 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeValue from Observations: Towards Large-Scale Imitation Learning via Self-Improvement
Jul 09, 2025Imitation Learning from Observation (IfO) offers a powerful way to learn behaviors at large-scale: Unlike behavior cloning or offline reinforcement learning, IfO can leverage action-free demonstrations and thus circumvents the need for costly action-labeled demonstrations or reward functions. However, current IfO research focuses on idealized scenarios with mostly bimodal-quality data distributions, restricting the meaningfulness of the results. In contrast, this paper investigates more nuanced distributions and introduces a method to learn from such data, moving closer to a paradigm in which imitation learning can be performed iteratively via self-improvement. Our method adapts RL-based imitation learning to action-free demonstrations, using a value function to transfer information between expert and non-expert data. Through comprehensive evaluation, we delineate the relation between different data distributions and the applicability of algorithms and highlight the limitations of established methods. Our findings provide valuable insights for developing more robust and practical IfO techniques on a path to scalable behaviour learning.
Offline Actor-Critic Reinforcement Learning Scales to Large Models
Feb 08, 2024



We show that offline actor-critic reinforcement learning can scale to large models - such as transformers - and follows similar scaling laws as supervised learning. We find that offline actor-critic algorithms can outperform strong, supervised, behavioral cloning baselines for multi-task training on a large dataset containing both sub-optimal and expert behavior on 132 continuous control tasks. We introduce a Perceiver-based actor-critic model and elucidate the key model features needed to make offline RL work with self- and cross-attention modules. Overall, we find that: i) simple offline actor critic algorithms are a natural choice for gradually moving away from the currently predominant paradigm of behavioral cloning, and ii) via offline RL it is possible to learn multi-task policies that master many domains simultaneously, including real robotics tasks, from sub-optimal demonstrations or self-generated data.
Imitate and Repurpose: Learning Reusable Robot Movement Skills From Human and Animal Behaviors
Mar 31, 2022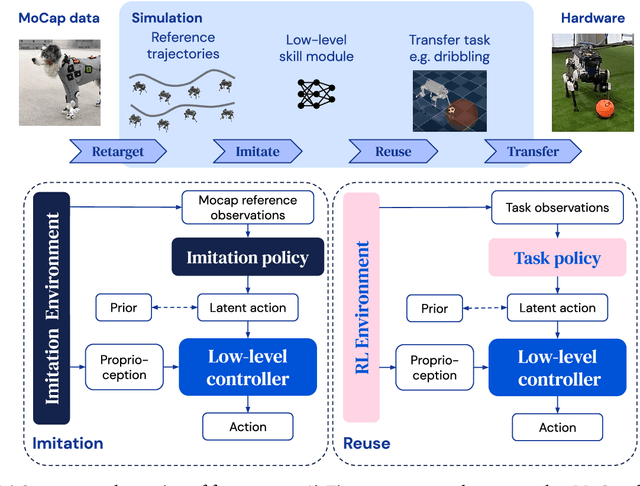

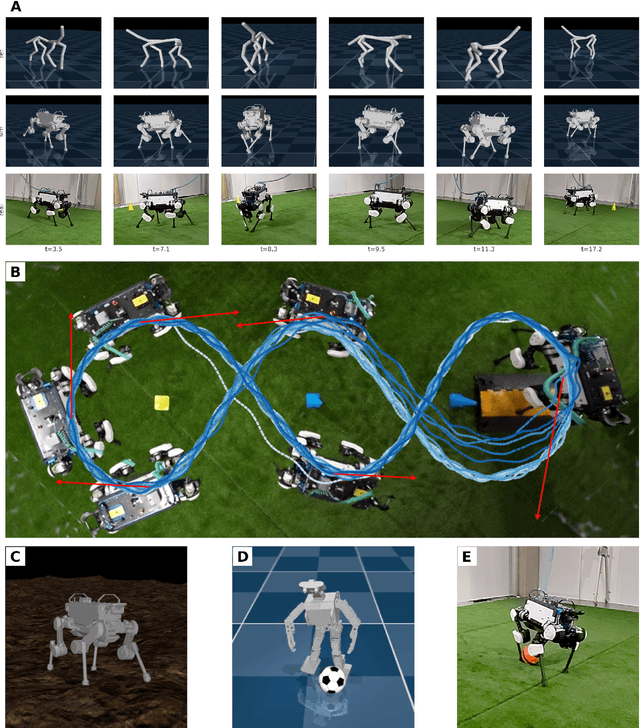
We investigate the use of prior knowledge of human and animal movement to learn reusable locomotion skills for real legged robots. Our approach builds upon previous work on imitating human or dog Motion Capture (MoCap) data to learn a movement skill module. Once learned, this skill module can be reused for complex downstream tasks. Importantly, due to the prior imposed by the MoCap data, our approach does not require extensive reward engineering to produce sensible and natural looking behavior at the time of reuse. This makes it easy to create well-regularized, task-oriented controllers that are suitable for deployment on real robots. We demonstrate how our skill module can be used for imitation, and train controllable walking and ball dribbling policies for both the ANYmal quadruped and OP3 humanoid. These policies are then deployed on hardware via zero-shot simulation-to-reality transfer. Accompanying videos are available at https://bit.ly/robot-npmp.
Learning Coordinated Terrain-Adaptive Locomotion by Imitating a Centroidal Dynamics Planner
Oct 30, 2021


Dynamic quadruped locomotion over challenging terrains with precise foot placements is a hard problem for both optimal control methods and Reinforcement Learning (RL). Non-linear solvers can produce coordinated constraint satisfying motions, but often take too long to converge for online application. RL methods can learn dynamic reactive controllers but require carefully tuned shaping rewards to produce good gaits and can have trouble discovering precise coordinated movements. Imitation learning circumvents this problem and has been used with motion capture data to extract quadruped gaits for flat terrains. However, it would be costly to acquire motion capture data for a very large variety of terrains with height differences. In this work, we combine the advantages of trajectory optimization and learning methods and show that terrain adaptive controllers can be obtained by training policies to imitate trajectories that have been planned over procedural terrains by a non-linear solver. We show that the learned policies transfer to unseen terrains and can be fine-tuned to dynamically traverse challenging terrains that require precise foot placements and are very hard to solve with standard RL.
Recall Traces: Backtracking Models for Efficient Reinforcement Learning
Apr 02, 2018

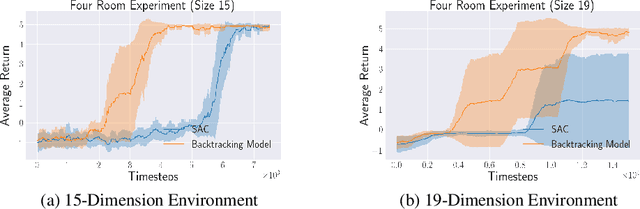

In many environments only a tiny subset of all states yield high reward. In these cases, few of the interactions with the environment provide a relevant learning signal. Hence, we may want to preferentially train on those high-reward states and the probable trajectories leading to them. To this end, we advocate for the use of a backtracking model that predicts the preceding states that terminate at a given high-reward state. We can train a model which, starting from a high value state (or one that is estimated to have high value), predicts and sample for which the (state, action)-tuples may have led to that high value state. These traces of (state, action) pairs, which we refer to as Recall Traces, sampled from this backtracking model starting from a high value state, are informative as they terminate in good states, and hence we can use these traces to improve a policy. We provide a variational interpretation for this idea and a practical algorithm in which the backtracking model samples from an approximate posterior distribution over trajectories which lead to large rewards. Our method improves the sample efficiency of both on- and off-policy RL algorithms across several environments and tasks.
Light Gated Recurrent Units for Speech Recognition
Mar 26, 2018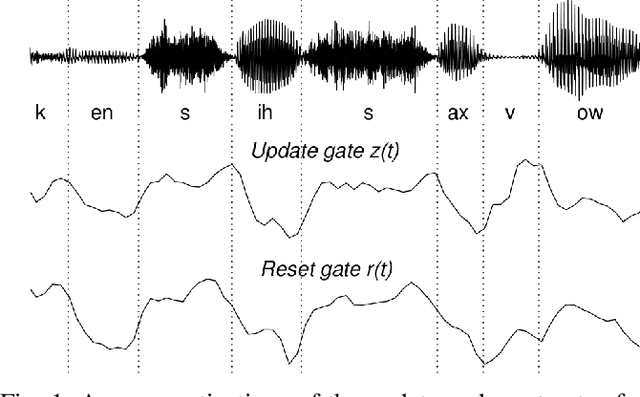
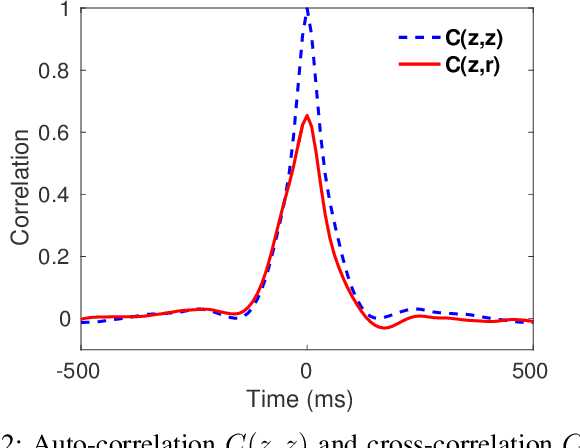
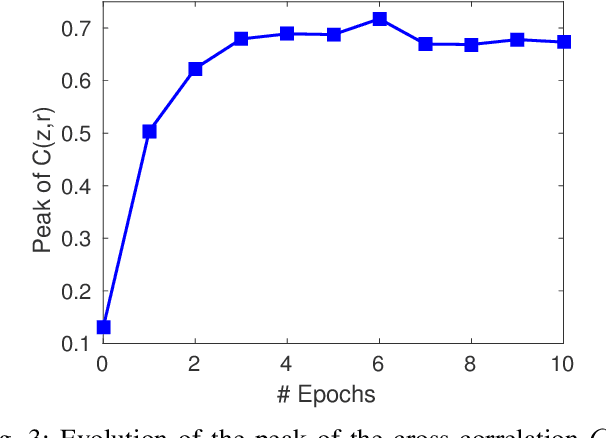
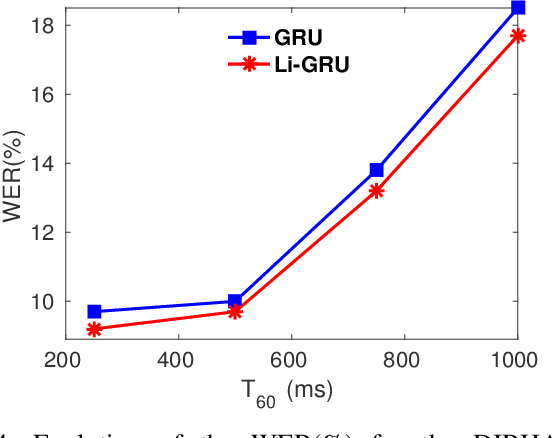
A field that has directly benefited from the recent advances in deep learning is Automatic Speech Recognition (ASR). Despite the great achievements of the past decades, however, a natural and robust human-machine speech interaction still appears to be out of reach, especially in challenging environments characterized by significant noise and reverberation. To improve robustness, modern speech recognizers often employ acoustic models based on Recurrent Neural Networks (RNNs), that are naturally able to exploit large time contexts and long-term speech modulations. It is thus of great interest to continue the study of proper techniques for improving the effectiveness of RNNs in processing speech signals. In this paper, we revise one of the most popular RNN models, namely Gated Recurrent Units (GRUs), and propose a simplified architecture that turned out to be very effective for ASR. The contribution of this work is two-fold: First, we analyze the role played by the reset gate, showing that a significant redundancy with the update gate occurs. As a result, we propose to remove the former from the GRU design, leading to a more efficient and compact single-gate model. Second, we propose to replace hyperbolic tangent with ReLU activations. This variation couples well with batch normalization and could help the model learn long-term dependencies without numerical issues. Results show that the proposed architecture, called Light GRU (Li-GRU), not only reduces the per-epoch training time by more than 30% over a standard GRU, but also consistently improves the recognition accuracy across different tasks, input features, noisy conditions, as well as across different ASR paradigms, ranging from standard DNN-HMM speech recognizers to end-to-end CTC models.
* Copyright 2018 IEEE
Learning Independent Features with Adversarial Nets for Non-linear ICA
Oct 13, 2017



Reliable measures of statistical dependence could be useful tools for learning independent features and performing tasks like source separation using Independent Component Analysis (ICA). Unfortunately, many of such measures, like the mutual information, are hard to estimate and optimize directly. We propose to learn independent features with adversarial objectives which optimize such measures implicitly. These objectives compare samples from the joint distribution and the product of the marginals without the need to compute any probability densities. We also propose two methods for obtaining samples from the product of the marginals using either a simple resampling trick or a separate parametric distribution. Our experiments show that this strategy can easily be applied to different types of model architectures and solve both linear and non-linear ICA problems.
Improving speech recognition by revising gated recurrent units
Sep 29, 2017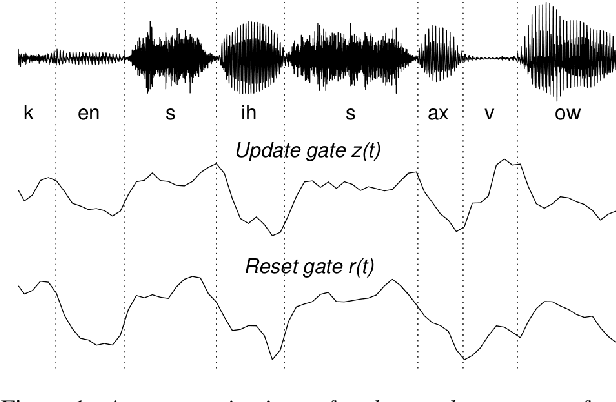
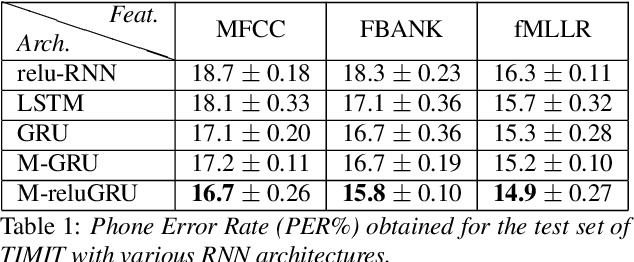
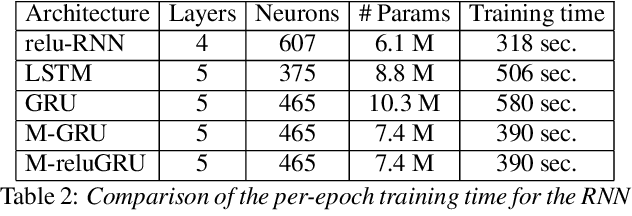
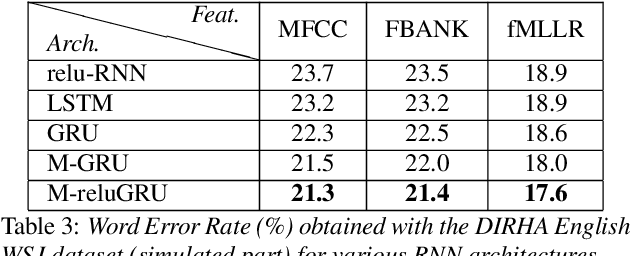
Speech recognition is largely taking advantage of deep learning, showing that substantial benefits can be obtained by modern Recurrent Neural Networks (RNNs). The most popular RNNs are Long Short-Term Memory (LSTMs), which typically reach state-of-the-art performance in many tasks thanks to their ability to learn long-term dependencies and robustness to vanishing gradients. Nevertheless, LSTMs have a rather complex design with three multiplicative gates, that might impair their efficient implementation. An attempt to simplify LSTMs has recently led to Gated Recurrent Units (GRUs), which are based on just two multiplicative gates. This paper builds on these efforts by further revising GRUs and proposing a simplified architecture potentially more suitable for speech recognition. The contribution of this work is two-fold. First, we suggest to remove the reset gate in the GRU design, resulting in a more efficient single-gate architecture. Second, we propose to replace tanh with ReLU activations in the state update equations. Results show that, in our implementation, the revised architecture reduces the per-epoch training time with more than 30% and consistently improves recognition performance across different tasks, input features, and noisy conditions when compared to a standard GRU.
Batch-normalized joint training for DNN-based distant speech recognition
Mar 24, 2017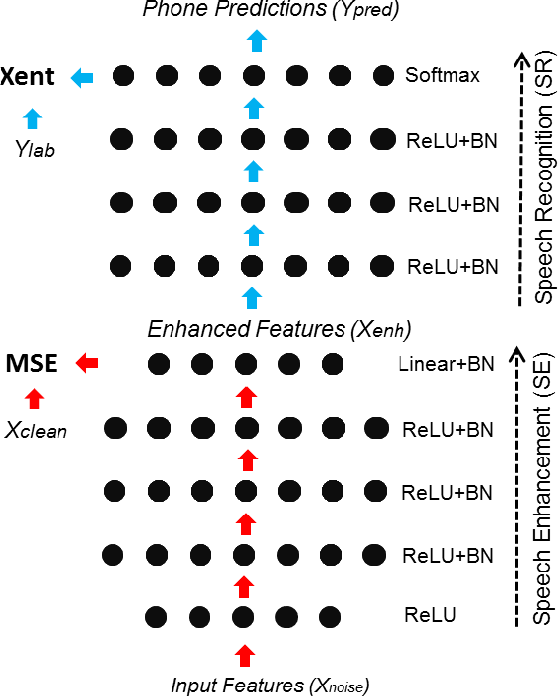

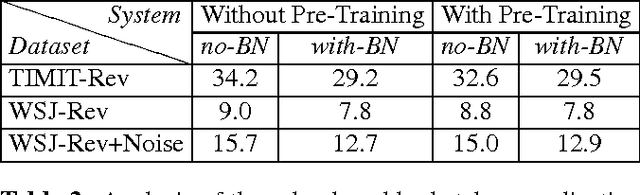
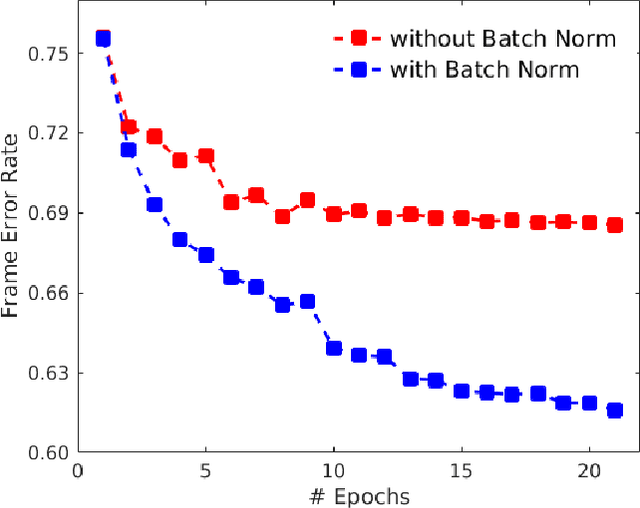
Improving distant speech recognition is a crucial step towards flexible human-machine interfaces. Current technology, however, still exhibits a lack of robustness, especially when adverse acoustic conditions are met. Despite the significant progress made in the last years on both speech enhancement and speech recognition, one potential limitation of state-of-the-art technology lies in composing modules that are not well matched because they are not trained jointly. To address this concern, a promising approach consists in concatenating a speech enhancement and a speech recognition deep neural network and to jointly update their parameters as if they were within a single bigger network. Unfortunately, joint training can be difficult because the output distribution of the speech enhancement system may change substantially during the optimization procedure. The speech recognition module would have to deal with an input distribution that is non-stationary and unnormalized. To mitigate this issue, we propose a joint training approach based on a fully batch-normalized architecture. Experiments, conducted using different datasets, tasks and acoustic conditions, revealed that the proposed framework significantly overtakes other competitive solutions, especially in challenging environments.
A network of deep neural networks for distant speech recognition
Mar 23, 2017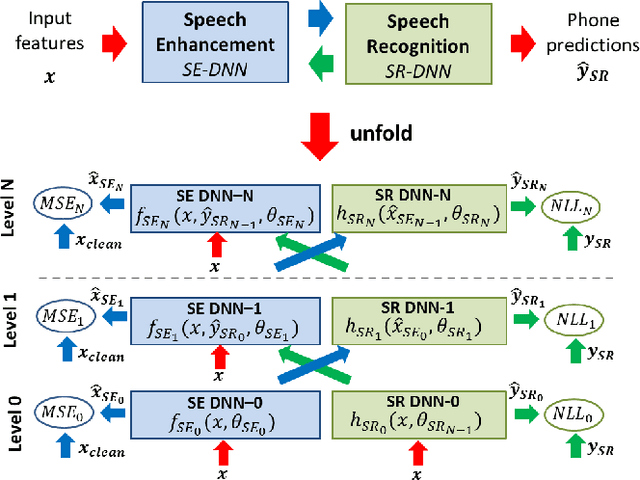

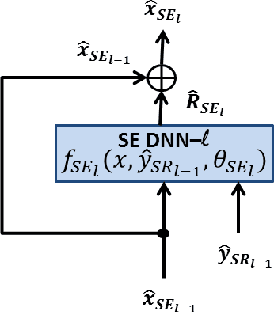

Despite the remarkable progress recently made in distant speech recognition, state-of-the-art technology still suffers from a lack of robustness, especially when adverse acoustic conditions characterized by non-stationary noises and reverberation are met. A prominent limitation of current systems lies in the lack of matching and communication between the various technologies involved in the distant speech recognition process. The speech enhancement and speech recognition modules are, for instance, often trained independently. Moreover, the speech enhancement normally helps the speech recognizer, but the output of the latter is not commonly used, in turn, to improve the speech enhancement. To address both concerns, we propose a novel architecture based on a network of deep neural networks, where all the components are jointly trained and better cooperate with each other thanks to a full communication scheme between them. Experiments, conducted using different datasets, tasks and acoustic conditions, revealed that the proposed framework can overtake other competitive solutions, including recent joint training approaches.