 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSplatting Physical Scenes: End-to-End Real-to-Sim from Imperfect Robot Data
Jun 09, 2025Creating accurate, physical simulations directly from real-world robot motion holds great value for safe, scalable, and affordable robot learning, yet remains exceptionally challenging. Real robot data suffers from occlusions, noisy camera poses, dynamic scene elements, which hinder the creation of geometrically accurate and photorealistic digital twins of unseen objects. We introduce a novel real-to-sim framework tackling all these challenges at once. Our key insight is a hybrid scene representation merging the photorealistic rendering of 3D Gaussian Splatting with explicit object meshes suitable for physics simulation within a single representation. We propose an end-to-end optimization pipeline that leverages differentiable rendering and differentiable physics within MuJoCo to jointly refine all scene components - from object geometry and appearance to robot poses and physical parameters - directly from raw and imprecise robot trajectories. This unified optimization allows us to simultaneously achieve high-fidelity object mesh reconstruction, generate photorealistic novel views, and perform annotation-free robot pose calibration. We demonstrate the effectiveness of our approach both in simulation and on challenging real-world sequences using an ALOHA 2 bi-manual manipulator, enabling more practical and robust real-to-simulation pipelines.
Gemini Robotics: Bringing AI into the Physical World
Mar 25, 2025Recent advancements in large multimodal models have led to the emergence of remarkable generalist capabilities in digital domains, yet their translation to physical agents such as robots remains a significant challenge. This report introduces a new family of AI models purposefully designed for robotics and built upon the foundation of Gemini 2.0. We present Gemini Robotics, an advanced Vision-Language-Action (VLA) generalist model capable of directly controlling robots. Gemini Robotics executes smooth and reactive movements to tackle a wide range of complex manipulation tasks while also being robust to variations in object types and positions, handling unseen environments as well as following diverse, open vocabulary instructions. We show that with additional fine-tuning, Gemini Robotics can be specialized to new capabilities including solving long-horizon, highly dexterous tasks, learning new short-horizon tasks from as few as 100 demonstrations and adapting to completely novel robot embodiments. This is made possible because Gemini Robotics builds on top of the Gemini Robotics-ER model, the second model we introduce in this work. Gemini Robotics-ER (Embodied Reasoning) extends Gemini's multimodal reasoning capabilities into the physical world, with enhanced spatial and temporal understanding. This enables capabilities relevant to robotics including object detection, pointing, trajectory and grasp prediction, as well as multi-view correspondence and 3D bounding box predictions. We show how this novel combination can support a variety of robotics applications. We also discuss and address important safety considerations related to this new class of robotics foundation models. The Gemini Robotics family marks a substantial step towards developing general-purpose robots that realizes AI's potential in the physical world.
Proc4Gem: Foundation models for physical agency through procedural generation
Mar 11, 2025



In robot learning, it is common to either ignore the environment semantics, focusing on tasks like whole-body control which only require reasoning about robot-environment contacts, or conversely to ignore contact dynamics, focusing on grounding high-level movement in vision and language. In this work, we show that advances in generative modeling, photorealistic rendering, and procedural generation allow us to tackle tasks requiring both. By generating contact-rich trajectories with accurate physics in semantically-diverse simulations, we can distill behaviors into large multimodal models that directly transfer to the real world: a system we call Proc4Gem. Specifically, we show that a foundation model, Gemini, fine-tuned on only simulation data, can be instructed in language to control a quadruped robot to push an object with its body to unseen targets in unseen real-world environments. Our real-world results demonstrate the promise of using simulation to imbue foundation models with physical agency. Videos can be found at our website: https://sites.google.com/view/proc4gem
Barkour: Benchmarking Animal-level Agility with Quadruped Robots
May 24, 2023
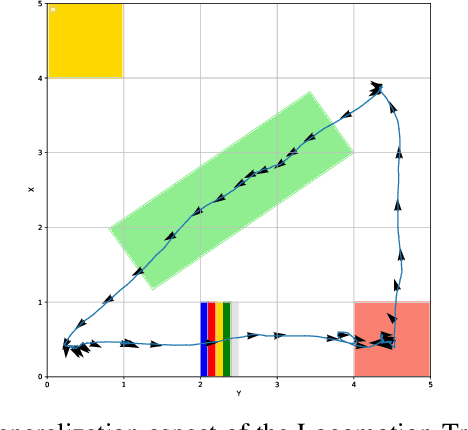
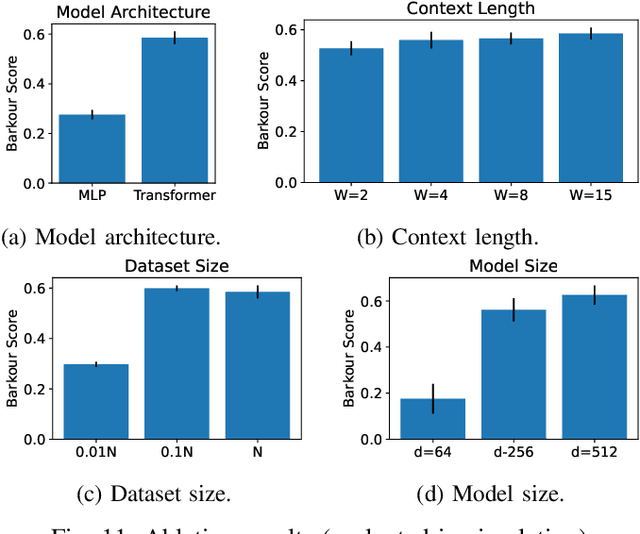

Animals have evolved various agile locomotion strategies, such as sprinting, leaping, and jumping. There is a growing interest in developing legged robots that move like their biological counterparts and show various agile skills to navigate complex environments quickly. Despite the interest, the field lacks systematic benchmarks to measure the performance of control policies and hardware in agility. We introduce the Barkour benchmark, an obstacle course to quantify agility for legged robots. Inspired by dog agility competitions, it consists of diverse obstacles and a time based scoring mechanism. This encourages researchers to develop controllers that not only move fast, but do so in a controllable and versatile way. To set strong baselines, we present two methods for tackling the benchmark. In the first approach, we train specialist locomotion skills using on-policy reinforcement learning methods and combine them with a high-level navigation controller. In the second approach, we distill the specialist skills into a Transformer-based generalist locomotion policy, named Locomotion-Transformer, that can handle various terrains and adjust the robot's gait based on the perceived environment and robot states. Using a custom-built quadruped robot, we demonstrate that our method can complete the course at half the speed of a dog. We hope that our work represents a step towards creating controllers that enable robots to reach animal-level agility.
NeRF2Real: Sim2real Transfer of Vision-guided Bipedal Motion Skills using Neural Radiance Fields
Oct 10, 2022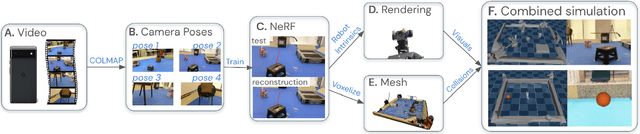
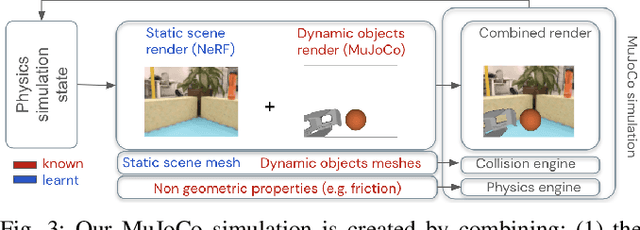
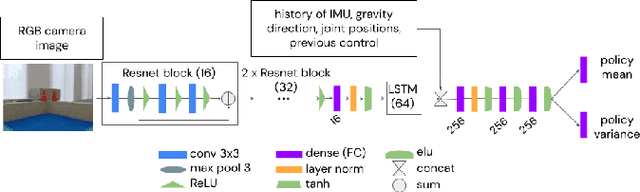

We present a system for applying sim2real approaches to "in the wild" scenes with realistic visuals, and to policies which rely on active perception using RGB cameras. Given a short video of a static scene collected using a generic phone, we learn the scene's contact geometry and a function for novel view synthesis using a Neural Radiance Field (NeRF). We augment the NeRF rendering of the static scene by overlaying the rendering of other dynamic objects (e.g. the robot's own body, a ball). A simulation is then created using the rendering engine in a physics simulator which computes contact dynamics from the static scene geometry (estimated from the NeRF volume density) and the dynamic objects' geometry and physical properties (assumed known). We demonstrate that we can use this simulation to learn vision-based whole body navigation and ball pushing policies for a 20 degrees of freedom humanoid robot with an actuated head-mounted RGB camera, and we successfully transfer these policies to a real robot. Project video is available at https://sites.google.com/view/nerf2real/home
Offline Distillation for Robot Lifelong Learning with Imbalanced Experience
Apr 12, 2022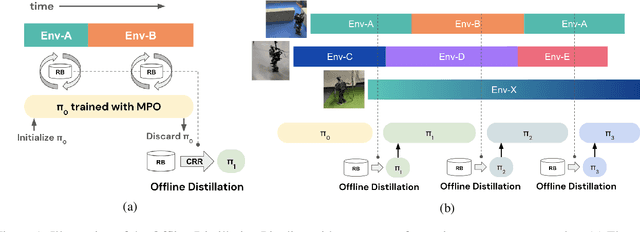
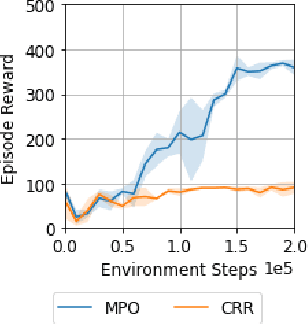
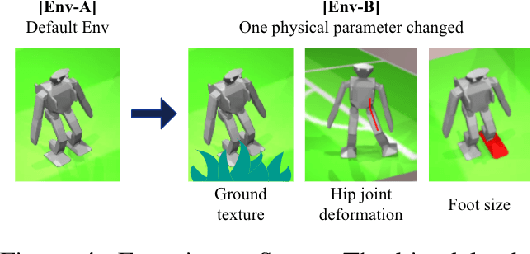
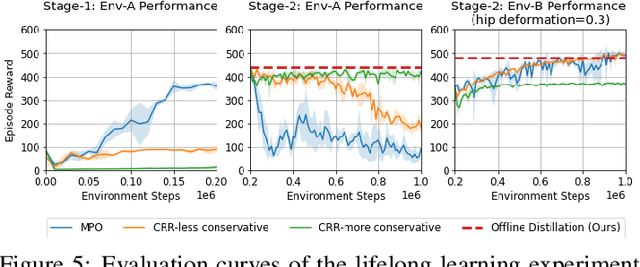
Robots will experience non-stationary environment dynamics throughout their lifetime: the robot dynamics can change due to wear and tear, or its surroundings may change over time. Eventually, the robots should perform well in all of the environment variations it has encountered. At the same time, it should still be able to learn fast in a new environment. We investigate two challenges in such a lifelong learning setting: first, existing off-policy algorithms struggle with the trade-off between being conservative to maintain good performance in the old environment and learning efficiently in the new environment. We propose the Offline Distillation Pipeline to break this trade-off by separating the training procedure into interleaved phases of online interaction and offline distillation. Second, training with the combined datasets from multiple environments across the lifetime might create a significant performance drop compared to training on the datasets individually. Our hypothesis is that both the imbalanced quality and size of the datasets exacerbate the extrapolation error of the Q-function during offline training over the "weaker" dataset. We propose a simple fix to the issue by keeping the policy closer to the dataset during the distillation phase. In the experiments, we demonstrate these challenges and the proposed solutions with a simulated bipedal robot walking task across various environment changes. We show that the Offline Distillation Pipeline achieves better performance across all the encountered environments without affecting data collection. We also provide a comprehensive empirical study to support our hypothesis on the data imbalance issue.
Imitate and Repurpose: Learning Reusable Robot Movement Skills From Human and Animal Behaviors
Mar 31, 2022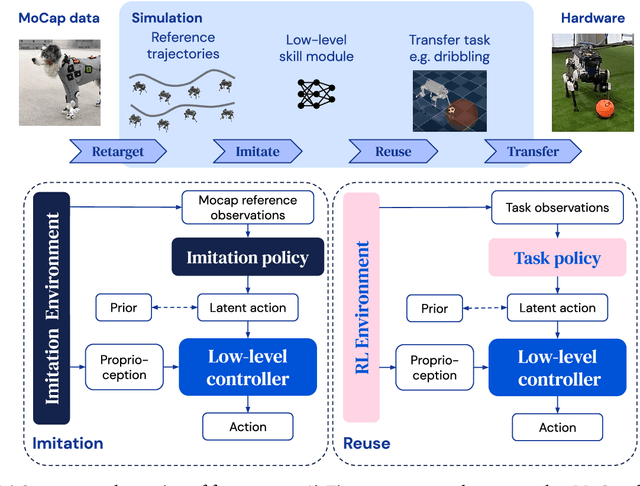

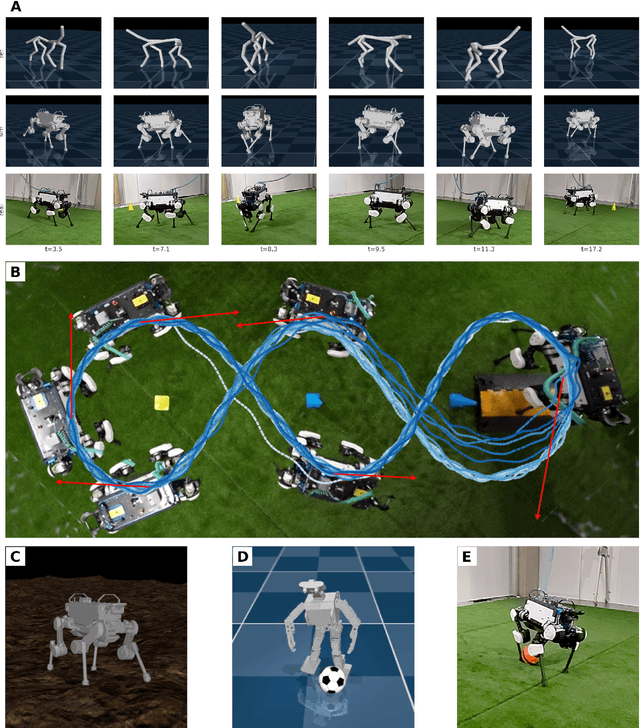
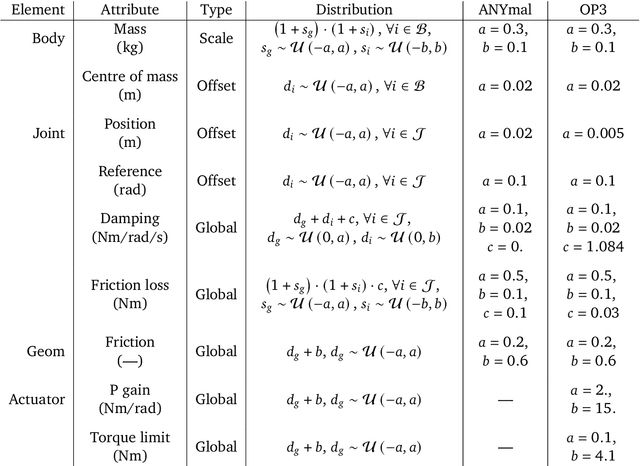
We investigate the use of prior knowledge of human and animal movement to learn reusable locomotion skills for real legged robots. Our approach builds upon previous work on imitating human or dog Motion Capture (MoCap) data to learn a movement skill module. Once learned, this skill module can be reused for complex downstream tasks. Importantly, due to the prior imposed by the MoCap data, our approach does not require extensive reward engineering to produce sensible and natural looking behavior at the time of reuse. This makes it easy to create well-regularized, task-oriented controllers that are suitable for deployment on real robots. We demonstrate how our skill module can be used for imitation, and train controllable walking and ball dribbling policies for both the ANYmal quadruped and OP3 humanoid. These policies are then deployed on hardware via zero-shot simulation-to-reality transfer. Accompanying videos are available at https://bit.ly/robot-npmp.
Learning Coordinated Terrain-Adaptive Locomotion by Imitating a Centroidal Dynamics Planner
Oct 30, 2021


Dynamic quadruped locomotion over challenging terrains with precise foot placements is a hard problem for both optimal control methods and Reinforcement Learning (RL). Non-linear solvers can produce coordinated constraint satisfying motions, but often take too long to converge for online application. RL methods can learn dynamic reactive controllers but require carefully tuned shaping rewards to produce good gaits and can have trouble discovering precise coordinated movements. Imitation learning circumvents this problem and has been used with motion capture data to extract quadruped gaits for flat terrains. However, it would be costly to acquire motion capture data for a very large variety of terrains with height differences. In this work, we combine the advantages of trajectory optimization and learning methods and show that terrain adaptive controllers can be obtained by training policies to imitate trajectories that have been planned over procedural terrains by a non-linear solver. We show that the learned policies transfer to unseen terrains and can be fine-tuned to dynamically traverse challenging terrains that require precise foot placements and are very hard to solve with standard RL.
dm_control: Software and Tasks for Continuous Control
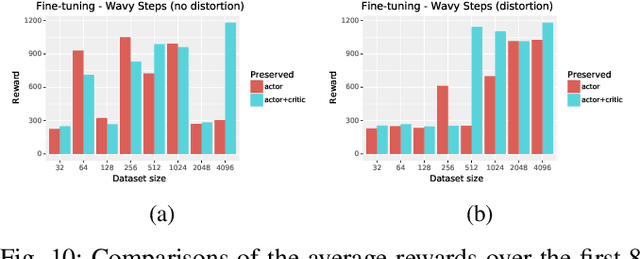
Jun 22, 2020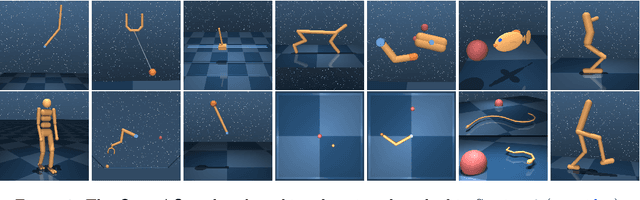

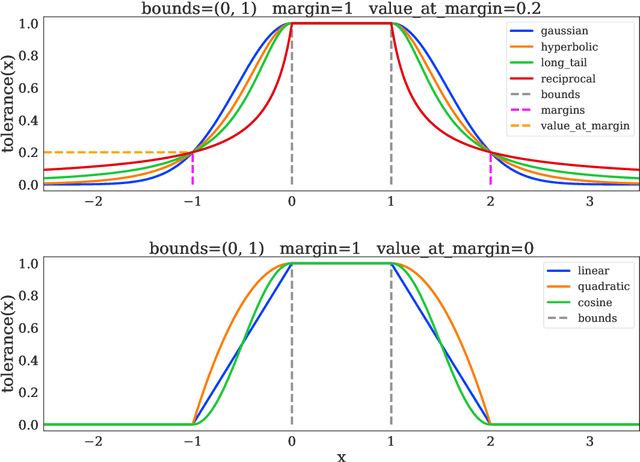
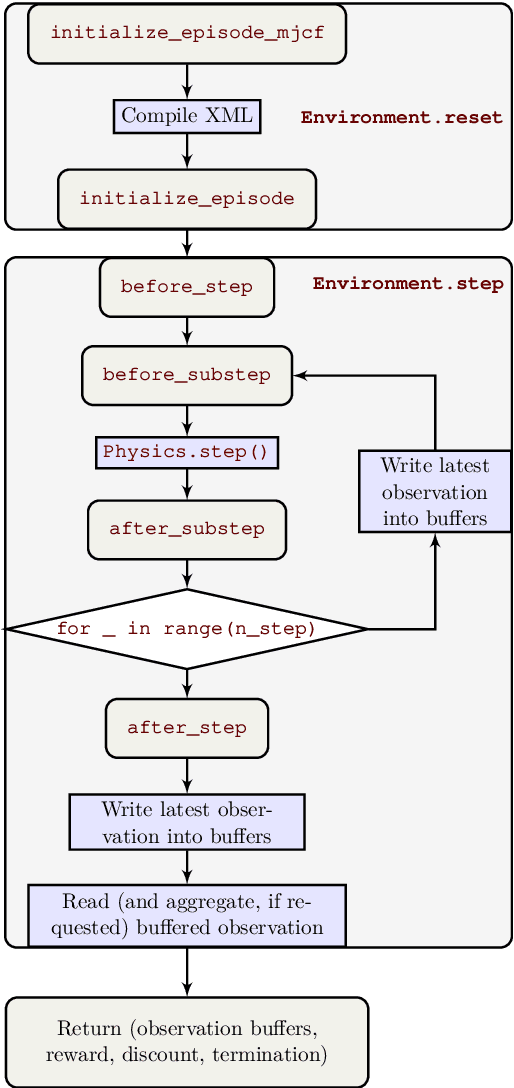
The dm_control software package is a collection of Python libraries and task suites for reinforcement learning agents in an articulated-body simulation. A MuJoCo wrapper provides convenient bindings to functions and data structures. The PyMJCF and Composer libraries enable procedural model manipulation and task authoring. The Control Suite is a fixed set of tasks with standardised structure, intended to serve as performance benchmarks. The Locomotion framework provides high-level abstractions and examples of locomotion tasks. A set of configurable manipulation tasks with a robot arm and snap-together bricks is also included. dm_control is publicly available at https://www.github.com/deepmind/dm_control
Value constrained model-free continuous control
Feb 12, 2019


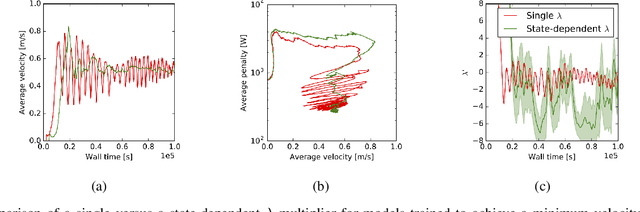
The naive application of Reinforcement Learning algorithms to continuous control problems -- such as locomotion and manipulation -- often results in policies which rely on high-amplitude, high-frequency control signals, known colloquially as bang-bang control. Although such solutions may indeed maximize task reward, they can be unsuitable for real world systems. Bang-bang control may lead to increased wear and tear or energy consumption, and tends to excite undesired second-order dynamics. To counteract this issue, multi-objective optimization can be used to simultaneously optimize both the reward and some auxiliary cost that discourages undesired (e.g. high-amplitude) control. In principle, such an approach can yield the sought after, smooth, control policies. It can, however, be hard to find the correct trade-off between cost and return that results in the desired behavior. In this paper we propose a new constraint-based reinforcement learning approach that ensures task success while minimizing one or more auxiliary costs (such as control effort). We employ Lagrangian relaxation to learn both (a) the parameters of a control policy that satisfies the desired constraints and (b) the Lagrangian multipliers for the optimization. Moreover, we demonstrate that we can satisfy constraints either in expectation or in a per-step fashion, and can even learn a single policy that is able to dynamically trade-off between return and cost. We demonstrate the efficacy of our approach using a number of continuous control benchmark tasks, a realistic, energy-optimized quadruped locomotion task, as well as a reaching task on a real robot arm.