 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Pixels to Legs: Hierarchical Learning of Quadruped Locomotion
Paper and Code
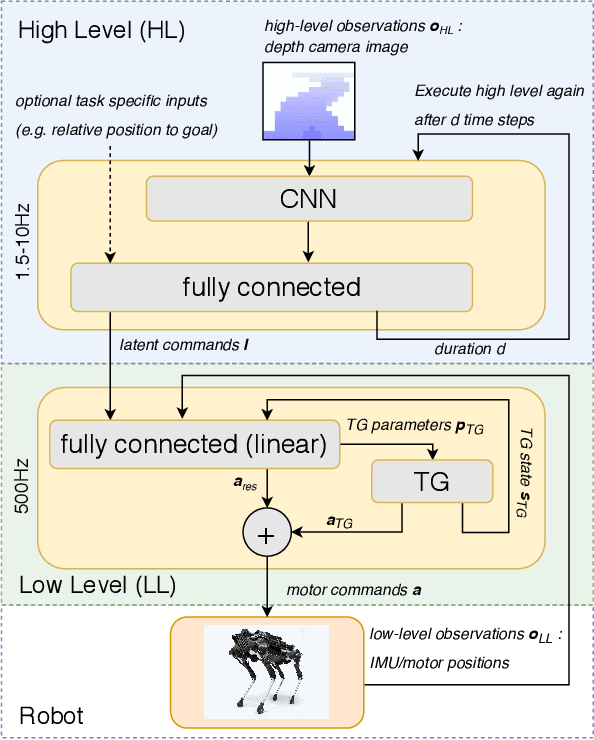

Legged robots navigating crowded scenes and complex terrains in the real world are required to execute dynamic leg movements while processing visual input for obstacle avoidance and path planning. We show that a quadruped robot can acquire both of these skills by means of hierarchical reinforcement learning (HRL). By virtue of their hierarchical structure, our policies learn to implicitly break down this joint problem by concurrently learning High Level (HL) and Low Level (LL) neural network policies. These two levels are connected by a low dimensional hidden layer, which we call latent command. HL receives a first-person camera view, whereas LL receives the latent command from HL and the robot's on-board sensors to control its actuators. We train policies to walk in two different environments: a curved cliff and a maze. We show that hierarchical policies can concurrently learn to locomote and navigate in these environments, and show they are more efficient than non-hierarchical neural network policies. This architecture also allows for knowledge reuse across tasks. LL networks trained on one task can be transferred to a new task in a new environment. Finally HL, which processes camera images, can be evaluated at much lower and varying frequencies compared to LL, thus reducing computation times and bandwidth requirements.