 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVADER: Visual Affordance Detection and Error Recovery for Multi Robot Human Collaboration
May 25, 2024



Robots today can exploit the rich world knowledge of large language models to chain simple behavioral skills into long-horizon tasks. However, robots often get interrupted during long-horizon tasks due to primitive skill failures and dynamic environments. We propose VADER, a plan, execute, detect framework with seeking help as a new skill that enables robots to recover and complete long-horizon tasks with the help of humans or other robots. VADER leverages visual question answering (VQA) modules to detect visual affordances and recognize execution errors. It then generates prompts for a language model planner (LMP) which decides when to seek help from another robot or human to recover from errors in long-horizon task execution. We show the effectiveness of VADER with two long-horizon robotic tasks. Our pilot study showed that VADER is capable of performing complex long-horizon tasks by asking for help from another robot to clear a table. Our user study showed that VADER is capable of performing complex long-horizon tasks by asking for help from a human to clear a path. We gathered feedback from people (N=19) about the performance of the VADER performance vs. a robot that did not ask for help. https://google-vader.github.io/
Principles and Guidelines for Evaluating Social Robot Navigation Algorithms
Jun 29, 2023



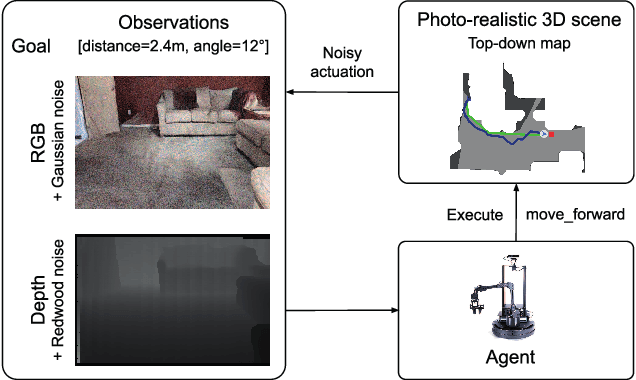
A major challenge to deploying robots widely is navigation in human-populated environments, commonly referred to as social robot navigation. While the field of social navigation has advanced tremendously in recent years, the fair evaluation of algorithms that tackle social navigation remains hard because it involves not just robotic agents moving in static environments but also dynamic human agents and their perceptions of the appropriateness of robot behavior. In contrast, clear, repeatable, and accessible benchmarks have accelerated progress in fields like computer vision, natural language processing and traditional robot navigation by enabling researchers to fairly compare algorithms, revealing limitations of existing solutions and illuminating promising new directions. We believe the same approach can benefit social navigation. In this paper, we pave the road towards common, widely accessible, and repeatable benchmarking criteria to evaluate social robot navigation. Our contributions include (a) a definition of a socially navigating robot as one that respects the principles of safety, comfort, legibility, politeness, social competency, agent understanding, proactivity, and responsiveness to context, (b) guidelines for the use of metrics, development of scenarios, benchmarks, datasets, and simulators to evaluate social navigation, and (c) a design of a social navigation metrics framework to make it easier to compare results from different simulators, robots and datasets.
Retrospectives on the Embodied AI Workshop
Oct 17, 2022

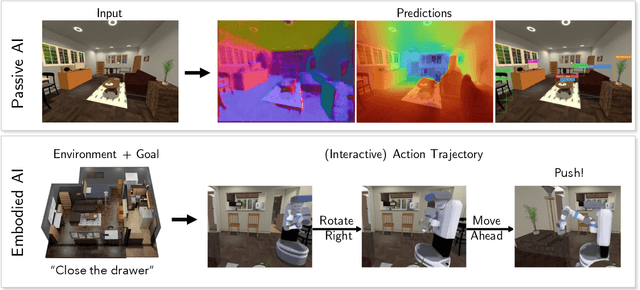
We present a retrospective on the state of Embodied AI research. Our analysis focuses on 13 challenges presented at the Embodied AI Workshop at CVPR. These challenges are grouped into three themes: (1) visual navigation, (2) rearrangement, and (3) embodied vision-and-language. We discuss the dominant datasets within each theme, evaluation metrics for the challenges, and the performance of state-of-the-art models. We highlight commonalities between top approaches to the challenges and identify potential future directions for Embodied AI research.
Learning Model Predictive Controllers with Real-Time Attention for Real-World Navigation
Sep 24, 2022
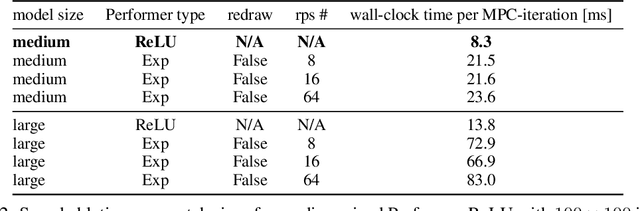


Despite decades of research, existing navigation systems still face real-world challenges when deployed in the wild, e.g., in cluttered home environments or in human-occupied public spaces. To address this, we present a new class of implicit control policies combining the benefits of imitation learning with the robust handling of system constraints from Model Predictive Control (MPC). Our approach, called Performer-MPC, uses a learned cost function parameterized by vision context embeddings provided by Performers -- a low-rank implicit-attention Transformer. We jointly train the cost function and construct the controller relying on it, effectively solving end-to-end the corresponding bi-level optimization problem. We show that the resulting policy improves standard MPC performance by leveraging a few expert demonstrations of the desired navigation behavior in different challenging real-world scenarios. Compared with a standard MPC policy, Performer-MPC achieves >40% better goal reached in cluttered environments and >65% better on social metrics when navigating around humans.
Gesture2Path: Imitation Learning for Gesture-aware Navigation
Sep 19, 2022

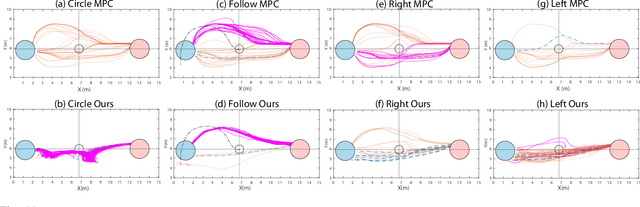

As robots increasingly enter human-centered environments, they must not only be able to navigate safely around humans, but also adhere to complex social norms. Humans often rely on non-verbal communication through gestures and facial expressions when navigating around other people, especially in densely occupied spaces. Consequently, robots also need to be able to interpret gestures as part of solving social navigation tasks. To this end, we present Gesture2Path, a novel social navigation approach that combines image-based imitation learning with model-predictive control. Gestures are interpreted based on a neural network that operates on streams of images, while we use a state-of-the-art model predictive control algorithm to solve point-to-point navigation tasks. We deploy our method on real robots and showcase the effectiveness of our approach for the four gestures-navigation scenarios: left/right, follow me, and make a circle. Our experiments indicate that our method is able to successfully interpret complex human gestures and to use them as a signal to generate socially compliant trajectories for navigation tasks. We validated our method based on in-situ ratings of participants interacting with the robots.
Google Scanned Objects: A High-Quality Dataset of 3D Scanned Household Items
Apr 25, 2022
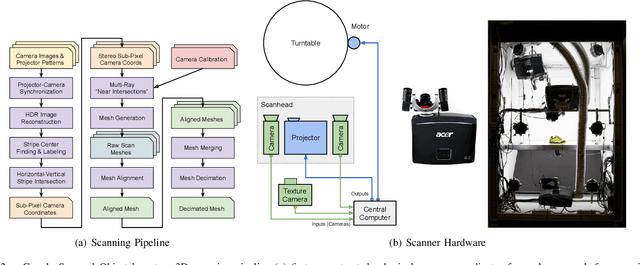

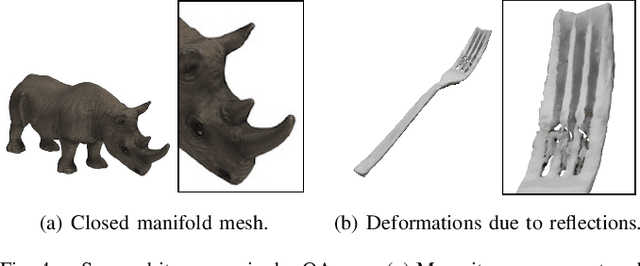
Interactive 3D simulations have enabled breakthroughs in robotics and computer vision, but simulating the broad diversity of environments needed for deep learning requires large corpora of photo-realistic 3D object models. To address this need, we present Google Scanned Objects, an open-source collection of over one thousand 3D-scanned household items released under a Creative Commons license; these models are preprocessed for use in Ignition Gazebo and the Bullet simulation platforms, but are easily adaptable to other simulators. We describe our object scanning and curation pipeline, then provide statistics about the contents of the dataset and its usage. We hope that the diversity, quality, and flexibility of Google Scanned Objects will lead to advances in interactive simulation, synthetic perception, and robotic learning.
A Protocol for Validating Social Navigation Policies
Apr 11, 2022
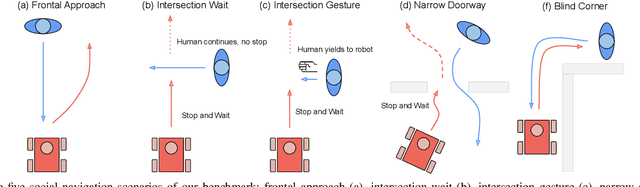
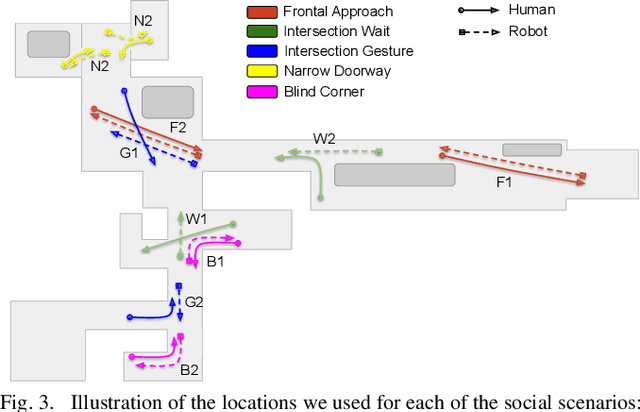

Enabling socially acceptable behavior for situated agents is a major goal of recent robotics research. Robots should not only operate safely around humans, but also abide by complex social norms. A key challenge for developing socially-compliant policies is measuring the quality of their behavior. Social behavior is enormously complex, making it difficult to create reliable metrics to gauge the performance of algorithms. In this paper, we propose a protocol for social navigation benchmarking that defines a set of canonical social navigation scenarios and an in-situ metric for evaluating performance on these scenarios using questionnaires. Our experiments show this protocol is realistic, scalable, and repeatable across runs and physical spaces. Our protocol can be replicated verbatim or it can be used to define a social navigation benchmark for novel scenarios. Our goal is to introduce a protocol for benchmarking social scenarios that is homogeneous and comparable.
Style-based quantum generative adversarial networks for Monte Carlo events
Oct 13, 2021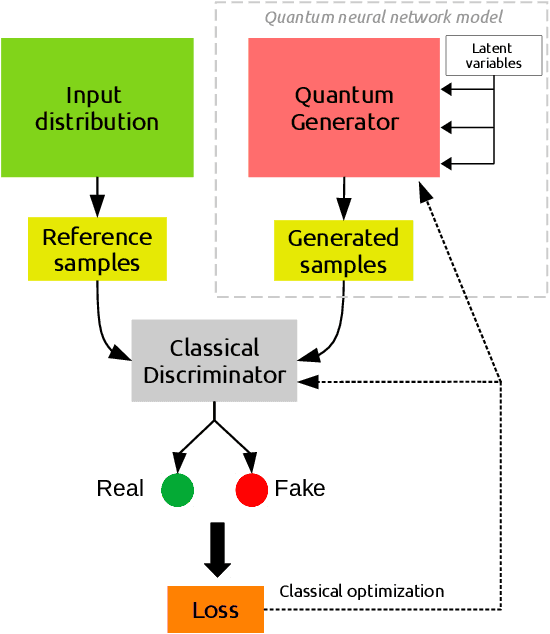
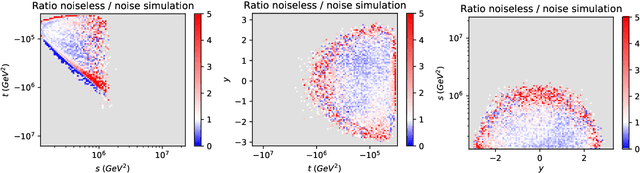
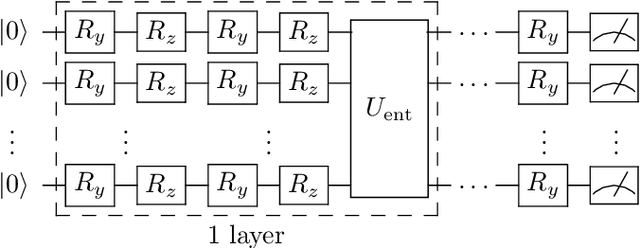
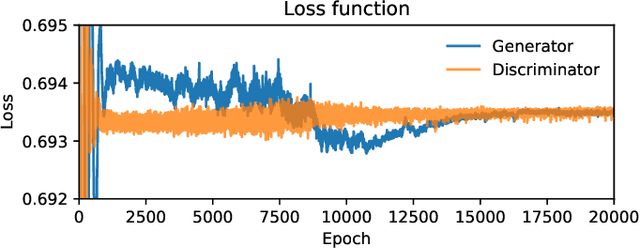
We propose and assess an alternative quantum generator architecture in the context of generative adversarial learning for Monte Carlo event generation, used to simulate particle physics processes at the Large Hadron Collider (LHC). We validate this methodology by implementing the quantum network on artificial data generated from known underlying distributions. The network is then applied to Monte Carlo-generated datasets of specific LHC scattering processes. The new quantum generator architecture leads to an improvement in state-of-the-art implementations while maintaining shallow-depth networks. Moreover, the quantum generator successfully learns the underlying distribution functions even if trained with small training sample sets; this is particularly interesting for data augmentation applications. We deploy this novel methodology on two different quantum hardware architectures, trapped-ion and superconducting technologies, to test its hardware-independent viability.
Evolving Rewards to Automate Reinforcement Learning
May 18, 2019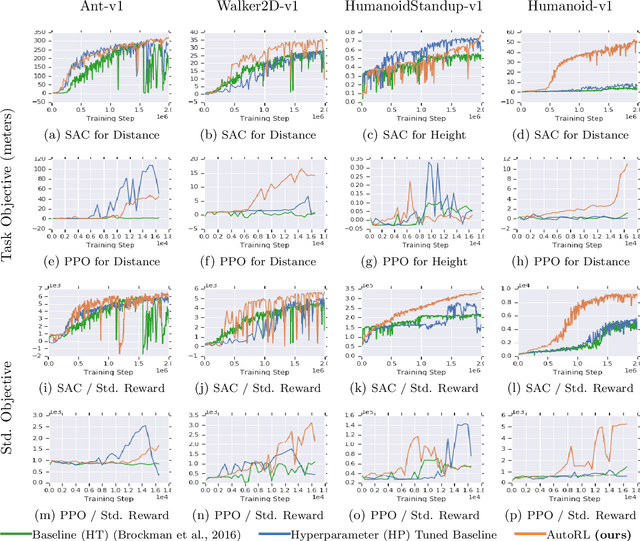

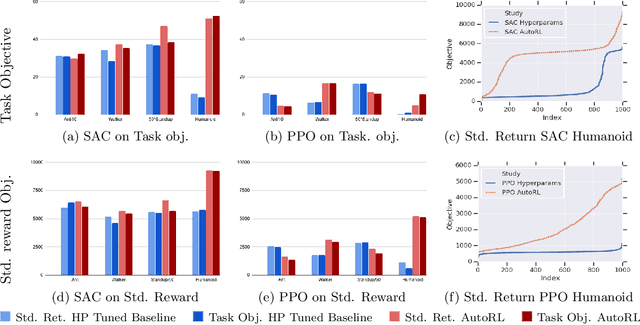

Many continuous control tasks have easily formulated objectives, yet using them directly as a reward in reinforcement learning (RL) leads to suboptimal policies. Therefore, many classical control tasks guide RL training using complex rewards, which require tedious hand-tuning. We automate the reward search with AutoRL, an evolutionary layer over standard RL that treats reward tuning as hyperparameter optimization and trains a population of RL agents to find a reward that maximizes the task objective. AutoRL, evaluated on four Mujoco continuous control tasks over two RL algorithms, shows improvements over baselines, with the the biggest uplift for more complex tasks. The video can be found at: \url{https://youtu.be/svdaOFfQyC8}.
Long-Range Indoor Navigation with PRM-RL
Feb 25, 2019
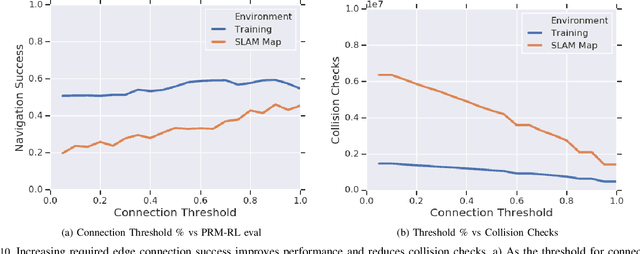
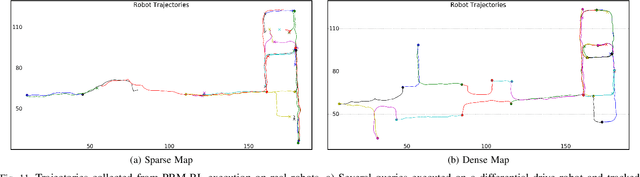
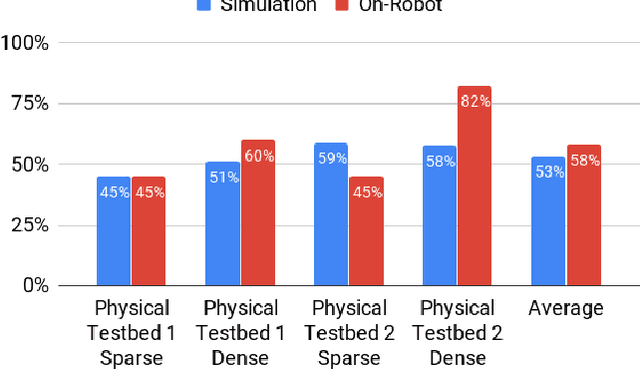
Long-range indoor navigation requires guiding robots with noisy sensors and controls through cluttered environments along paths that span a variety of buildings. We achieve this with PRM-RL, a hierarchical robot navigation method in which reinforcement learning agents that map noisy sensors to robot controls learn to solve short-range obstacle avoidance tasks, and then sampling-based planners map where these agents can reliably navigate in simulation; these roadmaps and agents are then deployed on-robot, guiding the robot along the shortest path where the agents are likely to succeed. Here we use Probabilistic Roadmaps (PRMs) as the sampling-based planner and AutoRL as the reinforcement learning method in the indoor navigation context. We evaluate the method in simulation for kinematic differential drive and kinodynamic car-like robots in several environments, and on-robot for differential-drive robots at two physical sites. Our results show PRM-RL with AutoRL is more successful than several baselines, is robust to noise, and can guide robots over hundreds of meters in the face of noise and obstacles in both simulation and on-robot, including over 3.3 kilometers of physical robot navigation.