 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGPT-4o System Card
Oct 25, 2024GPT-4o is an autoregressive omni model that accepts as input any combination of text, audio, image, and video, and generates any combination of text, audio, and image outputs. It's trained end-to-end across text, vision, and audio, meaning all inputs and outputs are processed by the same neural network. GPT-4o can respond to audio inputs in as little as 232 milliseconds, with an average of 320 milliseconds, which is similar to human response time in conversation. It matches GPT-4 Turbo performance on text in English and code, with significant improvement on text in non-English languages, while also being much faster and 50\% cheaper in the API. GPT-4o is especially better at vision and audio understanding compared to existing models. In line with our commitment to building AI safely and consistent with our voluntary commitments to the White House, we are sharing the GPT-4o System Card, which includes our Preparedness Framework evaluations. In this System Card, we provide a detailed look at GPT-4o's capabilities, limitations, and safety evaluations across multiple categories, focusing on speech-to-speech while also evaluating text and image capabilities, and measures we've implemented to ensure the model is safe and aligned. We also include third-party assessments on dangerous capabilities, as well as discussion of potential societal impacts of GPT-4o's text and vision capabilities.
Pretraining Data Mixtures Enable Narrow Model Selection Capabilities in Transformer Models
Nov 01, 2023
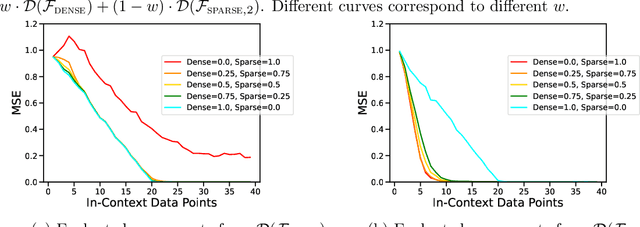
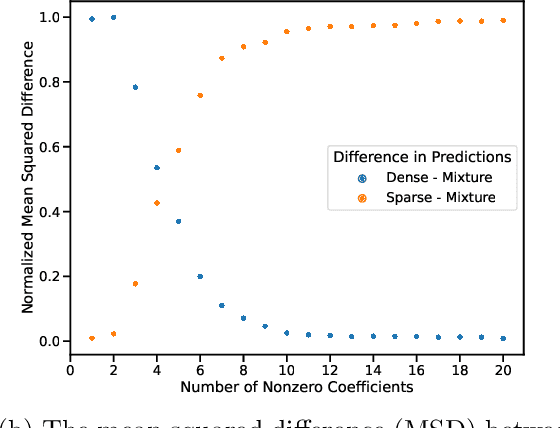
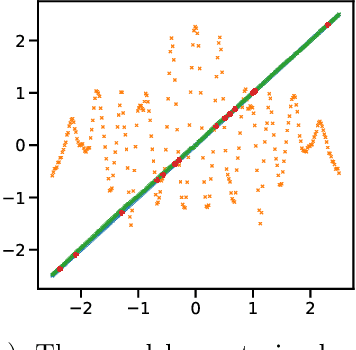
Transformer models, notably large language models (LLMs), have the remarkable ability to perform in-context learning (ICL) -- to perform new tasks when prompted with unseen input-output examples without any explicit model training. In this work, we study how effectively transformers can bridge between their pretraining data mixture, comprised of multiple distinct task families, to identify and learn new tasks in-context which are both inside and outside the pretraining distribution. Building on previous work, we investigate this question in a controlled setting, where we study transformer models trained on sequences of $(x, f(x))$ pairs rather than natural language. Our empirical results show transformers demonstrate near-optimal unsupervised model selection capabilities, in their ability to first in-context identify different task families and in-context learn within them when the task families are well-represented in their pretraining data. However when presented with tasks or functions which are out-of-domain of their pretraining data, we demonstrate various failure modes of transformers and degradation of their generalization for even simple extrapolation tasks. Together our results highlight that the impressive ICL abilities of high-capacity sequence models may be more closely tied to the coverage of their pretraining data mixtures than inductive biases that create fundamental generalization capabilities.
Kepler: Robust Learning for Faster Parametric Query Optimization
Jun 11, 2023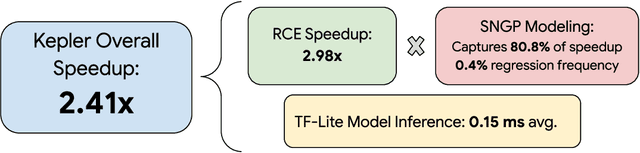

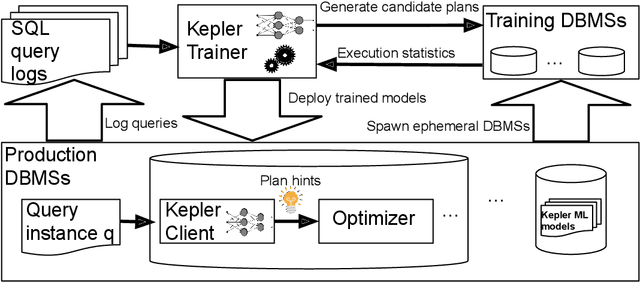
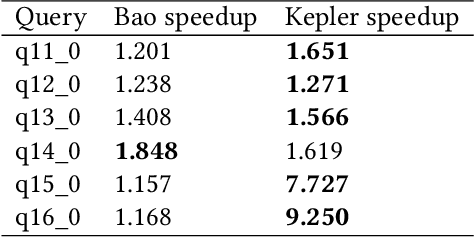
Most existing parametric query optimization (PQO) techniques rely on traditional query optimizer cost models, which are often inaccurate and result in suboptimal query performance. We propose Kepler, an end-to-end learning-based approach to PQO that demonstrates significant speedups in query latency over a traditional query optimizer. Central to our method is Row Count Evolution (RCE), a novel plan generation algorithm based on perturbations in the sub-plan cardinality space. While previous approaches require accurate cost models, we bypass this requirement by evaluating candidate plans via actual execution data and training an ML model to predict the fastest plan given parameter binding values. Our models leverage recent advances in neural network uncertainty in order to robustly predict faster plans while avoiding regressions in query performance. Experimentally, we show that Kepler achieves significant improvements in query runtime on multiple datasets on PostgreSQL.
Learned Indexes for a Google-scale Disk-based Database
Dec 23, 2020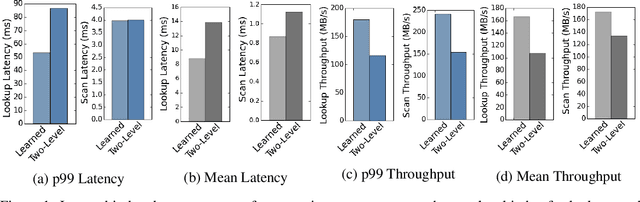
There is great excitement about learned index structures, but understandable skepticism about the practicality of a new method uprooting decades of research on B-Trees. In this paper, we work to remove some of that uncertainty by demonstrating how a learned index can be integrated in a distributed, disk-based database system: Google's Bigtable. We detail several design decisions we made to integrate learned indexes in Bigtable. Our results show that integrating learned index significantly improves the end-to-end read latency and throughput for Bigtable.