 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLong Range Neural Navigation Policies for the Real World
Paper and Code
Mar 23, 2019
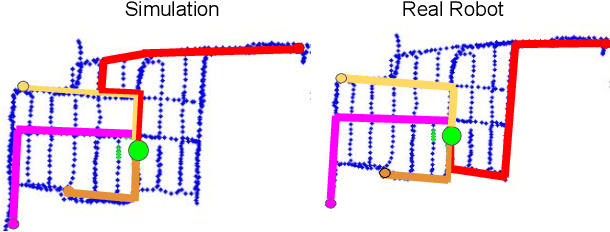
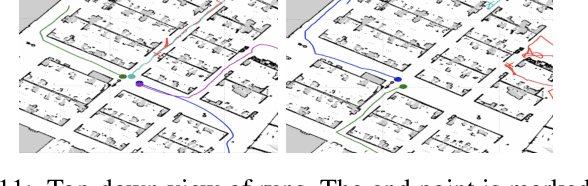

Learned Neural Network based policies have shown promising results for robot navigation. However, most of these approaches fall short of being used on a real robot -- they require extensive training in environments, most of which do not simulate the visuals and the dynamics of the real world well enough that the resulting policies can be easily deployed. We present a novel Neural Net based policy, \name, which allows for easy deployment on a real robot. It consists of two sub policies -- a high level policy which can understand real images and perform long range planning expressed in high level commands; a low level policy that can translate the long range plan into low level commands on a specific platform in a safe and robust manner. For every new deployment, the high level policy is trained on an easily obtainable scan of the environment modeling its visuals and layout. We detail the design of such an environment and how one can use it for training a final navigation policy. Further, we demonstrate a learned low-level policy. We deploy the model in a large office building and test it extensively, achieving $0.80$ success rate over long navigation runs and outperforming SLAM-based models in the same settings.