 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGemini Robotics: Bringing AI into the Physical World
Mar 25, 2025Recent advancements in large multimodal models have led to the emergence of remarkable generalist capabilities in digital domains, yet their translation to physical agents such as robots remains a significant challenge. This report introduces a new family of AI models purposefully designed for robotics and built upon the foundation of Gemini 2.0. We present Gemini Robotics, an advanced Vision-Language-Action (VLA) generalist model capable of directly controlling robots. Gemini Robotics executes smooth and reactive movements to tackle a wide range of complex manipulation tasks while also being robust to variations in object types and positions, handling unseen environments as well as following diverse, open vocabulary instructions. We show that with additional fine-tuning, Gemini Robotics can be specialized to new capabilities including solving long-horizon, highly dexterous tasks, learning new short-horizon tasks from as few as 100 demonstrations and adapting to completely novel robot embodiments. This is made possible because Gemini Robotics builds on top of the Gemini Robotics-ER model, the second model we introduce in this work. Gemini Robotics-ER (Embodied Reasoning) extends Gemini's multimodal reasoning capabilities into the physical world, with enhanced spatial and temporal understanding. This enables capabilities relevant to robotics including object detection, pointing, trajectory and grasp prediction, as well as multi-view correspondence and 3D bounding box predictions. We show how this novel combination can support a variety of robotics applications. We also discuss and address important safety considerations related to this new class of robotics foundation models. The Gemini Robotics family marks a substantial step towards developing general-purpose robots that realizes AI's potential in the physical world.
Proc4Gem: Foundation models for physical agency through procedural generation
Mar 11, 2025



In robot learning, it is common to either ignore the environment semantics, focusing on tasks like whole-body control which only require reasoning about robot-environment contacts, or conversely to ignore contact dynamics, focusing on grounding high-level movement in vision and language. In this work, we show that advances in generative modeling, photorealistic rendering, and procedural generation allow us to tackle tasks requiring both. By generating contact-rich trajectories with accurate physics in semantically-diverse simulations, we can distill behaviors into large multimodal models that directly transfer to the real world: a system we call Proc4Gem. Specifically, we show that a foundation model, Gemini, fine-tuned on only simulation data, can be instructed in language to control a quadruped robot to push an object with its body to unseen targets in unseen real-world environments. Our real-world results demonstrate the promise of using simulation to imbue foundation models with physical agency. Videos can be found at our website: https://sites.google.com/view/proc4gem
Prosody for Intuitive Robotic Interface Design: It's Not What You Said, It's How You Said It
Mar 13, 2024

In this paper, we investigate the use of 'prosody' (the musical elements of speech) as a communicative signal for intuitive human-robot interaction interfaces. Our approach, rooted in Research through Design (RtD), examines the application of prosody in directing a quadruped robot navigation. We involved ten team members in an experiment to command a robot through an obstacle course using natural interaction. A human operator, serving as the robot's sensory and processing proxy, translated human communication into a basic set of navigation commands, effectively simulating an intuitive interface. During our analysis of interaction videos, when lexical and visual cues proved insufficient for accurate command interpretation, we turned to non-verbal auditory cues. Qualitative evidence suggests that participants intuitively relied on prosody to control robot navigation. We highlight specific distinct prosodic constructs that emerged from this preliminary exploration and discuss their pragmatic functions. This work contributes a discussion on the broader potential of prosody as a multifunctional communicative signal for designing future intuitive robotic interfaces, enabling lifelong learning and personalization in human-robot interaction.
Learning to Learn Faster from Human Feedback with Language Model Predictive Control
Feb 18, 2024



Large language models (LLMs) have been shown to exhibit a wide range of capabilities, such as writing robot code from language commands -- enabling non-experts to direct robot behaviors, modify them based on feedback, or compose them to perform new tasks. However, these capabilities (driven by in-context learning) are limited to short-term interactions, where users' feedback remains relevant for only as long as it fits within the context size of the LLM, and can be forgotten over longer interactions. In this work, we investigate fine-tuning the robot code-writing LLMs, to remember their in-context interactions and improve their teachability i.e., how efficiently they adapt to human inputs (measured by average number of corrections before the user considers the task successful). Our key observation is that when human-robot interactions are formulated as a partially observable Markov decision process (in which human language inputs are observations, and robot code outputs are actions), then training an LLM to complete previous interactions can be viewed as training a transition dynamics model -- that can be combined with classic robotics techniques such as model predictive control (MPC) to discover shorter paths to success. This gives rise to Language Model Predictive Control (LMPC), a framework that fine-tunes PaLM 2 to improve its teachability on 78 tasks across 5 robot embodiments -- improving non-expert teaching success rates of unseen tasks by 26.9% while reducing the average number of human corrections from 2.4 to 1.9. Experiments show that LMPC also produces strong meta-learners, improving the success rate of in-context learning new tasks on unseen robot embodiments and APIs by 31.5%. See videos, code, and demos at: https://robot-teaching.github.io/.
Barkour: Benchmarking Animal-level Agility with Quadruped Robots
May 24, 2023
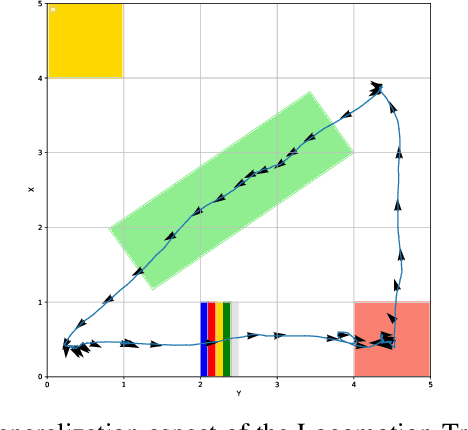
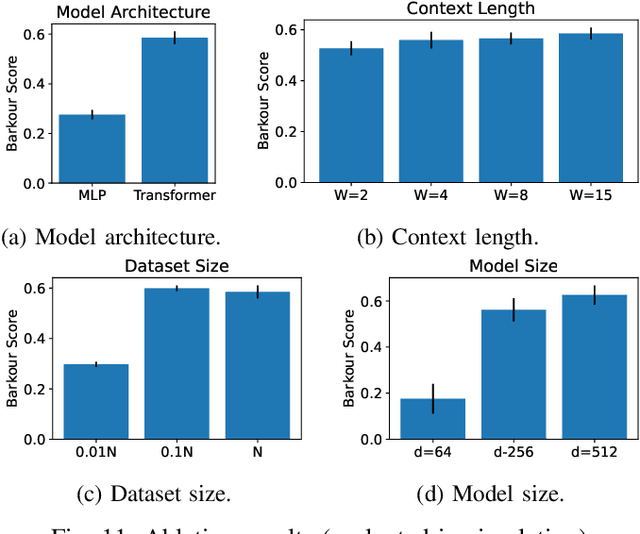

Animals have evolved various agile locomotion strategies, such as sprinting, leaping, and jumping. There is a growing interest in developing legged robots that move like their biological counterparts and show various agile skills to navigate complex environments quickly. Despite the interest, the field lacks systematic benchmarks to measure the performance of control policies and hardware in agility. We introduce the Barkour benchmark, an obstacle course to quantify agility for legged robots. Inspired by dog agility competitions, it consists of diverse obstacles and a time based scoring mechanism. This encourages researchers to develop controllers that not only move fast, but do so in a controllable and versatile way. To set strong baselines, we present two methods for tackling the benchmark. In the first approach, we train specialist locomotion skills using on-policy reinforcement learning methods and combine them with a high-level navigation controller. In the second approach, we distill the specialist skills into a Transformer-based generalist locomotion policy, named Locomotion-Transformer, that can handle various terrains and adjust the robot's gait based on the perceived environment and robot states. Using a custom-built quadruped robot, we demonstrate that our method can complete the course at half the speed of a dog. We hope that our work represents a step towards creating controllers that enable robots to reach animal-level agility.
From Pixels to Legs: Hierarchical Learning of Quadruped Locomotion
Nov 23, 2020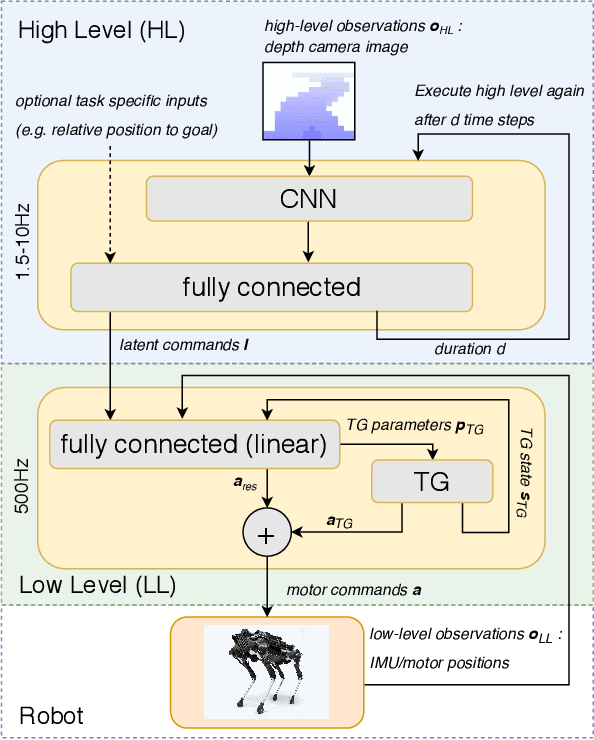

Legged robots navigating crowded scenes and complex terrains in the real world are required to execute dynamic leg movements while processing visual input for obstacle avoidance and path planning. We show that a quadruped robot can acquire both of these skills by means of hierarchical reinforcement learning (HRL). By virtue of their hierarchical structure, our policies learn to implicitly break down this joint problem by concurrently learning High Level (HL) and Low Level (LL) neural network policies. These two levels are connected by a low dimensional hidden layer, which we call latent command. HL receives a first-person camera view, whereas LL receives the latent command from HL and the robot's on-board sensors to control its actuators. We train policies to walk in two different environments: a curved cliff and a maze. We show that hierarchical policies can concurrently learn to locomote and navigate in these environments, and show they are more efficient than non-hierarchical neural network policies. This architecture also allows for knowledge reuse across tasks. LL networks trained on one task can be transferred to a new task in a new environment. Finally HL, which processes camera images, can be evaluated at much lower and varying frequencies compared to LL, thus reducing computation times and bandwidth requirements.
Learning Agile Locomotion Skills with a Mentor
Nov 11, 2020
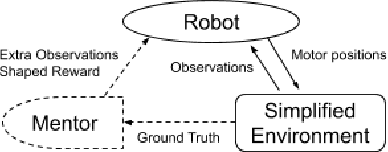
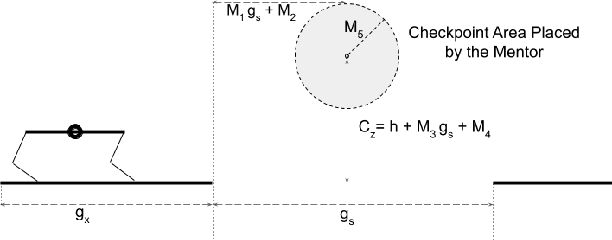
Developing agile behaviors for legged robots remains a challenging problem. While deep reinforcement learning is a promising approach, learning truly agile behaviors typically requires tedious reward shaping and careful curriculum design. We formulate agile locomotion as a multi-stage learning problem in which a mentor guides the agent throughout the training. The mentor is optimized to place a checkpoint to guide the movement of the robot's center of mass while the student (i.e. the robot) learns to reach these checkpoints. Once the student can solve the task, we teach the student to perform the task without the mentor. We evaluate our proposed learning system with a simulated quadruped robot on a course consisting of randomly generated gaps and hurdles. Our method significantly outperforms a single-stage RL baseline without a mentor, and the quadruped robot can agilely run and jump across gaps and obstacles. Finally, we present a detailed analysis of the learned behaviors' feasibility and efficiency.
Rapidly Adaptable Legged Robots via Evolutionary Meta-Learning
Mar 02, 2020

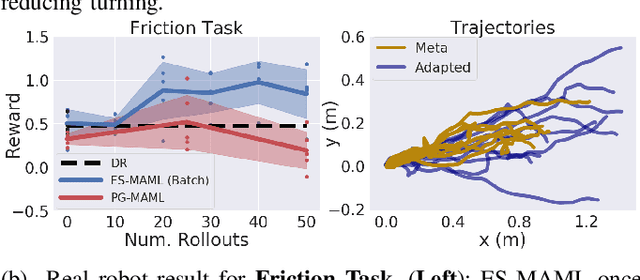
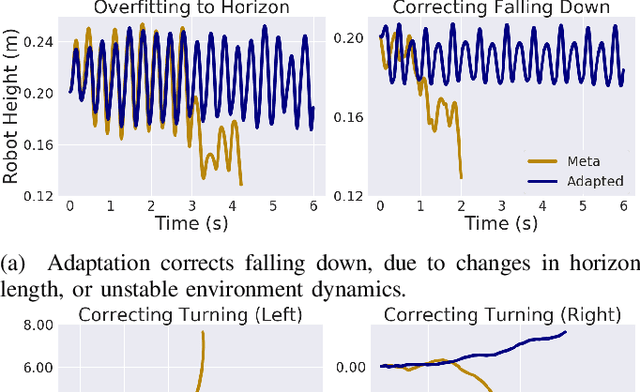
Learning adaptable policies is crucial for robots to operate autonomously in our complex and quickly changing world. In this work, we present a new meta-learning method that allows robots to quickly adapt to changes in dynamics. In contrast to gradient-based meta-learning algorithms that rely on second-order gradient estimation, we introduce a more noise-tolerant Batch Hill-Climbing adaptation operator and combine it with meta-learning based on evolutionary strategies. Our method significantly improves adaptation to changes in dynamics in high noise settings, which are common in robotics applications. We validate our approach on a quadruped robot that learns to walk while subject to changes in dynamics. We observe that our method significantly outperforms prior gradient-based approaches, enabling the robot to adapt its policy to changes based on less than 3 minutes of real data.
Policies Modulating Trajectory Generators
Oct 07, 2019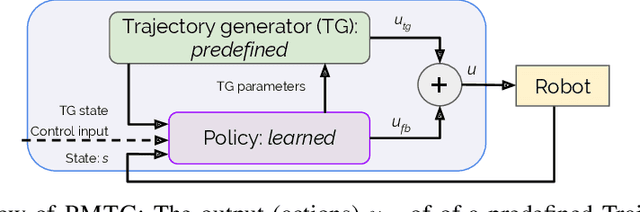
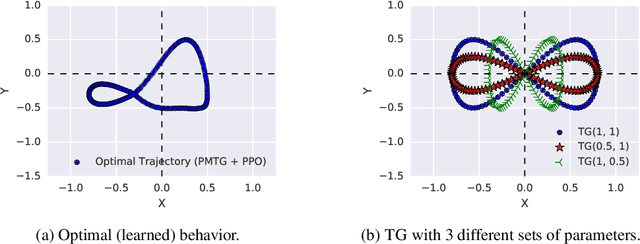
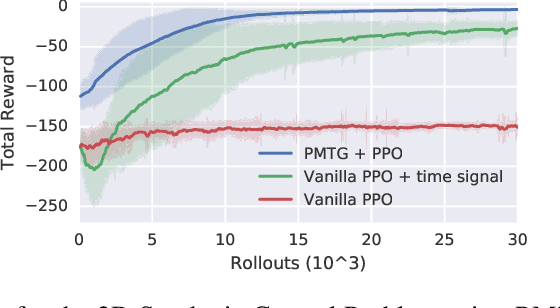
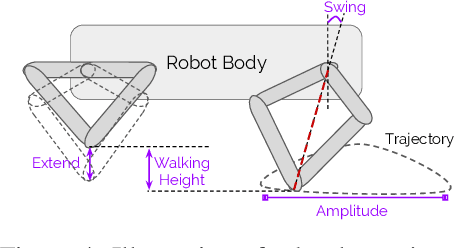
We propose an architecture for learning complex controllable behaviors by having simple Policies Modulate Trajectory Generators (PMTG), a powerful combination that can provide both memory and prior knowledge to the controller. The result is a flexible architecture that is applicable to a class of problems with periodic motion for which one has an insight into the class of trajectories that might lead to a desired behavior. We illustrate the basics of our architecture using a synthetic control problem, then go on to learn speed-controlled locomotion for a quadrupedal robot by using Deep Reinforcement Learning and Evolutionary Strategies. We demonstrate that a simple linear policy, when paired with a parametric Trajectory Generator for quadrupedal gaits, can induce walking behaviors with controllable speed from 4-dimensional IMU observations alone, and can be learned in under 1000 rollouts. We also transfer these policies to a real robot and show locomotion with controllable forward velocity.
Data Efficient Reinforcement Learning for Legged Robots
Jul 08, 2019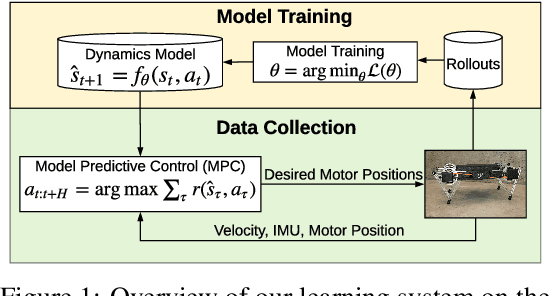
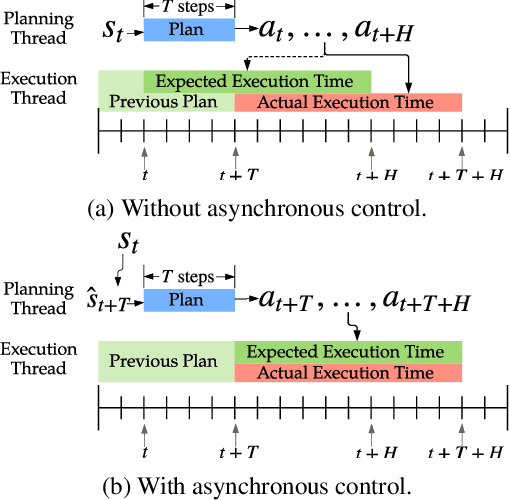
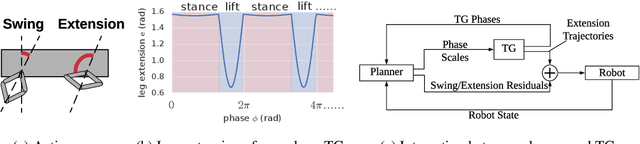
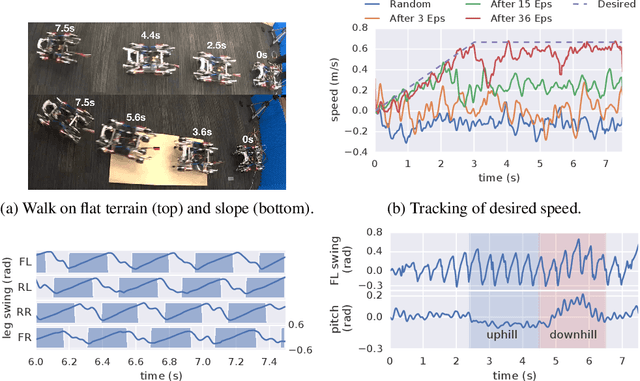
We present a model-based framework for robot locomotion that achieves walking based on only 4.5 minutes (45,000 control steps) of data collected on a quadruped robot. To accurately model the robot's dynamics over a long horizon, we introduce a loss function that tracks the model's prediction over multiple timesteps. We adapt model predictive control to account for planning latency, which allows the learned model to be used for real time control. Additionally, to ensure safe exploration during model learning, we embed prior knowledge of leg trajectories into the action space. The resulting system achieves fast and robust locomotion. Unlike model-free methods, which optimize for a particular task, our planner can use the same learned dynamics for various tasks, simply by changing the reward function. To the best of our knowledge, our approach is more than an order of magnitude more sample efficient than current model-free methods.