 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSee it to Place it: Evolving Macro Placements with Vision-Language Models
Mar 30, 2026We propose using Vision-Language Models (VLMs) for macro placement in chip floorplanning, a complex optimization task that has recently shown promising advancements through machine learning methods. Because human designers rely heavily on spatial reasoning to arrange components on the chip canvas, we hypothesize that VLMs with strong visual reasoning abilities can effectively complement existing learning-based approaches. We introduce VeoPlace (Visual Evolutionary Optimization Placement), a novel framework that uses a VLM, without any fine-tuning, to guide the actions of a base placer by constraining them to subregions of the chip canvas. The VLM proposals are iteratively optimized through an evolutionary search strategy with respect to resulting placement quality. On open-source benchmarks, VeoPlace outperforms the best prior learning-based approach on 9 of 10 benchmarks with peak wirelength reductions exceeding 32%. We further demonstrate that VeoPlace generalizes to analytical placers, improving DREAMPlace performance on all 8 evaluated benchmarks with gains up to 4.3%. Our approach opens new possibilities for electronic design automation tools that leverage foundation models to solve complex physical design problems.
Motion Control of High-Dimensional Musculoskeletal Systems with Hierarchical Model-Based Planning
May 13, 2025Controlling high-dimensional nonlinear systems, such as those found in biological and robotic applications, is challenging due to large state and action spaces. While deep reinforcement learning has achieved a number of successes in these domains, it is computationally intensive and time consuming, and therefore not suitable for solving large collections of tasks that require significant manual tuning. In this work, we introduce Model Predictive Control with Morphology-aware Proportional Control (MPC^2), a hierarchical model-based learning algorithm for zero-shot and near-real-time control of high-dimensional complex dynamical systems. MPC^2 uses a sampling-based model predictive controller for target posture planning, and enables robust control for high-dimensional tasks by incorporating a morphology-aware proportional controller for actuator coordination. The algorithm enables motion control of a high-dimensional human musculoskeletal model in a variety of motion tasks, such as standing, walking on different terrains, and imitating sports activities. The reward function of MPC^2 can be tuned via black-box optimization, drastically reducing the need for human-intensive reward engineering.
Scalable Bayesian Optimization via Focalized Sparse Gaussian Processes
Dec 29, 2024Bayesian optimization is an effective technique for black-box optimization, but its applicability is typically limited to low-dimensional and small-budget problems due to the cubic complexity of computing the Gaussian process (GP) surrogate. While various approximate GP models have been employed to scale Bayesian optimization to larger sample sizes, most suffer from overly-smooth estimation and focus primarily on problems that allow for large online samples. In this work, we argue that Bayesian optimization algorithms with sparse GPs can more efficiently allocate their representational power to relevant regions of the search space. To achieve this, we propose focalized GP, which leverages a novel variational loss function to achieve stronger local prediction, as well as FocalBO, which hierarchically optimizes the focalized GP acquisition function over progressively smaller search spaces. Experimental results demonstrate that FocalBO can efficiently leverage large amounts of offline and online data to achieve state-of-the-art performance on robot morphology design and to control a 585-dimensional musculoskeletal system.
Inference-Aware Fine-Tuning for Best-of-N Sampling in Large Language Models
Dec 18, 2024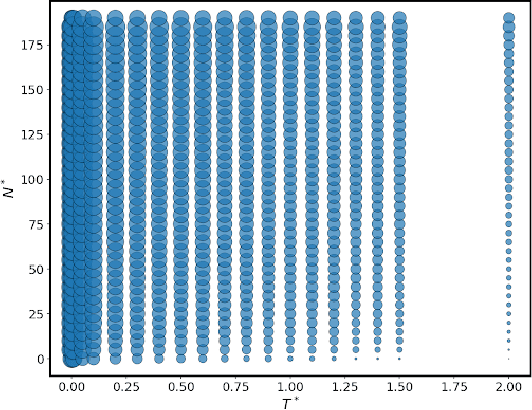
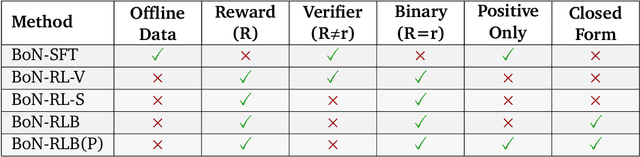
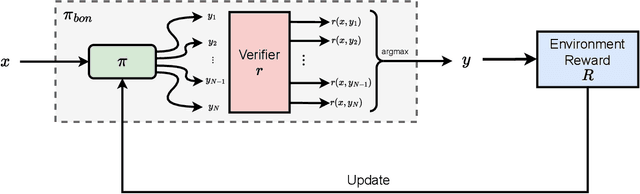
Recent studies have indicated that effectively utilizing inference-time compute is crucial for attaining better performance from large language models (LLMs). In this work, we propose a novel inference-aware fine-tuning paradigm, in which the model is fine-tuned in a manner that directly optimizes the performance of the inference-time strategy. We study this paradigm using the simple yet effective Best-of-N (BoN) inference strategy, in which a verifier selects the best out of a set of LLM-generated responses. We devise the first imitation learning and reinforcement learning~(RL) methods for BoN-aware fine-tuning, overcoming the challenging, non-differentiable argmax operator within BoN. We empirically demonstrate that our BoN-aware models implicitly learn a meta-strategy that interleaves best responses with more diverse responses that might be better suited to a test-time input -- a process reminiscent of the exploration-exploitation trade-off in RL. Our experiments demonstrate the effectiveness of BoN-aware fine-tuning in terms of improved performance and inference-time compute. In particular, we show that our methods improve the Bo32 performance of Gemma 2B on Hendrycks MATH from 26.8% to 30.8%, and pass@32 from 60.0% to 67.0%, as well as the pass@16 on HumanEval from 61.6% to 67.1%.
Learning to Learn Faster from Human Feedback with Language Model Predictive Control
Feb 18, 2024



Large language models (LLMs) have been shown to exhibit a wide range of capabilities, such as writing robot code from language commands -- enabling non-experts to direct robot behaviors, modify them based on feedback, or compose them to perform new tasks. However, these capabilities (driven by in-context learning) are limited to short-term interactions, where users' feedback remains relevant for only as long as it fits within the context size of the LLM, and can be forgotten over longer interactions. In this work, we investigate fine-tuning the robot code-writing LLMs, to remember their in-context interactions and improve their teachability i.e., how efficiently they adapt to human inputs (measured by average number of corrections before the user considers the task successful). Our key observation is that when human-robot interactions are formulated as a partially observable Markov decision process (in which human language inputs are observations, and robot code outputs are actions), then training an LLM to complete previous interactions can be viewed as training a transition dynamics model -- that can be combined with classic robotics techniques such as model predictive control (MPC) to discover shorter paths to success. This gives rise to Language Model Predictive Control (LMPC), a framework that fine-tunes PaLM 2 to improve its teachability on 78 tasks across 5 robot embodiments -- improving non-expert teaching success rates of unseen tasks by 26.9% while reducing the average number of human corrections from 2.4 to 1.9. Experiments show that LMPC also produces strong meta-learners, improving the success rate of in-context learning new tasks on unseen robot embodiments and APIs by 31.5%. See videos, code, and demos at: https://robot-teaching.github.io/.
Kepler: Robust Learning for Faster Parametric Query Optimization
Jun 11, 2023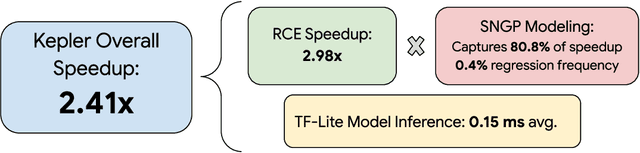

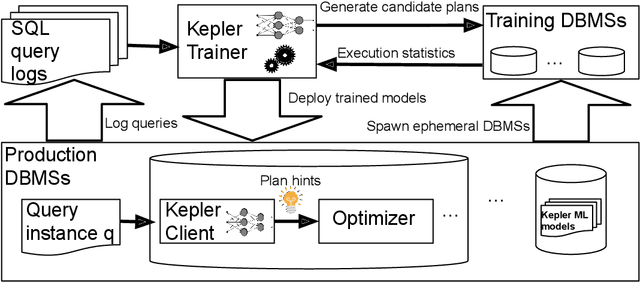
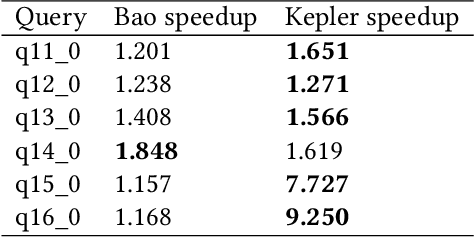
Most existing parametric query optimization (PQO) techniques rely on traditional query optimizer cost models, which are often inaccurate and result in suboptimal query performance. We propose Kepler, an end-to-end learning-based approach to PQO that demonstrates significant speedups in query latency over a traditional query optimizer. Central to our method is Row Count Evolution (RCE), a novel plan generation algorithm based on perturbations in the sub-plan cardinality space. While previous approaches require accurate cost models, we bypass this requirement by evaluating candidate plans via actual execution data and training an ML model to predict the fastest plan given parameter binding values. Our models leverage recent advances in neural network uncertainty in order to robustly predict faster plans while avoiding regressions in query performance. Experimentally, we show that Kepler achieves significant improvements in query runtime on multiple datasets on PostgreSQL.
Barkour: Benchmarking Animal-level Agility with Quadruped Robots
May 24, 2023
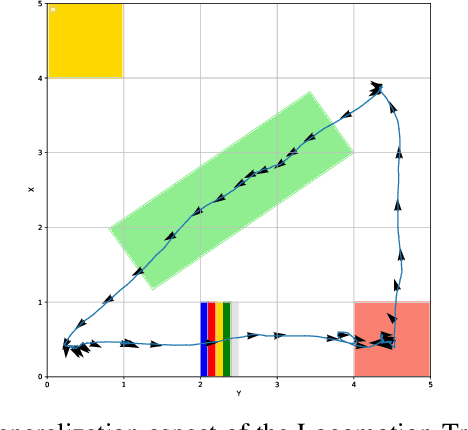
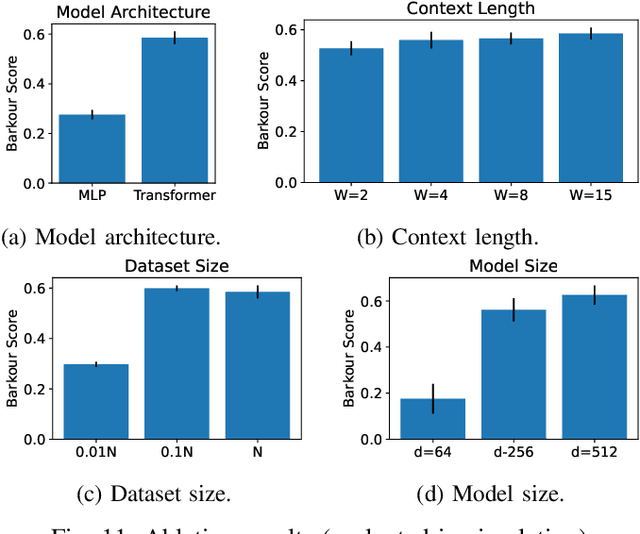

Animals have evolved various agile locomotion strategies, such as sprinting, leaping, and jumping. There is a growing interest in developing legged robots that move like their biological counterparts and show various agile skills to navigate complex environments quickly. Despite the interest, the field lacks systematic benchmarks to measure the performance of control policies and hardware in agility. We introduce the Barkour benchmark, an obstacle course to quantify agility for legged robots. Inspired by dog agility competitions, it consists of diverse obstacles and a time based scoring mechanism. This encourages researchers to develop controllers that not only move fast, but do so in a controllable and versatile way. To set strong baselines, we present two methods for tackling the benchmark. In the first approach, we train specialist locomotion skills using on-policy reinforcement learning methods and combine them with a high-level navigation controller. In the second approach, we distill the specialist skills into a Transformer-based generalist locomotion policy, named Locomotion-Transformer, that can handle various terrains and adjust the robot's gait based on the perceived environment and robot states. Using a custom-built quadruped robot, we demonstrate that our method can complete the course at half the speed of a dog. We hope that our work represents a step towards creating controllers that enable robots to reach animal-level agility.
No-Regret Reinforcement Learning with Heavy-Tailed Rewards
Feb 25, 2021
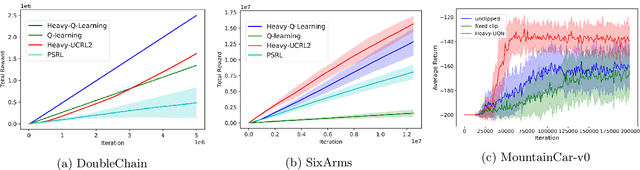
Reinforcement learning algorithms typically assume rewards to be sampled from light-tailed distributions, such as Gaussian or bounded. However, a wide variety of real-world systems generate rewards that follow heavy-tailed distributions. We consider such scenarios in the setting of undiscounted reinforcement learning. By constructing a lower bound, we show that the difficulty of learning heavy-tailed rewards asymptotically dominates the difficulty of learning transition probabilities. Leveraging techniques from robust mean estimation, we propose Heavy-UCRL2 and Heavy-Q-Learning, and show that they achieve near-optimal regret bounds in this setting. Our algorithms also naturally generalize to deep reinforcement learning applications; we instantiate Heavy-DQN as an example of this. We demonstrate that all of our algorithms outperform baselines on both synthetic MDPs and standard RL benchmarks.
Stagewise Safe Bayesian Optimization with Gaussian Processes
Jun 20, 2018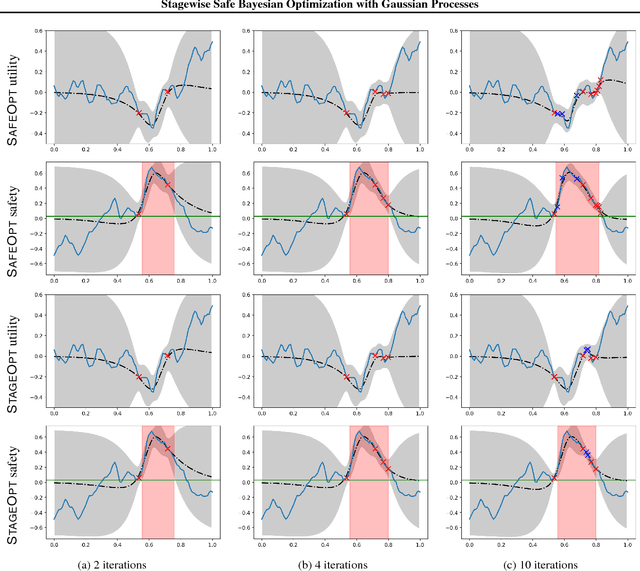
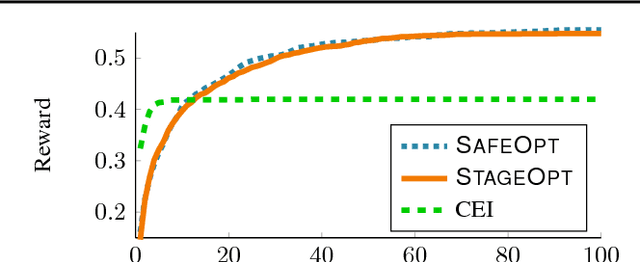
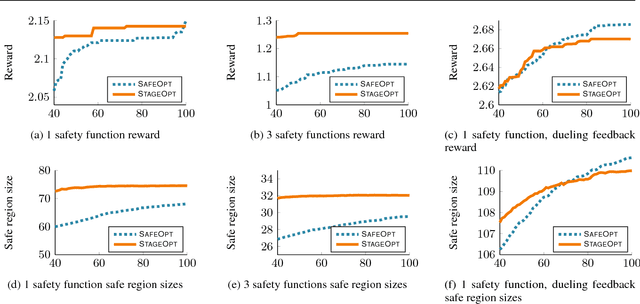
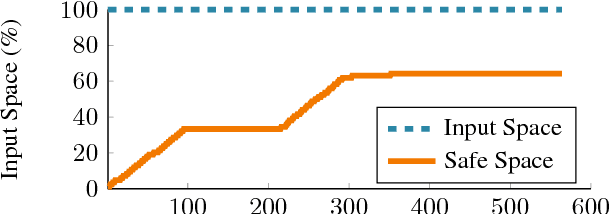
Enforcing safety is a key aspect of many problems pertaining to sequential decision making under uncertainty, which require the decisions made at every step to be both informative of the optimal decision and also safe. For example, we value both efficacy and comfort in medical therapy, and efficiency and safety in robotic control. We consider this problem of optimizing an unknown utility function with absolute feedback or preference feedback subject to unknown safety constraints. We develop an efficient safe Bayesian optimization algorithm, StageOpt, that separates safe region expansion and utility function maximization into two distinct stages. Compared to existing approaches which interleave between expansion and optimization, we show that StageOpt is more efficient and naturally applicable to a broader class of problems. We provide theoretical guarantees for both the satisfaction of safety constraints as well as convergence to the optimal utility value. We evaluate StageOpt on both a variety of synthetic experiments, as well as in clinical practice. We demonstrate that StageOpt is more effective than existing safe optimization approaches, and is able to safely and effectively optimize spinal cord stimulation therapy in our clinical experiments.
Multi-dueling Bandits with Dependent Arms
Apr 29, 2017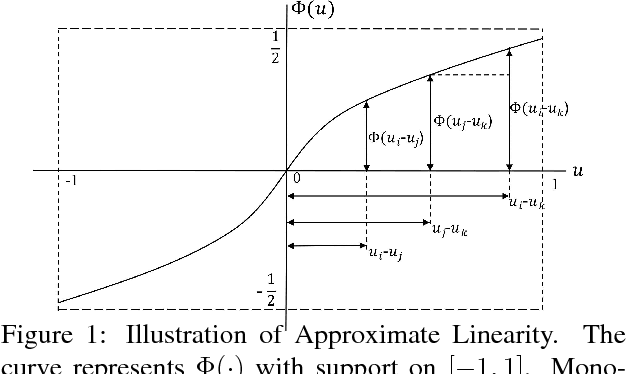

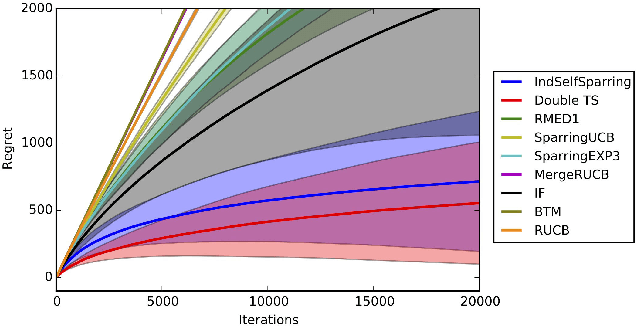
The dueling bandits problem is an online learning framework for learning from pairwise preference feedback, and is particularly well-suited for modeling settings that elicit subjective or implicit human feedback. In this paper, we study the problem of multi-dueling bandits with dependent arms, which extends the original dueling bandits setting by simultaneously dueling multiple arms as well as modeling dependencies between arms. These extensions capture key characteristics found in many real-world applications, and allow for the opportunity to develop significantly more efficient algorithms than were possible in the original setting. We propose the \selfsparring algorithm, which reduces the multi-dueling bandits problem to a conventional bandit setting that can be solved using a stochastic bandit algorithm such as Thompson Sampling, and can naturally model dependencies using a Gaussian process prior. We present a no-regret analysis for multi-dueling setting, and demonstrate the effectiveness of our algorithm empirically on a wide range of simulation settings.