 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBarkour: Benchmarking Animal-level Agility with Quadruped Robots
May 24, 2023
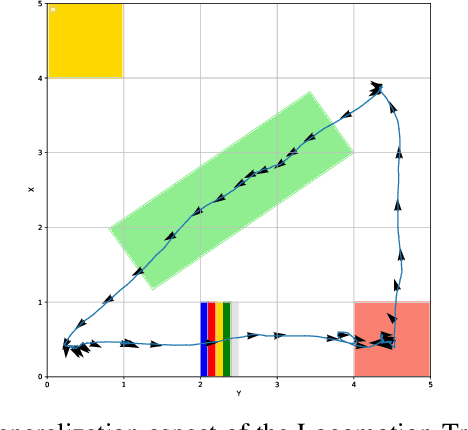
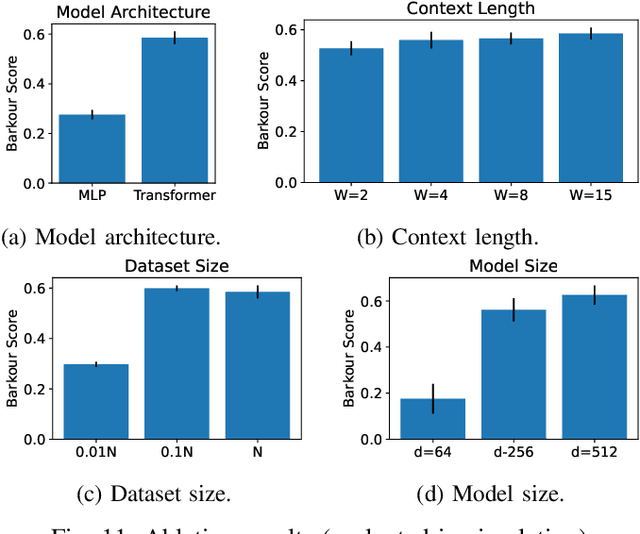

Animals have evolved various agile locomotion strategies, such as sprinting, leaping, and jumping. There is a growing interest in developing legged robots that move like their biological counterparts and show various agile skills to navigate complex environments quickly. Despite the interest, the field lacks systematic benchmarks to measure the performance of control policies and hardware in agility. We introduce the Barkour benchmark, an obstacle course to quantify agility for legged robots. Inspired by dog agility competitions, it consists of diverse obstacles and a time based scoring mechanism. This encourages researchers to develop controllers that not only move fast, but do so in a controllable and versatile way. To set strong baselines, we present two methods for tackling the benchmark. In the first approach, we train specialist locomotion skills using on-policy reinforcement learning methods and combine them with a high-level navigation controller. In the second approach, we distill the specialist skills into a Transformer-based generalist locomotion policy, named Locomotion-Transformer, that can handle various terrains and adjust the robot's gait based on the perceived environment and robot states. Using a custom-built quadruped robot, we demonstrate that our method can complete the course at half the speed of a dog. We hope that our work represents a step towards creating controllers that enable robots to reach animal-level agility.
Learning and Adapting Agile Locomotion Skills by Transferring Experience
Apr 19, 2023



Legged robots have enormous potential in their range of capabilities, from navigating unstructured terrains to high-speed running. However, designing robust controllers for highly agile dynamic motions remains a substantial challenge for roboticists. Reinforcement learning (RL) offers a promising data-driven approach for automatically training such controllers. However, exploration in these high-dimensional, underactuated systems remains a significant hurdle for enabling legged robots to learn performant, naturalistic, and versatile agility skills. We propose a framework for training complex robotic skills by transferring experience from existing controllers to jumpstart learning new tasks. To leverage controllers we can acquire in practice, we design this framework to be flexible in terms of their source -- that is, the controllers may have been optimized for a different objective under different dynamics, or may require different knowledge of the surroundings -- and thus may be highly suboptimal for the target task. We show that our method enables learning complex agile jumping behaviors, navigating to goal locations while walking on hind legs, and adapting to new environments. We also demonstrate that the agile behaviors learned in this way are graceful and safe enough to deploy in the real world.
Legged Robots that Keep on Learning: Fine-Tuning Locomotion Policies in the Real World
Oct 11, 2021
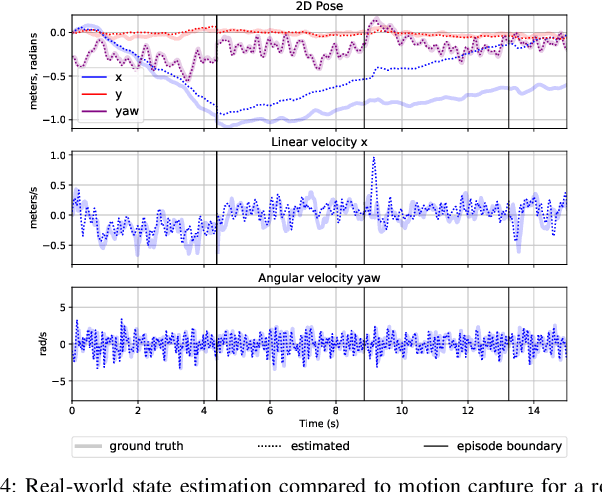


Legged robots are physically capable of traversing a wide range of challenging environments, but designing controllers that are sufficiently robust to handle this diversity has been a long-standing challenge in robotics. Reinforcement learning presents an appealing approach for automating the controller design process and has been able to produce remarkably robust controllers when trained in a suitable range of environments. However, it is difficult to predict all likely conditions the robot will encounter during deployment and enumerate them at training-time. What if instead of training controllers that are robust enough to handle any eventuality, we enable the robot to continually learn in any setting it finds itself in? This kind of real-world reinforcement learning poses a number of challenges, including efficiency, safety, and autonomy. To address these challenges, we propose a practical robot reinforcement learning system for fine-tuning locomotion policies in the real world. We demonstrate that a modest amount of real-world training can substantially improve performance during deployment, and this enables a real A1 quadrupedal robot to autonomously fine-tune multiple locomotion skills in a range of environments, including an outdoor lawn and a variety of indoor terrains.
Cooperation without Coordination: Hierarchical Predictive Planning for Decentralized Multiagent Navigation
Mar 15, 2020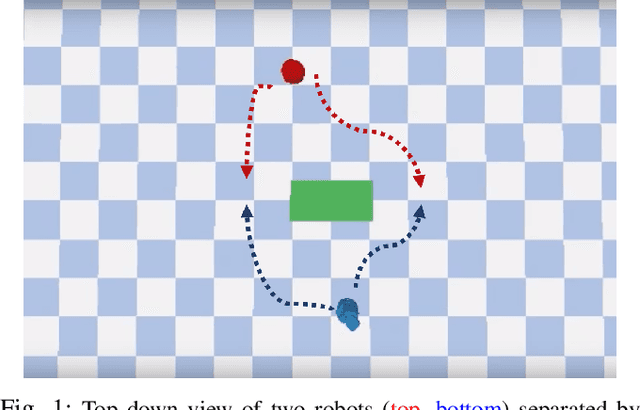
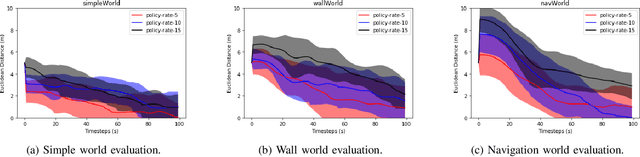
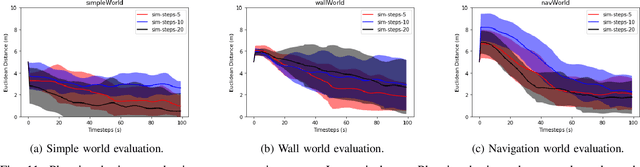
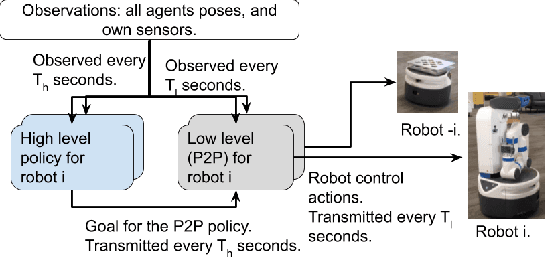
Decentralized multiagent planning raises many challenges, such as adaption to changing environments inexplicable by the agent's own behavior, coordination from noisy sensor inputs like lidar, cooperation without knowing other agents' intents. To address these challenges, we present hierarchical predictive planning (HPP) for decentralized multiagent navigation tasks. HPP learns prediction models for itself and other teammates, and uses the prediction models to propose and evaluate navigation goals that complete the cooperative task without explicit coordination. To learn the prediction models, HPP observes other agents' behavior and learns to maps own sensors to predicted locations of other agents. HPP then uses the cross-entropy method to iteratively propose, evaluate, and improve navigation goals, under assumption that all agents in the team share a common objective. HPP removes the need for a centralized operator (i.e. robots determine their own actions without coordinating their beliefs or plans) and can be trained and easily transferred to real world environments. The results show that HPP generalizes to new environments including real-world robot team. It is also 33x more sample efficient and performs better in complex environments compared to a baseline. The video and website for this paper can be found at https://youtu.be/-LqgfksqNH8 and https://sites.google.com/view/multiagent-hpp.
Neural Collision Clearance Estimator for Fast Robot Motion Planning
Oct 14, 2019

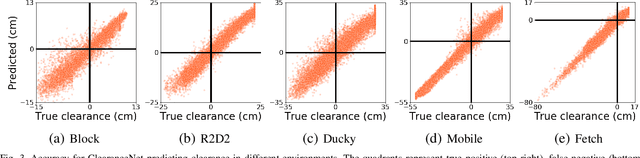
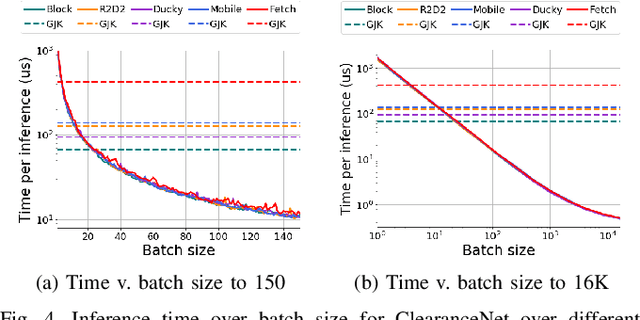
Collision checking is a well known bottleneck in sampling-based motion planning due to its computational expense and the large number of checks required. To alleviate this bottleneck, we present a fast neural network collision checking heuristic, ClearanceNet, and incorporate it within a planning algorithm, ClearanceNet-RRT (CN-RRT). ClearanceNet takes as input a robot pose and the location of all obstacles in the workspace and learns to predict the clearance, i.e., distance to nearest obstacle. CN-RRT then efficiently computes a motion plan by leveraging three key features of ClearanceNet. First, as neural network inference is massively parallel, CN-RRT explores the space via a parallel RRT, which expands nodes in parallel, allowing for thousands of collision checks at once. Second, CN-RRT adaptively relaxes its clearance threshold for more difficult problems. Third, to repair errors, CN-RRT shifts states towards higher clearance through a gradient-based approach that uses the analytic gradient of ClearanceNet. Once a path is found, any errors are repaired via RRT over the misclassified sections, thus maintaining the theoretical guarantees of sampling-based motion planning. We evaluate the collision checking speed, planning speed, and motion plan efficiency in configuration spaces with up to 30 degrees of freedom. The collision checking achieves speedups of more than two orders of magnitude over traditional collision detection methods. Sampling-based planning over multiple robotic arms in new environment configurations achieves speedups of up to 51% over a baseline, with paths up to 25% more efficient. Experiments on a physical Fetch robot reaching into shelves in a cluttered environment confirm the feasibility of this method on real robots.
Long-Range Indoor Navigation with PRM-RL
Feb 25, 2019
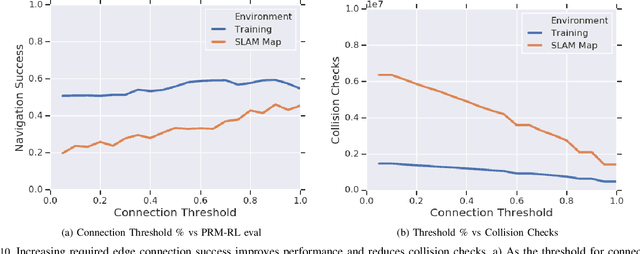
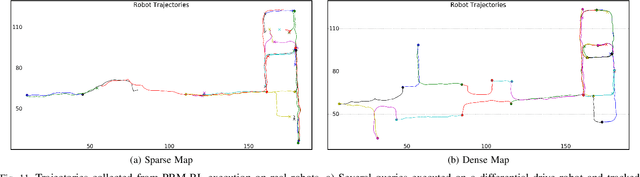
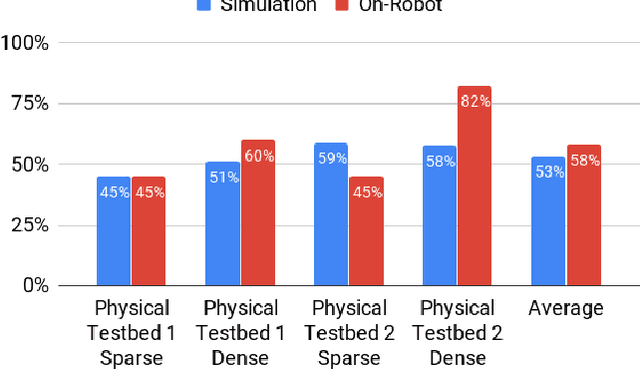
Long-range indoor navigation requires guiding robots with noisy sensors and controls through cluttered environments along paths that span a variety of buildings. We achieve this with PRM-RL, a hierarchical robot navigation method in which reinforcement learning agents that map noisy sensors to robot controls learn to solve short-range obstacle avoidance tasks, and then sampling-based planners map where these agents can reliably navigate in simulation; these roadmaps and agents are then deployed on-robot, guiding the robot along the shortest path where the agents are likely to succeed. Here we use Probabilistic Roadmaps (PRMs) as the sampling-based planner and AutoRL as the reinforcement learning method in the indoor navigation context. We evaluate the method in simulation for kinematic differential drive and kinodynamic car-like robots in several environments, and on-robot for differential-drive robots at two physical sites. Our results show PRM-RL with AutoRL is more successful than several baselines, is robust to noise, and can guide robots over hundreds of meters in the face of noise and obstacles in both simulation and on-robot, including over 3.3 kilometers of physical robot navigation.
FollowNet: Robot Navigation by Following Natural Language Directions with Deep Reinforcement Learning
May 16, 2018
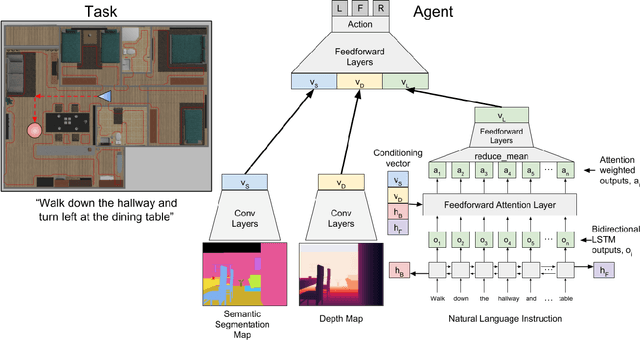
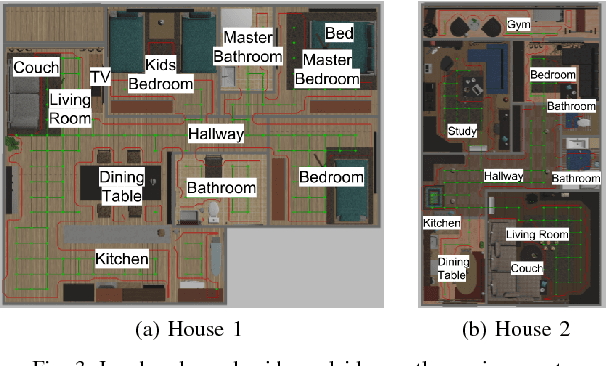
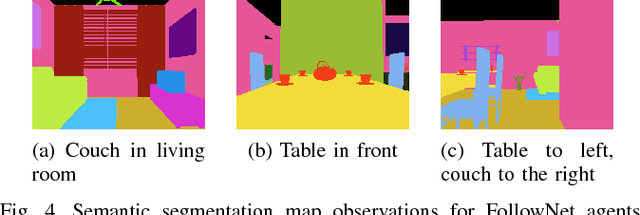
Understanding and following directions provided by humans can enable robots to navigate effectively in unknown situations. We present FollowNet, an end-to-end differentiable neural architecture for learning multi-modal navigation policies. FollowNet maps natural language instructions as well as visual and depth inputs to locomotion primitives. FollowNet processes instructions using an attention mechanism conditioned on its visual and depth input to focus on the relevant parts of the command while performing the navigation task. Deep reinforcement learning (RL) a sparse reward learns simultaneously the state representation, the attention function, and control policies. We evaluate our agent on a dataset of complex natural language directions that guide the agent through a rich and realistic dataset of simulated homes. We show that the FollowNet agent learns to execute previously unseen instructions described with a similar vocabulary, and successfully navigates along paths not encountered during training. The agent shows 30% improvement over a baseline model without the attention mechanism, with 52% success rate at novel instructions.
* 7 pages, 8 figures