 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentCollab: A Self-Evaluation-Driven Collaboration Paradigm for Efficient LLM Agents
Mar 27, 2026Autonomous agents powered by large language models (LLMs) perform complex tasks through long-horizon reasoning and tool interaction, where a fundamental trade-off arises between execution efficiency and reasoning robustness. Models at different capability-cost levels offer complementary advantages: lower-cost models enable fast execution but may struggle on difficult reasoning segments, while stronger models provide more robust reasoning at higher computational cost. We present AgentCollab, a self-driven collaborative inference framework that dynamically coordinates models with different reasoning capacities during agent execution. Instead of relying on external routing modules, the framework uses the agent's own self-reflection signal to determine whether the current reasoning trajectory is making meaningful progress, and escalates control to a stronger reasoning tier only when necessary. To further stabilize long-horizon execution, we introduce a difficulty-aware cumulative escalation strategy that allocates additional reasoning budget based on recent failure signals. In our experiments, we instantiate this framework using a two-level small-large model setting. Experiments on diverse multi-step agent benchmarks show that AgentCollab consistently improves the accuracy-efficiency Pareto frontier of LLM agents.
Ada-FCN: Adaptive Frequency-Coupled Network for fMRI-Based Brain Disorder Classification
Nov 16, 2025Resting-state fMRI has become a valuable tool for classifying brain disorders and constructing brain functional connectivity networks by tracking BOLD signals across brain regions. However, existing mod els largely neglect the multi-frequency nature of neuronal oscillations, treating BOLD signals as monolithic time series. This overlooks the cru cial fact that neurological disorders often manifest as disruptions within specific frequency bands, limiting diagnostic sensitivity and specificity. While some methods have attempted to incorporate frequency informa tion, they often rely on predefined frequency bands, which may not be optimal for capturing individual variability or disease-specific alterations. To address this, we propose a novel framework featuring Adaptive Cas cade Decomposition to learn task-relevant frequency sub-bands for each brain region and Frequency-Coupled Connectivity Learning to capture both intra- and nuanced cross-band interactions in a unified functional network. This unified network informs a novel message-passing mecha nism within our Unified-GCN, generating refined node representations for diagnostic prediction. Experimental results on the ADNI and ABIDE datasets demonstrate superior performance over existing methods. The code is available at https://github.com/XXYY20221234/Ada-FCN.
* MICCAI2025
SACNet: A Spatially Adaptive Convolution Network for 2D Multi-organ Medical Segmentation
Jul 14, 2024



Multi-organ segmentation in medical image analysis is crucial for diagnosis and treatment planning. However, many factors complicate the task, including variability in different target categories and interference from complex backgrounds. In this paper, we utilize the knowledge of Deformable Convolution V3 (DCNv3) and multi-object segmentation to optimize our Spatially Adaptive Convolution Network (SACNet) in three aspects: feature extraction, model architecture, and loss constraint, simultaneously enhancing the perception of different segmentation targets. Firstly, we propose the Adaptive Receptive Field Module (ARFM), which combines DCNv3 with a series of customized block-level and architecture-level designs similar to transformers. This module can capture the unique features of different organs by adaptively adjusting the receptive field according to various targets. Secondly, we utilize ARFM as building blocks to construct the encoder-decoder of SACNet and partially share parameters between the encoder and decoder, making the network wider rather than deeper. This design achieves a shared lightweight decoder and a more parameter-efficient and effective framework. Lastly, we propose a novel continuity dynamic adjustment loss function, based on t-vMF dice loss and cross-entropy loss, to better balance easy and complex classes in segmentation. Experiments on 3D slice datasets from ACDC and Synapse demonstrate that SACNet delivers superior segmentation performance in multi-organ segmentation tasks compared to several existing methods.
Robotic Table Tennis: A Case Study into a High Speed Learning System
Sep 06, 2023



We present a deep-dive into a real-world robotic learning system that, in previous work, was shown to be capable of hundreds of table tennis rallies with a human and has the ability to precisely return the ball to desired targets. This system puts together a highly optimized perception subsystem, a high-speed low-latency robot controller, a simulation paradigm that can prevent damage in the real world and also train policies for zero-shot transfer, and automated real world environment resets that enable autonomous training and evaluation on physical robots. We complement a complete system description, including numerous design decisions that are typically not widely disseminated, with a collection of studies that clarify the importance of mitigating various sources of latency, accounting for training and deployment distribution shifts, robustness of the perception system, sensitivity to policy hyper-parameters, and choice of action space. A video demonstrating the components of the system and details of experimental results can be found at https://youtu.be/uFcnWjB42I0.
ES-ENAS: Combining Evolution Strategies with Neural Architecture Search at No Extra Cost for Reinforcement Learning
Jan 19, 2021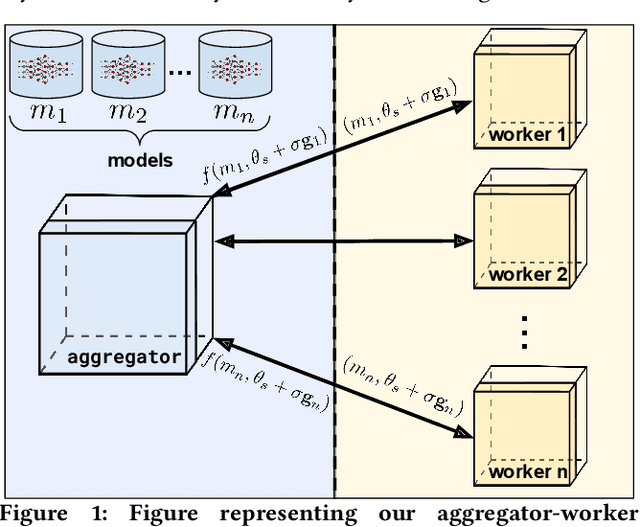

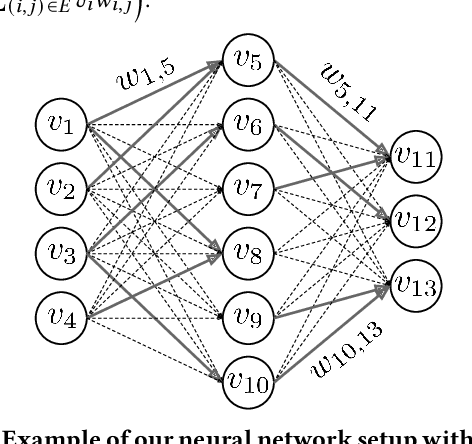
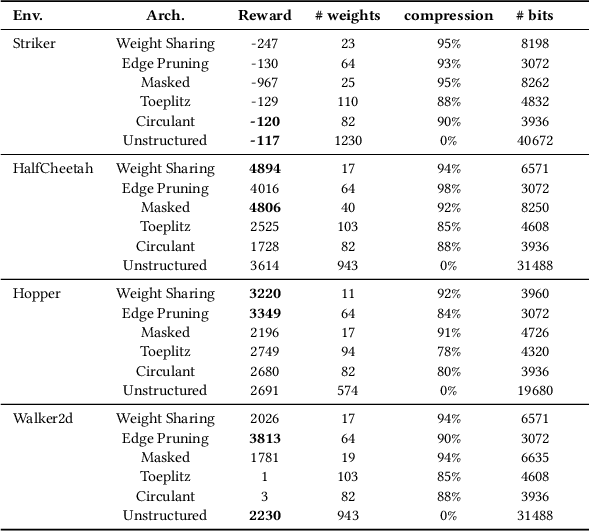
We introduce ES-ENAS, a simple neural architecture search (NAS) algorithm for the purpose of reinforcement learning (RL) policy design, by combining Evolutionary Strategies (ES) and Efficient NAS (ENAS) in a highly scalable and intuitive way. Our main insight is noticing that ES is already a distributed blackbox algorithm, and thus we may simply insert a model controller from ENAS into the central aggregator in ES and obtain weight sharing properties for free. By doing so, we bridge the gap from NAS research in supervised learning settings to the reinforcement learning scenario through this relatively simple marriage between two different lines of research, and are one of the first to apply controller-based NAS techniques to RL. We demonstrate the utility of our method by training combinatorial neural network architectures for RL problems in continuous control, via edge pruning and weight sharing. We also incorporate a wide variety of popular techniques from modern NAS literature, including multiobjective optimization and varying controller methods, to showcase their promise in the RL field and discuss possible extensions. We achieve >90% network compression for multiple tasks, which may be special interest in mobile robotics with limited storage and computational resources.
Robotic Table Tennis with Model-Free Reinforcement Learning
Mar 31, 2020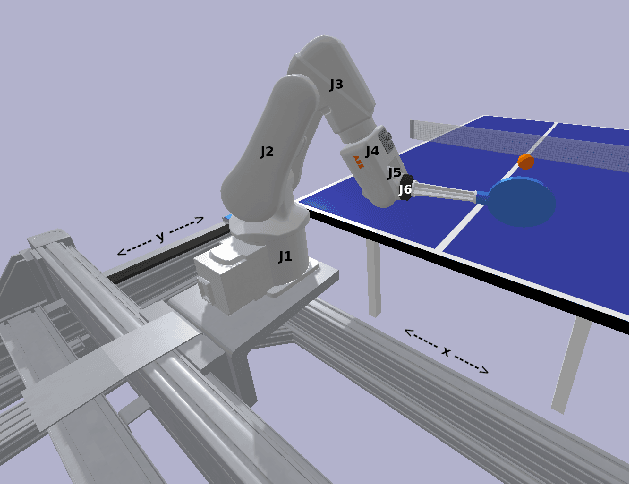
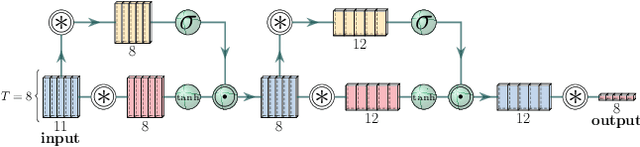

We propose a model-free algorithm for learning efficient policies capable of returning table tennis balls by controlling robot joints at a rate of 100Hz. We demonstrate that evolutionary search (ES) methods acting on CNN-based policy architectures for non-visual inputs and convolving across time learn compact controllers leading to smooth motions. Furthermore, we show that with appropriately tuned curriculum learning on the task and rewards, policies are capable of developing multi-modal styles, specifically forehand and backhand stroke, whilst achieving 80\% return rate on a wide range of ball throws. We observe that multi-modality does not require any architectural priors, such as multi-head architectures or hierarchical policies.
Rapidly Adaptable Legged Robots via Evolutionary Meta-Learning
Mar 02, 2020

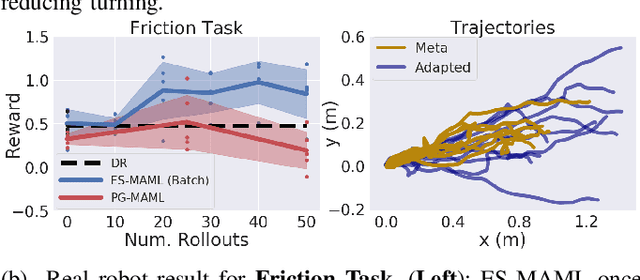
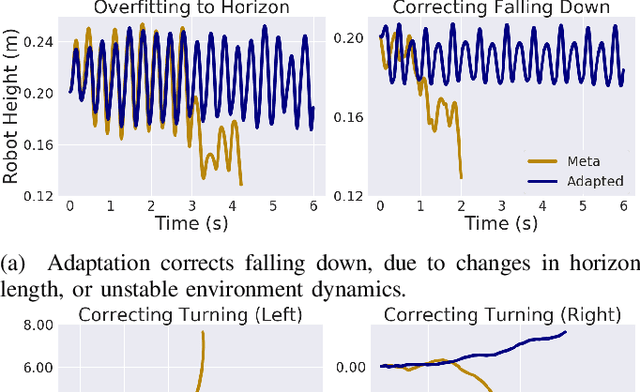
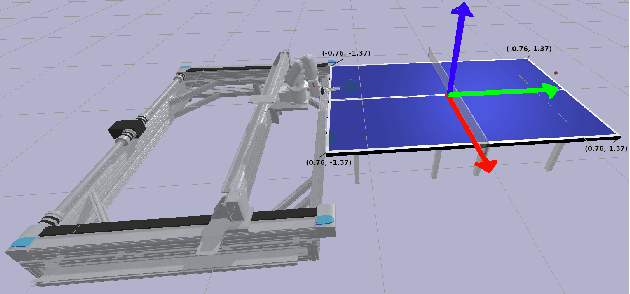
Learning adaptable policies is crucial for robots to operate autonomously in our complex and quickly changing world. In this work, we present a new meta-learning method that allows robots to quickly adapt to changes in dynamics. In contrast to gradient-based meta-learning algorithms that rely on second-order gradient estimation, we introduce a more noise-tolerant Batch Hill-Climbing adaptation operator and combine it with meta-learning based on evolutionary strategies. Our method significantly improves adaptation to changes in dynamics in high noise settings, which are common in robotics applications. We validate our approach on a quadruped robot that learns to walk while subject to changes in dynamics. We observe that our method significantly outperforms prior gradient-based approaches, enabling the robot to adapt its policy to changes based on less than 3 minutes of real data.
ES-MAML: Simple Hessian-Free Meta Learning
Oct 05, 2019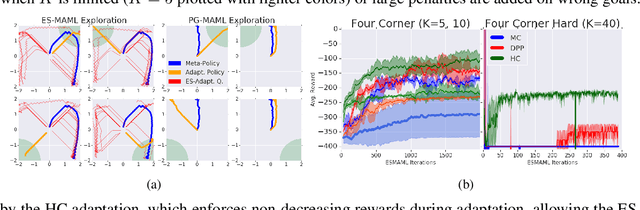
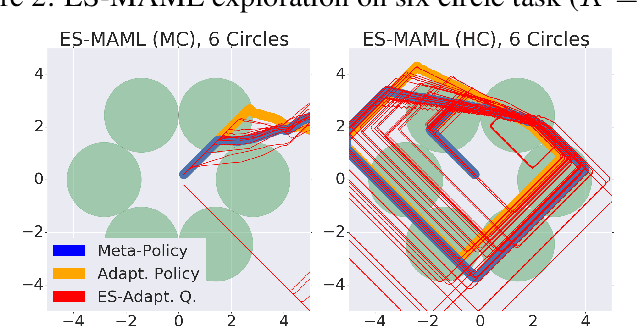
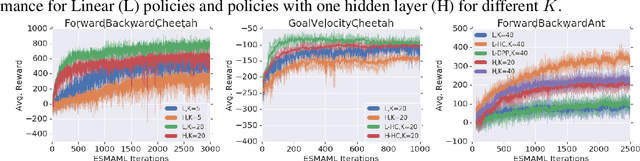
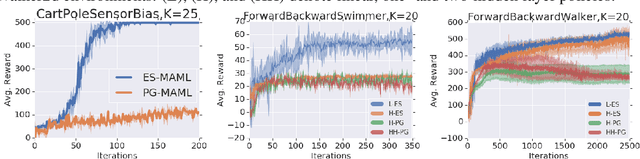
We introduce ES-MAML, a new framework for solving the model agnostic meta learning (MAML) problem based on Evolution Strategies (ES). Existing algorithms for MAML are based on policy gradients, and incur significant difficulties when attempting to estimate second derivatives using backpropagation on stochastic policies. We show how ES can be applied to MAML to obtain an algorithm which avoids the problem of estimating second derivatives, and is also conceptually simple and easy to implement. Moreover, ES-MAML can handle new types of nonsmooth adaptation operators, and other techniques for improving performance and estimation of ES methods become applicable. We show empirically that ES-MAML is competitive with existing methods and often yields better adaptation with fewer queries.
Reinforcement Learning with Chromatic Networks
Jul 10, 2019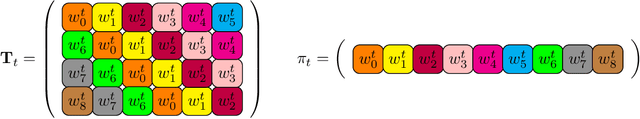
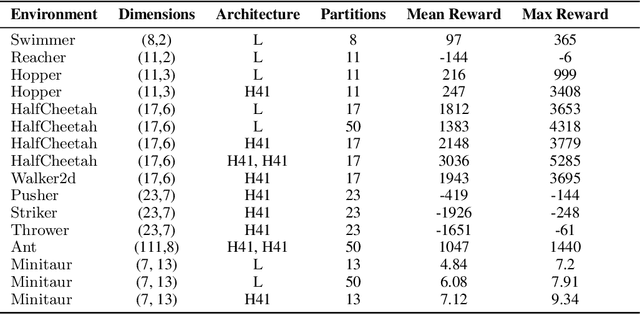
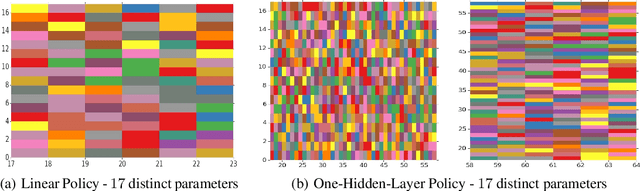
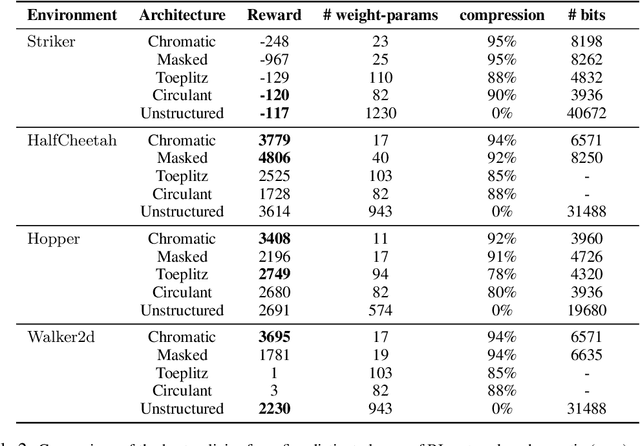
We present a new algorithm for finding compact neural networks encoding reinforcement learning (RL) policies. To do it, we leverage in the novel RL setting the theory of pointer networks and ENAS-type algorithms for combinatorial optimization of RL policies as well as recent evolution strategies (ES) optimization methods, and propose to define the combinatorial search space to be the the set of different edge-partitionings (colorings) into same-weight classes. For several RL tasks, we manage to learn colorings translating to effective policies parameterized by as few as 17 weight parameters, providing 6x compression over state-of-the-art compact policies based on Toeplitz matrices. We believe that our work is one of the first attempts to propose a rigorous approach to training structured neural network architectures for RL problems that are of interest especially in mobile robotics with limited storage and computational resources.
Leader Stochastic Gradient Descent for Distributed Training of Deep Learning Models
May 24, 2019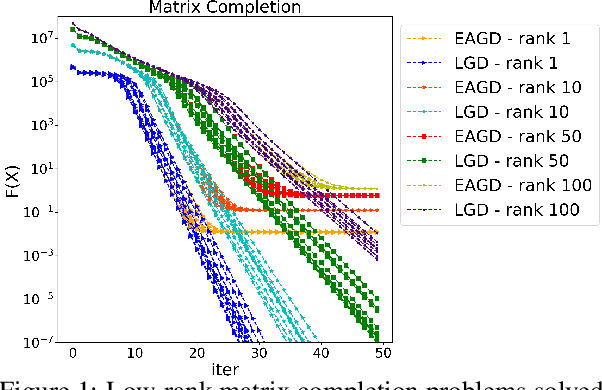
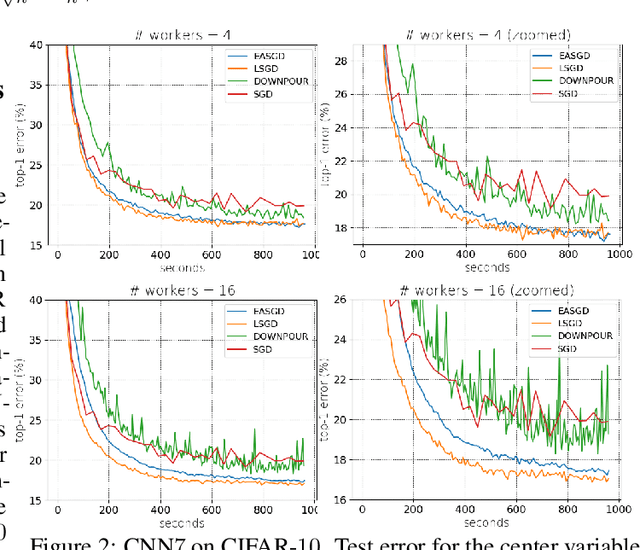


We consider distributed optimization under communication constraints for training deep learning models. We propose a new algorithm, whose parameter updates rely on two forces: a regular gradient step, and a corrective direction dictated by the currently best-performing worker (leader). Our method differs from the parameter-averaging scheme EASGD in a number of ways: (i) our objective formulation does not change the location of stationary points compared to the original optimization problem; (ii) we avoid convergence decelerations caused by pulling local workers descending to different local minima to each other (i.e. to the average of their parameters); (iii) our update by design breaks the curse of symmetry (the phenomenon of being trapped in poorly generalizing sub-optimal solutions in symmetric non-convex landscapes); and (iv) our approach is more communication efficient since it broadcasts only parameters of the leader rather than all workers. We provide theoretical analysis of the batch version of the proposed algorithm, which we call Leader Gradient Descent (LGD), and its stochastic variant (LSGD). Finally, we implement an asynchronous version of our algorithm and extend it to the multi-leader setting, where we form groups of workers, each represented by its own local leader (the best performer in a group), and update each worker with a corrective direction comprised of two attractive forces: one to the local, and one to the global leader (the best performer among all workers). The multi-leader setting is well-aligned with current hardware architecture, where local workers forming a group lie within a single computational node and different groups correspond to different nodes. For training convolutional neural networks, we empirically demonstrate that our approach compares favorably to state-of-the-art baselines.