 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBarkour: Benchmarking Animal-level Agility with Quadruped Robots
May 24, 2023
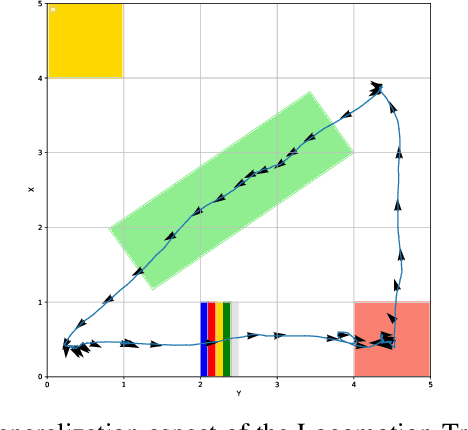
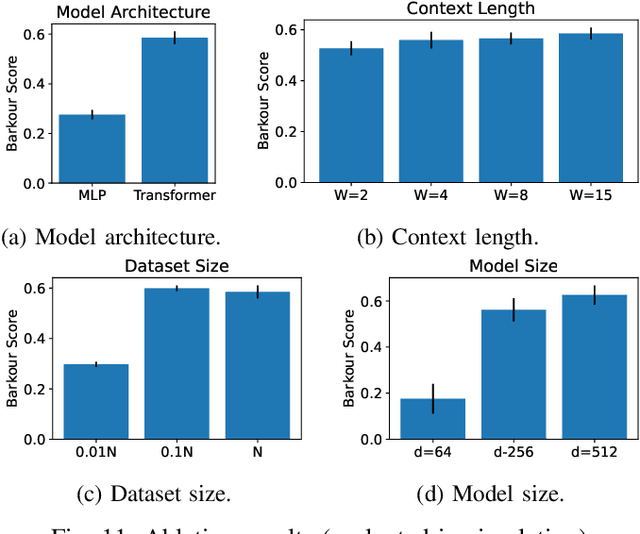

Animals have evolved various agile locomotion strategies, such as sprinting, leaping, and jumping. There is a growing interest in developing legged robots that move like their biological counterparts and show various agile skills to navigate complex environments quickly. Despite the interest, the field lacks systematic benchmarks to measure the performance of control policies and hardware in agility. We introduce the Barkour benchmark, an obstacle course to quantify agility for legged robots. Inspired by dog agility competitions, it consists of diverse obstacles and a time based scoring mechanism. This encourages researchers to develop controllers that not only move fast, but do so in a controllable and versatile way. To set strong baselines, we present two methods for tackling the benchmark. In the first approach, we train specialist locomotion skills using on-policy reinforcement learning methods and combine them with a high-level navigation controller. In the second approach, we distill the specialist skills into a Transformer-based generalist locomotion policy, named Locomotion-Transformer, that can handle various terrains and adjust the robot's gait based on the perceived environment and robot states. Using a custom-built quadruped robot, we demonstrate that our method can complete the course at half the speed of a dog. We hope that our work represents a step towards creating controllers that enable robots to reach animal-level agility.
Learning and Adapting Agile Locomotion Skills by Transferring Experience
Apr 19, 2023



Legged robots have enormous potential in their range of capabilities, from navigating unstructured terrains to high-speed running. However, designing robust controllers for highly agile dynamic motions remains a substantial challenge for roboticists. Reinforcement learning (RL) offers a promising data-driven approach for automatically training such controllers. However, exploration in these high-dimensional, underactuated systems remains a significant hurdle for enabling legged robots to learn performant, naturalistic, and versatile agility skills. We propose a framework for training complex robotic skills by transferring experience from existing controllers to jumpstart learning new tasks. To leverage controllers we can acquire in practice, we design this framework to be flexible in terms of their source -- that is, the controllers may have been optimized for a different objective under different dynamics, or may require different knowledge of the surroundings -- and thus may be highly suboptimal for the target task. We show that our method enables learning complex agile jumping behaviors, navigating to goal locations while walking on hind legs, and adapting to new environments. We also demonstrate that the agile behaviors learned in this way are graceful and safe enough to deploy in the real world.
Inner Monologue: Embodied Reasoning through Planning with Language Models
Jul 12, 2022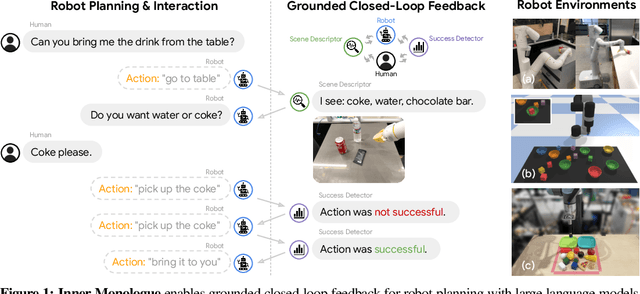
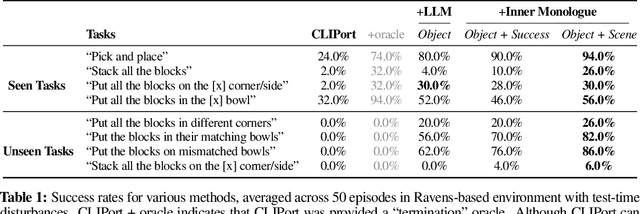


Recent works have shown how the reasoning capabilities of Large Language Models (LLMs) can be applied to domains beyond natural language processing, such as planning and interaction for robots. These embodied problems require an agent to understand many semantic aspects of the world: the repertoire of skills available, how these skills influence the world, and how changes to the world map back to the language. LLMs planning in embodied environments need to consider not just what skills to do, but also how and when to do them - answers that change over time in response to the agent's own choices. In this work, we investigate to what extent LLMs used in such embodied contexts can reason over sources of feedback provided through natural language, without any additional training. We propose that by leveraging environment feedback, LLMs are able to form an inner monologue that allows them to more richly process and plan in robotic control scenarios. We investigate a variety of sources of feedback, such as success detection, scene description, and human interaction. We find that closed-loop language feedback significantly improves high-level instruction completion on three domains, including simulated and real table top rearrangement tasks and long-horizon mobile manipulation tasks in a kitchen environment in the real world.
Do As I Can, Not As I Say: Grounding Language in Robotic Affordances
Apr 04, 2022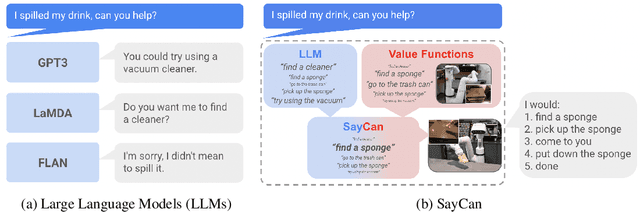
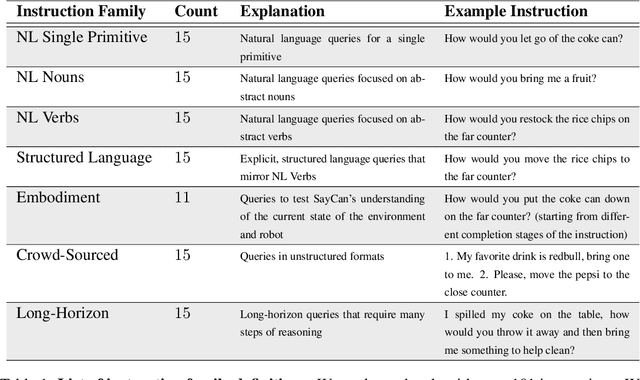
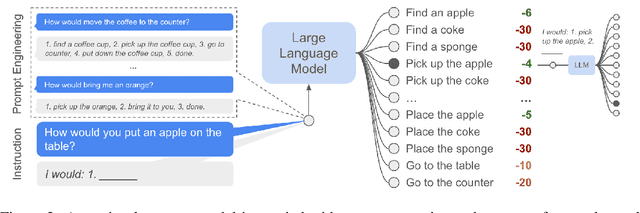
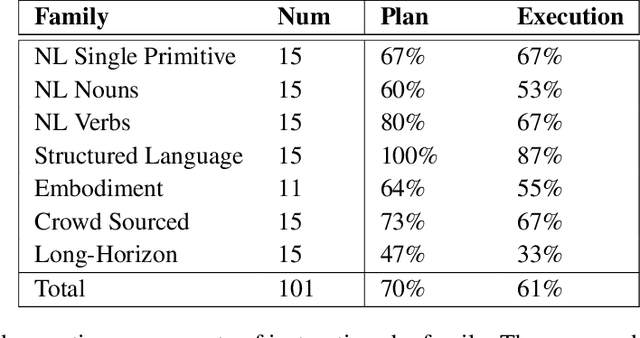
Large language models can encode a wealth of semantic knowledge about the world. Such knowledge could be extremely useful to robots aiming to act upon high-level, temporally extended instructions expressed in natural language. However, a significant weakness of language models is that they lack real-world experience, which makes it difficult to leverage them for decision making within a given embodiment. For example, asking a language model to describe how to clean a spill might result in a reasonable narrative, but it may not be applicable to a particular agent, such as a robot, that needs to perform this task in a particular environment. We propose to provide real-world grounding by means of pretrained skills, which are used to constrain the model to propose natural language actions that are both feasible and contextually appropriate. The robot can act as the language model's "hands and eyes," while the language model supplies high-level semantic knowledge about the task. We show how low-level skills can be combined with large language models so that the language model provides high-level knowledge about the procedures for performing complex and temporally-extended instructions, while value functions associated with these skills provide the grounding necessary to connect this knowledge to a particular physical environment. We evaluate our method on a number of real-world robotic tasks, where we show the need for real-world grounding and that this approach is capable of completing long-horizon, abstract, natural language instructions on a mobile manipulator. The project's website and the video can be found at https://say-can.github.io/
Safe Reinforcement Learning for Legged Locomotion
Mar 05, 2022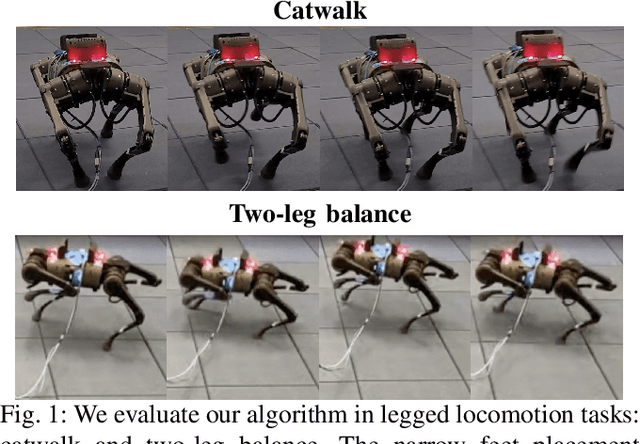
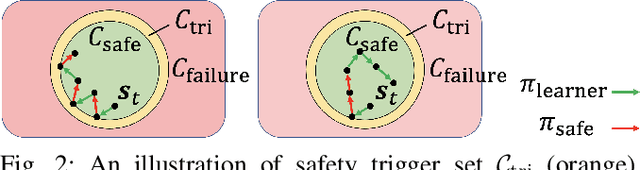


Designing control policies for legged locomotion is complex due to the under-actuated and non-continuous robot dynamics. Model-free reinforcement learning provides promising tools to tackle this challenge. However, a major bottleneck of applying model-free reinforcement learning in real world is safety. In this paper, we propose a safe reinforcement learning framework that switches between a safe recovery policy that prevents the robot from entering unsafe states, and a learner policy that is optimized to complete the task. The safe recovery policy takes over the control when the learner policy violates safety constraints, and hands over the control back when there are no future safety violations. We design the safe recovery policy so that it ensures safety of legged locomotion while minimally intervening in the learning process. Furthermore, we theoretically analyze the proposed framework and provide an upper bound on the task performance. We verify the proposed framework in four locomotion tasks on a simulated and real quadrupedal robot: efficient gait, catwalk, two-leg balance, and pacing. On average, our method achieves 48.6% fewer falls and comparable or better rewards than the baseline methods in simulation. When deployed it on real-world quadruped robot, our training pipeline enables 34% improvement in energy efficiency for the efficient gait, 40.9% narrower of the feet placement in the catwalk, and two times more jumping duration in the two-leg balance. Our method achieves less than five falls over the duration of 115 minutes of hardware time.