 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Navigation Behaviors End-to-End with AutoRL
Paper and Code
Feb 01, 2019

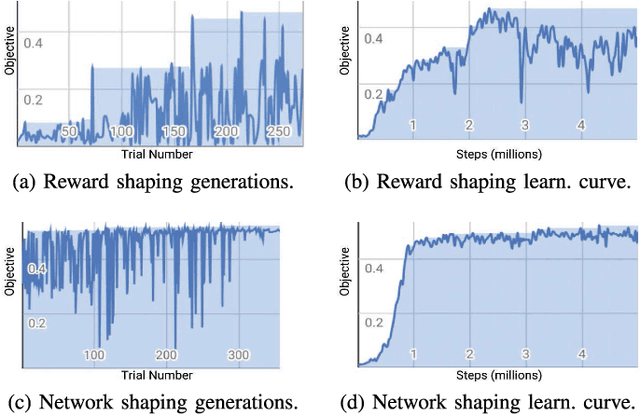
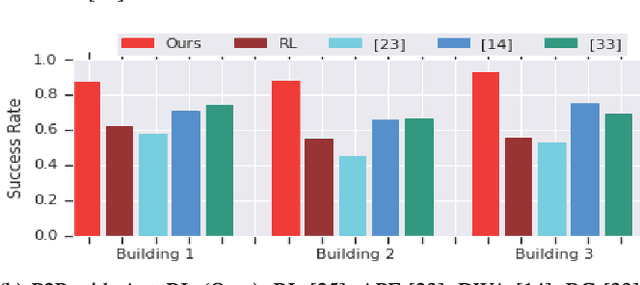
We learn end-to-end point-to-point and path-following navigation behaviors that avoid moving obstacles. These policies receive noisy lidar observations and output robot linear and angular velocities. The policies are trained in small, static environments with AutoRL, an evolutionary automation layer around Reinforcement Learning (RL) that searches for a deep RL reward and neural network architecture with large-scale hyper-parameter optimization. AutoRL first finds a reward that maximizes task completion, and then finds a neural network architecture that maximizes the cumulative of the found reward. Empirical evaluations, both in simulation and on-robot, show that AutoRL policies do not suffer from the catastrophic forgetfulness that plagues many other deep reinforcement learning algorithms, generalize to new environments and moving obstacles, are robust to sensor, actuator, and localization noise, and can serve as robust building blocks for larger navigation tasks. Our path-following and point-to-point policies are respectively 23% and 26% more successful than comparison methods across new environments. Video at: https://youtu.be/0UwkjpUEcbI