 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOffline Distillation for Robot Lifelong Learning with Imbalanced Experience
Paper and Code
Apr 12, 2022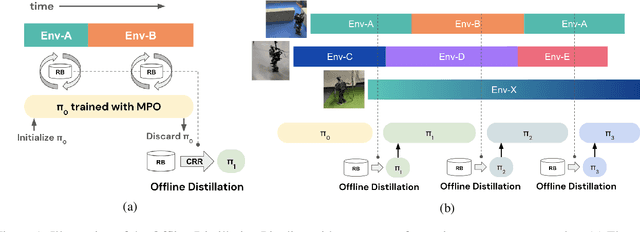
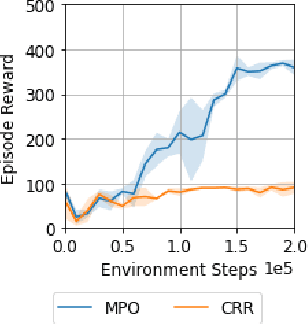
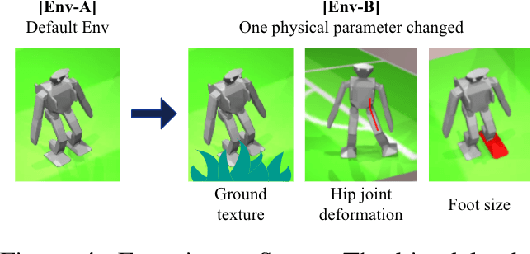
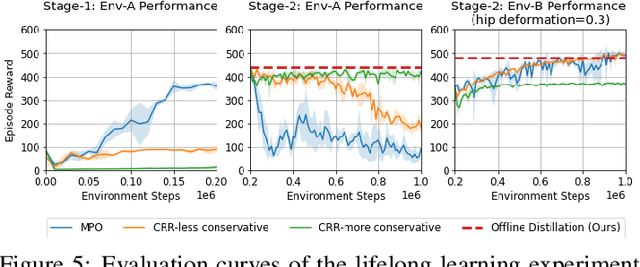
Robots will experience non-stationary environment dynamics throughout their lifetime: the robot dynamics can change due to wear and tear, or its surroundings may change over time. Eventually, the robots should perform well in all of the environment variations it has encountered. At the same time, it should still be able to learn fast in a new environment. We investigate two challenges in such a lifelong learning setting: first, existing off-policy algorithms struggle with the trade-off between being conservative to maintain good performance in the old environment and learning efficiently in the new environment. We propose the Offline Distillation Pipeline to break this trade-off by separating the training procedure into interleaved phases of online interaction and offline distillation. Second, training with the combined datasets from multiple environments across the lifetime might create a significant performance drop compared to training on the datasets individually. Our hypothesis is that both the imbalanced quality and size of the datasets exacerbate the extrapolation error of the Q-function during offline training over the "weaker" dataset. We propose a simple fix to the issue by keeping the policy closer to the dataset during the distillation phase. In the experiments, we demonstrate these challenges and the proposed solutions with a simulated bipedal robot walking task across various environment changes. We show that the Offline Distillation Pipeline achieves better performance across all the encountered environments without affecting data collection. We also provide a comprehensive empirical study to support our hypothesis on the data imbalance issue.