 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRL-RRT: Kinodynamic Motion Planning via Learning Reachability Estimators from RL Policies
Jul 12, 2019

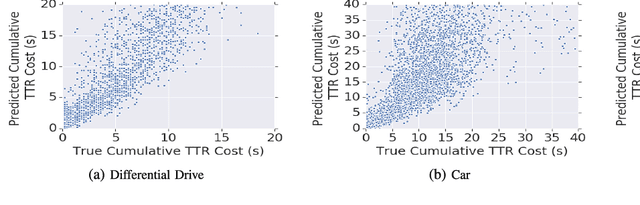

This paper addresses two challenges facing sampling-based kinodynamic motion planning: a way to identify good candidate states for local transitions and the subsequent computationally intractable steering between these candidate states. Through the combination of sampling-based planning, a Rapidly Exploring Randomized Tree (RRT) and an efficient kinodynamic motion planner through machine learning, we propose an efficient solution to long-range planning for kinodynamic motion planning. First, we use deep reinforcement learning to learn an obstacle-avoiding policy that maps a robot's sensor observations to actions, which is used as a local planner during planning and as a controller during execution. Second, we train a reachability estimator in a supervised manner, which predicts the RL policy's time to reach a state in the presence of obstacles. Lastly, we introduce RL-RRT that uses the RL policy as a local planner, and the reachability estimator as the distance function to bias tree-growth towards promising regions. We evaluate our method on three kinodynamic systems, including physical robot experiments. Results across all three robots tested indicate that RL-RRT outperforms state of the art kinodynamic planners in efficiency, and also provides a shorter path finish time than a steering function free method. The learned local planner policy and accompanying reachability estimator demonstrate transferability to the previously unseen experimental environments, making RL-RRT fast because the expensive computations are replaced with simple neural network inference. Video: https://youtu.be/dDMVMTOI8KY
* Accepted to Robotics and Automation Letters in June 2019
Long Range Neural Navigation Policies for the Real World
Mar 23, 2019
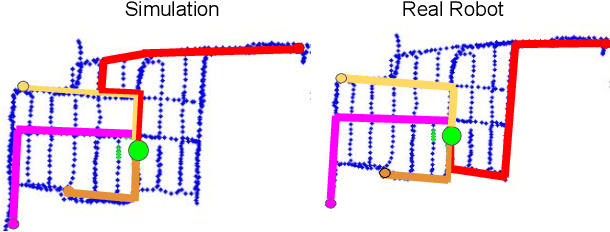
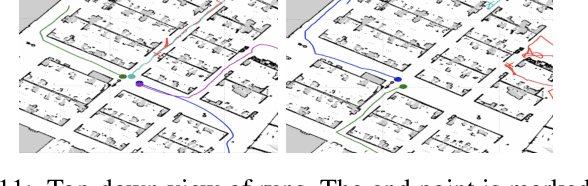

Learned Neural Network based policies have shown promising results for robot navigation. However, most of these approaches fall short of being used on a real robot -- they require extensive training in environments, most of which do not simulate the visuals and the dynamics of the real world well enough that the resulting policies can be easily deployed. We present a novel Neural Net based policy, \name, which allows for easy deployment on a real robot. It consists of two sub policies -- a high level policy which can understand real images and perform long range planning expressed in high level commands; a low level policy that can translate the long range plan into low level commands on a specific platform in a safe and robust manner. For every new deployment, the high level policy is trained on an easily obtainable scan of the environment modeling its visuals and layout. We detail the design of such an environment and how one can use it for training a final navigation policy. Further, we demonstrate a learned low-level policy. We deploy the model in a large office building and test it extensively, achieving $0.80$ success rate over long navigation runs and outperforming SLAM-based models in the same settings.
Long-Range Indoor Navigation with PRM-RL
Feb 25, 2019
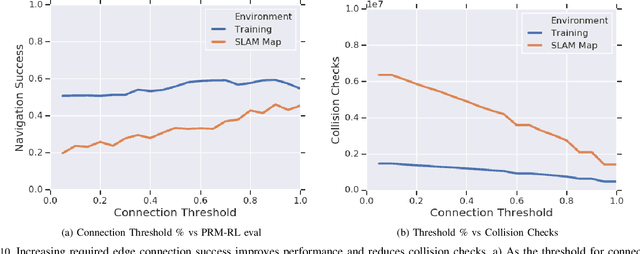
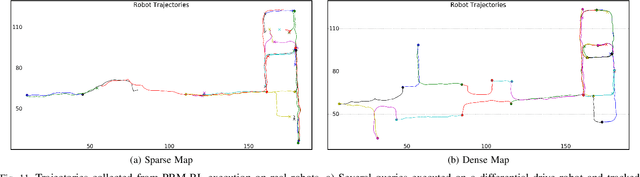
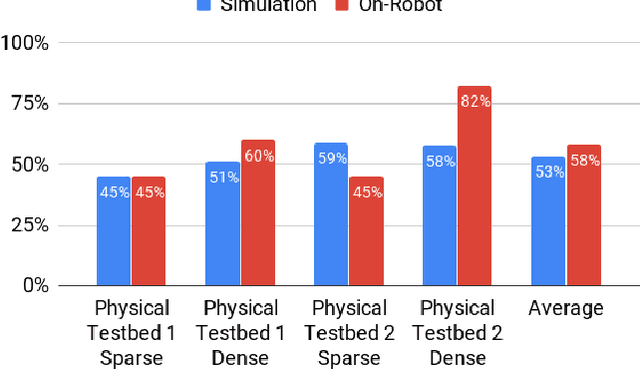
Long-range indoor navigation requires guiding robots with noisy sensors and controls through cluttered environments along paths that span a variety of buildings. We achieve this with PRM-RL, a hierarchical robot navigation method in which reinforcement learning agents that map noisy sensors to robot controls learn to solve short-range obstacle avoidance tasks, and then sampling-based planners map where these agents can reliably navigate in simulation; these roadmaps and agents are then deployed on-robot, guiding the robot along the shortest path where the agents are likely to succeed. Here we use Probabilistic Roadmaps (PRMs) as the sampling-based planner and AutoRL as the reinforcement learning method in the indoor navigation context. We evaluate the method in simulation for kinematic differential drive and kinodynamic car-like robots in several environments, and on-robot for differential-drive robots at two physical sites. Our results show PRM-RL with AutoRL is more successful than several baselines, is robust to noise, and can guide robots over hundreds of meters in the face of noise and obstacles in both simulation and on-robot, including over 3.3 kilometers of physical robot navigation.
Learning Navigation Behaviors End-to-End with AutoRL
Feb 01, 2019

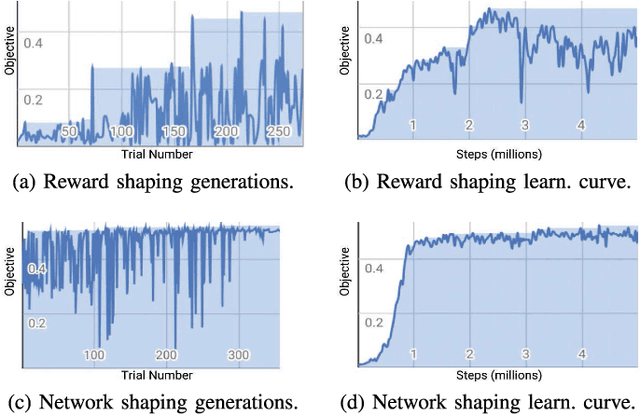
We learn end-to-end point-to-point and path-following navigation behaviors that avoid moving obstacles. These policies receive noisy lidar observations and output robot linear and angular velocities. The policies are trained in small, static environments with AutoRL, an evolutionary automation layer around Reinforcement Learning (RL) that searches for a deep RL reward and neural network architecture with large-scale hyper-parameter optimization. AutoRL first finds a reward that maximizes task completion, and then finds a neural network architecture that maximizes the cumulative of the found reward. Empirical evaluations, both in simulation and on-robot, show that AutoRL policies do not suffer from the catastrophic forgetfulness that plagues many other deep reinforcement learning algorithms, generalize to new environments and moving obstacles, are robust to sensor, actuator, and localization noise, and can serve as robust building blocks for larger navigation tasks. Our path-following and point-to-point policies are respectively 23% and 26% more successful than comparison methods across new environments. Video at: https://youtu.be/0UwkjpUEcbI
PRM-RL: Long-range Robotic Navigation Tasks by Combining Reinforcement Learning and Sampling-based Planning
May 16, 2018
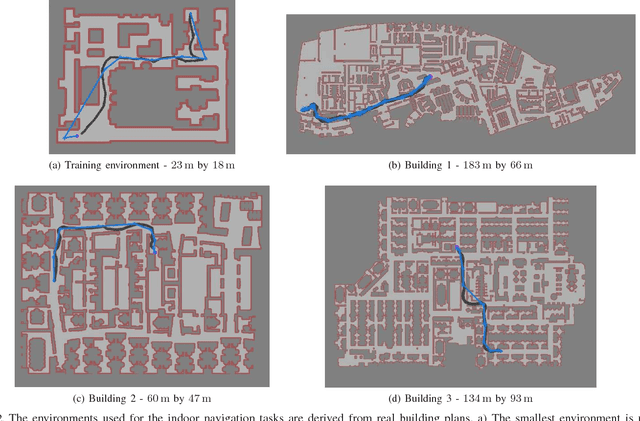

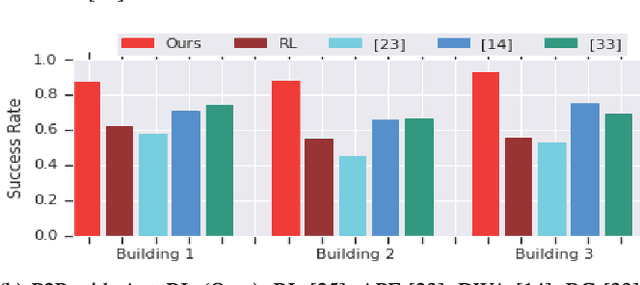
We present PRM-RL, a hierarchical method for long-range navigation task completion that combines sampling based path planning with reinforcement learning (RL). The RL agents learn short-range, point-to-point navigation policies that capture robot dynamics and task constraints without knowledge of the large-scale topology. Next, the sampling-based planners provide roadmaps which connect robot configurations that can be successfully navigated by the RL agent. The same RL agents are used to control the robot under the direction of the planning, enabling long-range navigation. We use the Probabilistic Roadmaps (PRMs) for the sampling-based planner. The RL agents are constructed using feature-based and deep neural net policies in continuous state and action spaces. We evaluate PRM-RL, both in simulation and on-robot, on two navigation tasks with non-trivial robot dynamics: end-to-end differential drive indoor navigation in office environments, and aerial cargo delivery in urban environments with load displacement constraints. Our results show improvement in task completion over both RL agents on their own and traditional sampling-based planners. In the indoor navigation task, PRM-RL successfully completes up to 215 m long trajectories under noisy sensor conditions, and the aerial cargo delivery completes flights over 1000 m without violating the task constraints in an environment 63 million times larger than used in training.
* 9 pages, 7 figures
FollowNet: Robot Navigation by Following Natural Language Directions with Deep Reinforcement Learning
May 16, 2018
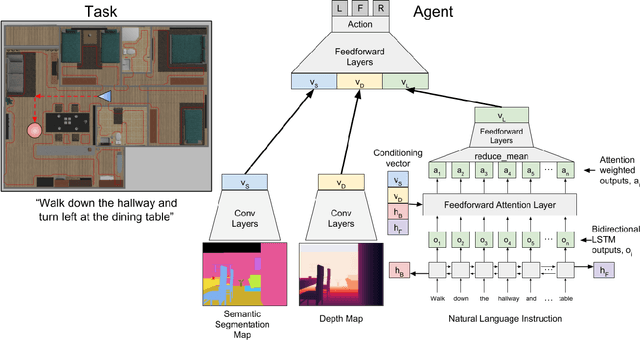
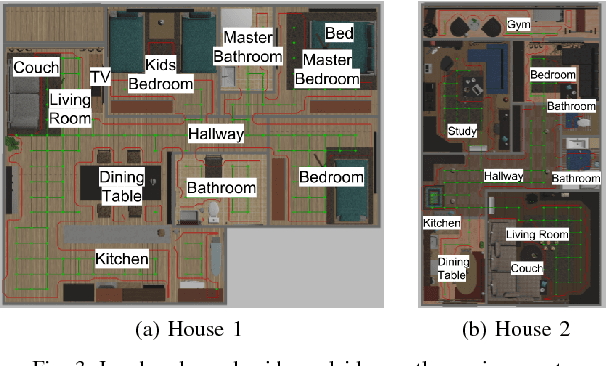
Understanding and following directions provided by humans can enable robots to navigate effectively in unknown situations. We present FollowNet, an end-to-end differentiable neural architecture for learning multi-modal navigation policies. FollowNet maps natural language instructions as well as visual and depth inputs to locomotion primitives. FollowNet processes instructions using an attention mechanism conditioned on its visual and depth input to focus on the relevant parts of the command while performing the navigation task. Deep reinforcement learning (RL) a sparse reward learns simultaneously the state representation, the attention function, and control policies. We evaluate our agent on a dataset of complex natural language directions that guide the agent through a rich and realistic dataset of simulated homes. We show that the FollowNet agent learns to execute previously unseen instructions described with a similar vocabulary, and successfully navigates along paths not encountered during training. The agent shows 30% improvement over a baseline model without the attention mechanism, with 52% success rate at novel instructions.
* 7 pages, 8 figures
Visual Representations for Semantic Target Driven Navigation
May 15, 2018
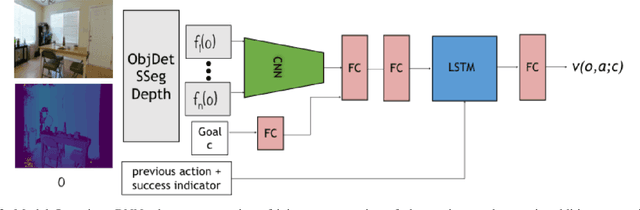
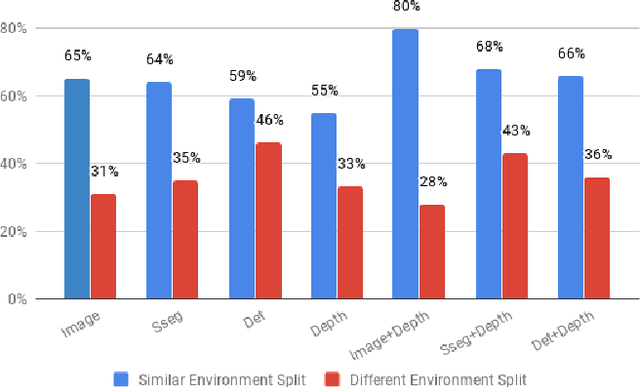
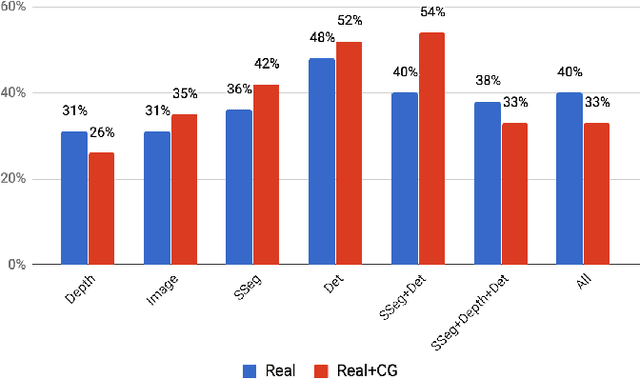
What is a good visual representation for autonomous agents? We address this question in the context of semantic visual navigation, which is the problem of a robot finding its way through a complex environment to a target object, e.g. go to the refrigerator. Instead of acquiring a metric semantic map of an environment and using planning for navigation, our approach learns navigation policies on top of representations that capture spatial layout and semantic contextual cues. We propose to using high level semantic and contextual features including segmentation and detection masks obtained by off-the-shelf state-of- the-art vision as observations and use deep network to learn the navigation policy. This choice allows using additional data, from orthogonal sources, to better train different parts of the model the representation extraction is trained on large standard vision datasets while the navigation component leverages large synthetic environments for training. This combination of real and synthetic is possible because equitable feature representations are available in both (e.g., segmentation and detection masks), which alleviates the need for domain adaptation. Both the representation and the navigation policy can be readily applied to real non-synthetic environments as demonstrated on the Active Vision Dataset [1]. Our approach gets successfully to the target in 54% of the cases in unexplored environments, compared to 46% for non-learning based approach, and 28% for the learning-based baseline.