analytical model parameters, and usually are not sufficient to capture such phenomena. In this paper we propose a general framework for improving the analytical model by optimizing state dependent generalized forces. State dependent generalized forces are expressive enough to model constraints in the equations of motion, while maintaining a clear physical meaning and intuition. We use reinforcement learning to efficiently optimize the mapping from states to generalized forces over a discounted infinite horizon. We show that using only minutes of real world data improves the sim-to-real control policy transfer. We demonstrate the feasibility of our approach by validating it on a nonprehensile manipulation task on the Sawyer robot.
A Generic Synchronous Dataflow Architecture to Rapidly Prototype and Deploy Robot Controllers
Jun 05, 2019
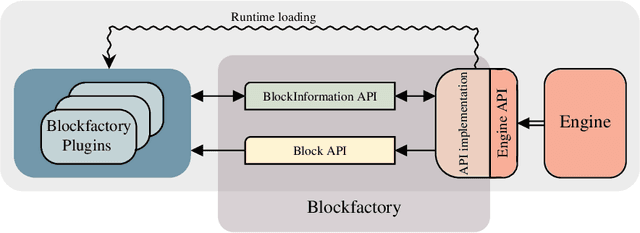
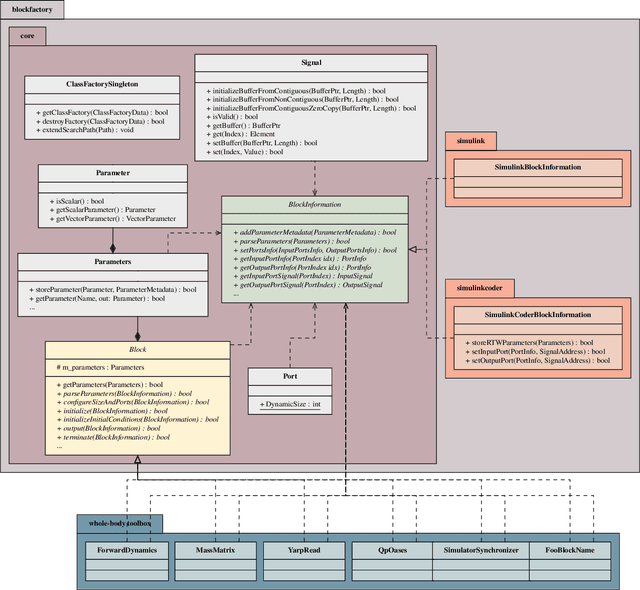
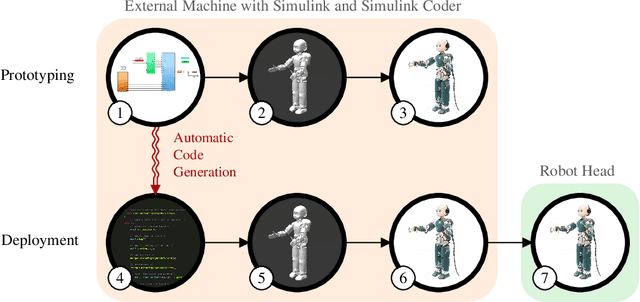
The paper presents a software architecture to optimize the process of prototyping and deploying robot controllers that are synthesized using model-based design methodologies. The architecture is composed of a framework and a pipeline. Therefore, the contribution of the paper is twofold. First, we introduce an open-source actor-oriented framework that abstracts the common robotic uses of middlewares, optimizers, and simulators. Using this framework, we then present a pipeline that implements the model-based design methodology. The components of the proposed framework are generic, and they can be interfaced with any tool supporting model-based design. We demonstrate the effectiveness of the approach describing the application of the resulting synchronous dataflow architecture to the design of a balancing controller for the YARP-based humanoid robot iCub. This example exploits the interfacing with Simulink and Simulink Coder.
A Control Architecture with Online Predictive Planning for Position and Torque Controlled Walking of Humanoid Robots
Jul 14, 2018
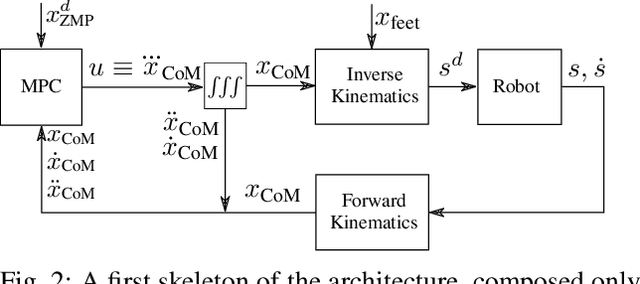

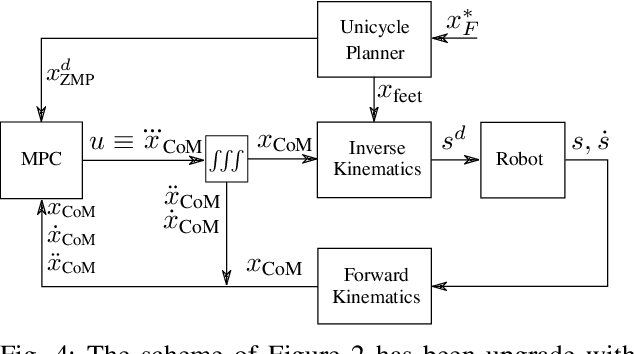
A common approach to the generation of walking patterns for humanoid robots consists in adopting a layered control architecture. This paper proposes an architecture composed of three nested control loops. The outer loop exploits a robot kinematic model to plan the footstep positions. In the mid layer, a predictive controller generates a Center of Mass trajectory according to the well-known table-cart model. Through a whole-body inverse kinematics algorithm, we can define joint references for position controlled walking. The outcomes of these two loops are then interpreted as inputs of a stack-of-task QP-based torque controller, which represents the inner loop of the presented control architecture. This resulting architecture allows the robot to walk also in torque control, guaranteeing higher level of compliance. Real world experiments have been carried on the humanoid robot iCub.
Modeling and Control of Humanoid Robots in Dynamic Environments: iCub Balancing on a Seesaw
Mar 09, 2018
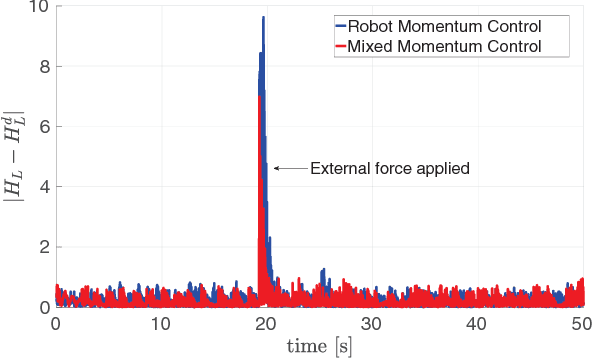
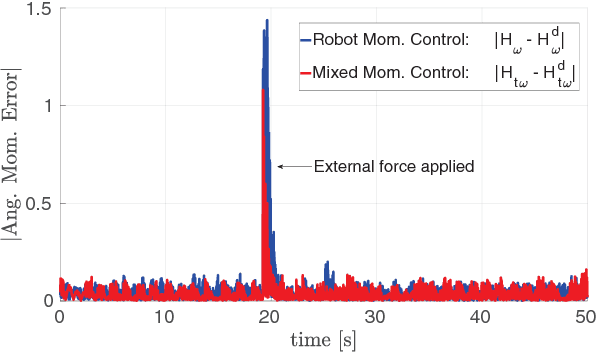
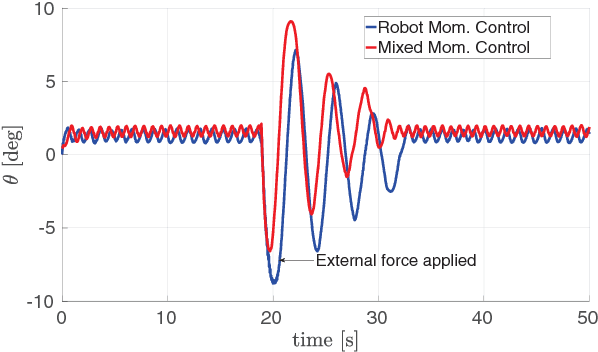
Forthcoming applications concerning humanoid robots may involve physical interaction between the robot and a dynamic environment. In such scenario, classical balancing and walking controllers that neglect the environment dynamics may not be sufficient for achieving a stable robot behavior. This paper presents a modeling and control framework for balancing humanoid robots in contact with a dynamic environment. We first model the robot and environment dynamics, together with the contact constraints. Then, a control strategy for stabilizing the full system is proposed. Theoretical results are verified in simulation with robot iCub balancing on a seesaw.
A Predictive Momentum-Based Whole-Body Torque Controller: Theory and Simulations for the iCub Stepping
Jul 28, 2017
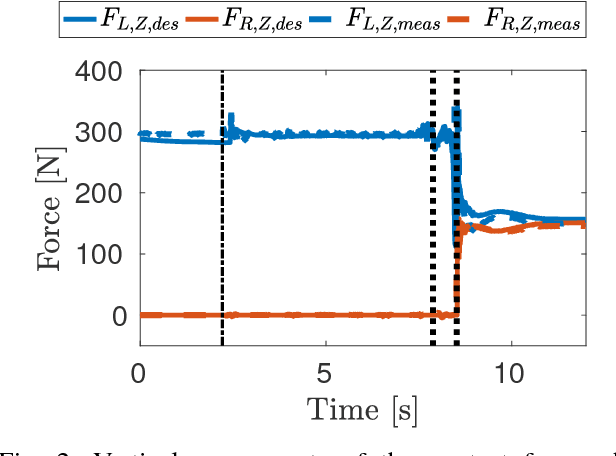

When balancing, a humanoid robot can be easily subjected to unexpected disturbances like external pushes. In these circumstances, reactive movements as steps become a necessary requirement in order to avoid potentially harmful falling states. In this paper we conceive a Model Predictive Controller which determines a desired set of contact wrenches by predicting the future evolution of the robot, while taking into account constraints switching in case of steps. The control inputs computed by this strategy, namely the desired contact wrenches, are directly obtained on the robot through a modification of the momentum-based whole-body torque controller currently implemented on iCub. The proposed approach is validated through simulations in a stepping scenario, revealing high robustness and reliability when executing a recovery strategy.