 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey on Imitation Learning for Contact-Rich Tasks in Robotics
Jun 16, 2025This paper comprehensively surveys research trends in imitation learning for contact-rich robotic tasks. Contact-rich tasks, which require complex physical interactions with the environment, represent a central challenge in robotics due to their nonlinear dynamics and sensitivity to small positional deviations. The paper examines demonstration collection methodologies, including teaching methods and sensory modalities crucial for capturing subtle interaction dynamics. We then analyze imitation learning approaches, highlighting their applications to contact-rich manipulation. Recent advances in multimodal learning and foundation models have significantly enhanced performance in complex contact tasks across industrial, household, and healthcare domains. Through systematic organization of current research and identification of challenges, this survey provides a foundation for future advancements in contact-rich robotic manipulation.
ExoStart: Efficient learning for dexterous manipulation with sensorized exoskeleton demonstrations
Jun 13, 2025



Recent advancements in teleoperation systems have enabled high-quality data collection for robotic manipulators, showing impressive results in learning manipulation at scale. This progress suggests that extending these capabilities to robotic hands could unlock an even broader range of manipulation skills, especially if we could achieve the same level of dexterity that human hands exhibit. However, teleoperating robotic hands is far from a solved problem, as it presents a significant challenge due to the high degrees of freedom of robotic hands and the complex dynamics occurring during contact-rich settings. In this work, we present ExoStart, a general and scalable learning framework that leverages human dexterity to improve robotic hand control. In particular, we obtain high-quality data by collecting direct demonstrations without a robot in the loop using a sensorized low-cost wearable exoskeleton, capturing the rich behaviors that humans can demonstrate with their own hands. We also propose a simulation-based dynamics filter that generates dynamically feasible trajectories from the collected demonstrations and use the generated trajectories to bootstrap an auto-curriculum reinforcement learning method that relies only on simple sparse rewards. The ExoStart pipeline is generalizable and yields robust policies that transfer zero-shot to the real robot. Our results demonstrate that ExoStart can generate dexterous real-world hand skills, achieving a success rate above 50% on a wide range of complex tasks such as opening an AirPods case or inserting and turning a key in a lock. More details and videos can be found in https://sites.google.com/view/exostart.
Gemini Robotics: Bringing AI into the Physical World
Mar 25, 2025Recent advancements in large multimodal models have led to the emergence of remarkable generalist capabilities in digital domains, yet their translation to physical agents such as robots remains a significant challenge. This report introduces a new family of AI models purposefully designed for robotics and built upon the foundation of Gemini 2.0. We present Gemini Robotics, an advanced Vision-Language-Action (VLA) generalist model capable of directly controlling robots. Gemini Robotics executes smooth and reactive movements to tackle a wide range of complex manipulation tasks while also being robust to variations in object types and positions, handling unseen environments as well as following diverse, open vocabulary instructions. We show that with additional fine-tuning, Gemini Robotics can be specialized to new capabilities including solving long-horizon, highly dexterous tasks, learning new short-horizon tasks from as few as 100 demonstrations and adapting to completely novel robot embodiments. This is made possible because Gemini Robotics builds on top of the Gemini Robotics-ER model, the second model we introduce in this work. Gemini Robotics-ER (Embodied Reasoning) extends Gemini's multimodal reasoning capabilities into the physical world, with enhanced spatial and temporal understanding. This enables capabilities relevant to robotics including object detection, pointing, trajectory and grasp prediction, as well as multi-view correspondence and 3D bounding box predictions. We show how this novel combination can support a variety of robotics applications. We also discuss and address important safety considerations related to this new class of robotics foundation models. The Gemini Robotics family marks a substantial step towards developing general-purpose robots that realizes AI's potential in the physical world.
Proc4Gem: Foundation models for physical agency through procedural generation
Mar 11, 2025



In robot learning, it is common to either ignore the environment semantics, focusing on tasks like whole-body control which only require reasoning about robot-environment contacts, or conversely to ignore contact dynamics, focusing on grounding high-level movement in vision and language. In this work, we show that advances in generative modeling, photorealistic rendering, and procedural generation allow us to tackle tasks requiring both. By generating contact-rich trajectories with accurate physics in semantically-diverse simulations, we can distill behaviors into large multimodal models that directly transfer to the real world: a system we call Proc4Gem. Specifically, we show that a foundation model, Gemini, fine-tuned on only simulation data, can be instructed in language to control a quadruped robot to push an object with its body to unseen targets in unseen real-world environments. Our real-world results demonstrate the promise of using simulation to imbue foundation models with physical agency. Videos can be found at our website: https://sites.google.com/view/proc4gem
DemoStart: Demonstration-led auto-curriculum applied to sim-to-real with multi-fingered robots
Sep 10, 2024

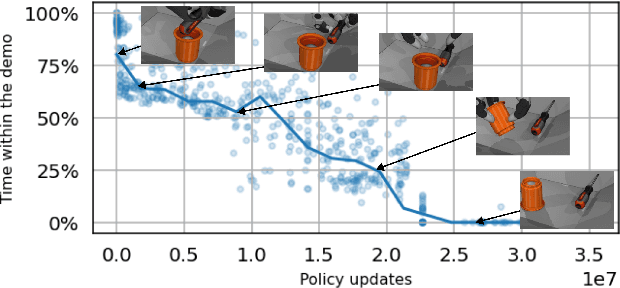
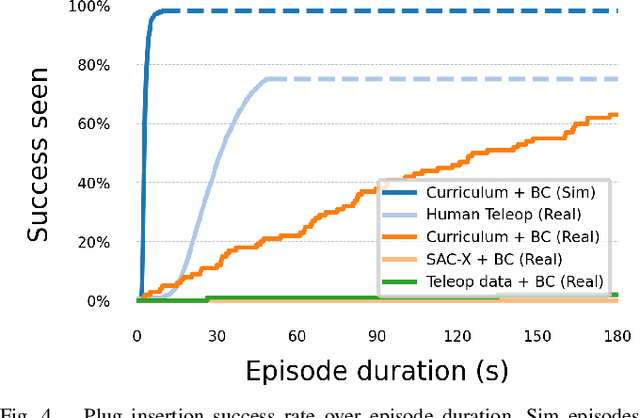
We present DemoStart, a novel auto-curriculum reinforcement learning method capable of learning complex manipulation behaviors on an arm equipped with a three-fingered robotic hand, from only a sparse reward and a handful of demonstrations in simulation. Learning from simulation drastically reduces the development cycle of behavior generation, and domain randomization techniques are leveraged to achieve successful zero-shot sim-to-real transfer. Transferred policies are learned directly from raw pixels from multiple cameras and robot proprioception. Our approach outperforms policies learned from demonstrations on the real robot and requires 100 times fewer demonstrations, collected in simulation. More details and videos in https://sites.google.com/view/demostart.
Learning Robot Soccer from Egocentric Vision with Deep Reinforcement Learning
May 03, 2024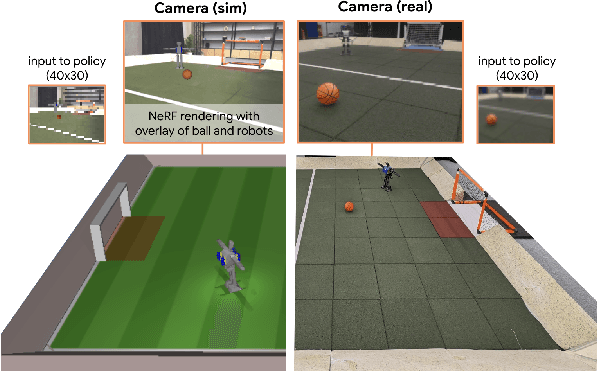
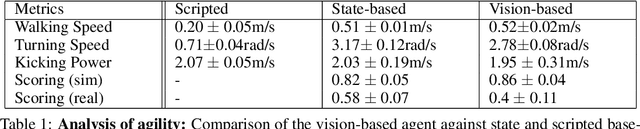
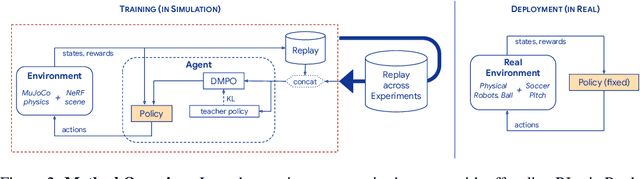
We apply multi-agent deep reinforcement learning (RL) to train end-to-end robot soccer policies with fully onboard computation and sensing via egocentric RGB vision. This setting reflects many challenges of real-world robotics, including active perception, agile full-body control, and long-horizon planning in a dynamic, partially-observable, multi-agent domain. We rely on large-scale, simulation-based data generation to obtain complex behaviors from egocentric vision which can be successfully transferred to physical robots using low-cost sensors. To achieve adequate visual realism, our simulation combines rigid-body physics with learned, realistic rendering via multiple Neural Radiance Fields (NeRFs). We combine teacher-based multi-agent RL and cross-experiment data reuse to enable the discovery of sophisticated soccer strategies. We analyze active-perception behaviors including object tracking and ball seeking that emerge when simply optimizing perception-agnostic soccer play. The agents display equivalent levels of performance and agility as policies with access to privileged, ground-truth state. To our knowledge, this paper constitutes a first demonstration of end-to-end training for multi-agent robot soccer, mapping raw pixel observations to joint-level actions, that can be deployed in the real world. Videos of the game-play and analyses can be seen on our website https://sites.google.com/view/vision-soccer .
Mastering Stacking of Diverse Shapes with Large-Scale Iterative Reinforcement Learning on Real Robots
Dec 18, 2023


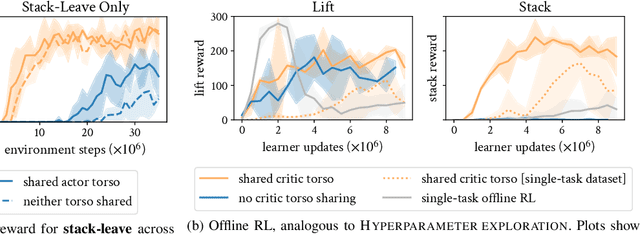
Reinforcement learning solely from an agent's self-generated data is often believed to be infeasible for learning on real robots, due to the amount of data needed. However, if done right, agents learning from real data can be surprisingly efficient through re-using previously collected sub-optimal data. In this paper we demonstrate how the increased understanding of off-policy learning methods and their embedding in an iterative online/offline scheme (``collect and infer'') can drastically improve data-efficiency by using all the collected experience, which empowers learning from real robot experience only. Moreover, the resulting policy improves significantly over the state of the art on a recently proposed real robot manipulation benchmark. Our approach learns end-to-end, directly from pixels, and does not rely on additional human domain knowledge such as a simulator or demonstrations.
RoboCat: A Self-Improving Foundation Agent for Robotic Manipulation
Jun 20, 2023



The ability to leverage heterogeneous robotic experience from different robots and tasks to quickly master novel skills and embodiments has the potential to transform robot learning. Inspired by recent advances in foundation models for vision and language, we propose a foundation agent for robotic manipulation. This agent, named RoboCat, is a visual goal-conditioned decision transformer capable of consuming multi-embodiment action-labelled visual experience. This data spans a large repertoire of motor control skills from simulated and real robotic arms with varying sets of observations and actions. With RoboCat, we demonstrate the ability to generalise to new tasks and robots, both zero-shot as well as through adaptation using only 100--1000 examples for the target task. We also show how a trained model itself can be used to generate data for subsequent training iterations, thus providing a basic building block for an autonomous improvement loop. We investigate the agent's capabilities, with large-scale evaluations both in simulation and on three different real robot embodiments. We find that as we grow and diversify its training data, RoboCat not only shows signs of cross-task transfer, but also becomes more efficient at adapting to new tasks.
Barkour: Benchmarking Animal-level Agility with Quadruped Robots
May 24, 2023
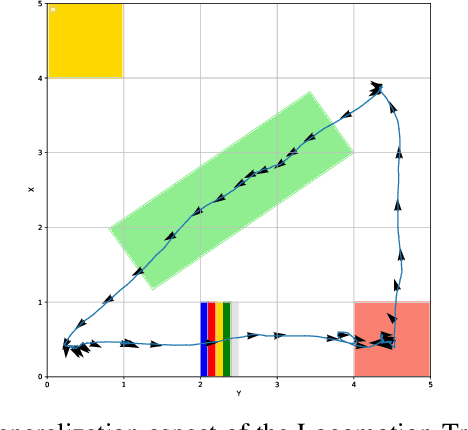
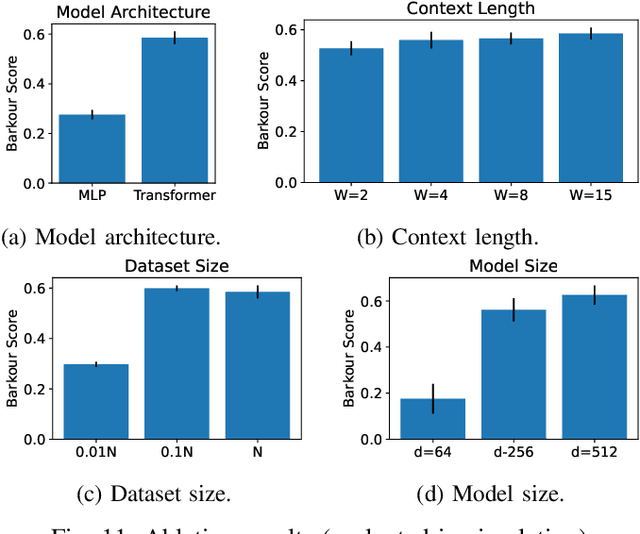

Animals have evolved various agile locomotion strategies, such as sprinting, leaping, and jumping. There is a growing interest in developing legged robots that move like their biological counterparts and show various agile skills to navigate complex environments quickly. Despite the interest, the field lacks systematic benchmarks to measure the performance of control policies and hardware in agility. We introduce the Barkour benchmark, an obstacle course to quantify agility for legged robots. Inspired by dog agility competitions, it consists of diverse obstacles and a time based scoring mechanism. This encourages researchers to develop controllers that not only move fast, but do so in a controllable and versatile way. To set strong baselines, we present two methods for tackling the benchmark. In the first approach, we train specialist locomotion skills using on-policy reinforcement learning methods and combine them with a high-level navigation controller. In the second approach, we distill the specialist skills into a Transformer-based generalist locomotion policy, named Locomotion-Transformer, that can handle various terrains and adjust the robot's gait based on the perceived environment and robot states. Using a custom-built quadruped robot, we demonstrate that our method can complete the course at half the speed of a dog. We hope that our work represents a step towards creating controllers that enable robots to reach animal-level agility.
Learning Agile Soccer Skills for a Bipedal Robot with Deep Reinforcement Learning
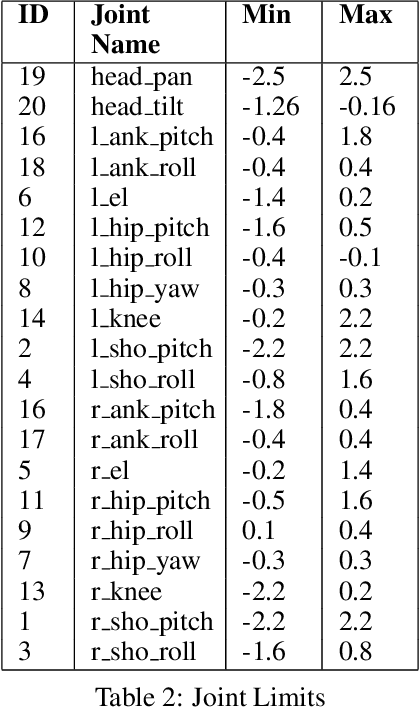
Apr 26, 2023We investigate whether Deep Reinforcement Learning (Deep RL) is able to synthesize sophisticated and safe movement skills for a low-cost, miniature humanoid robot that can be composed into complex behavioral strategies in dynamic environments. We used Deep RL to train a humanoid robot with 20 actuated joints to play a simplified one-versus-one (1v1) soccer game. We first trained individual skills in isolation and then composed those skills end-to-end in a self-play setting. The resulting policy exhibits robust and dynamic movement skills such as rapid fall recovery, walking, turning, kicking and more; and transitions between them in a smooth, stable, and efficient manner - well beyond what is intuitively expected from the robot. The agents also developed a basic strategic understanding of the game, and learned, for instance, to anticipate ball movements and to block opponent shots. The full range of behaviors emerged from a small set of simple rewards. Our agents were trained in simulation and transferred to real robots zero-shot. We found that a combination of sufficiently high-frequency control, targeted dynamics randomization, and perturbations during training in simulation enabled good-quality transfer, despite significant unmodeled effects and variations across robot instances. Although the robots are inherently fragile, minor hardware modifications together with basic regularization of the behavior during training led the robots to learn safe and effective movements while still performing in a dynamic and agile way. Indeed, even though the agents were optimized for scoring, in experiments they walked 156% faster, took 63% less time to get up, and kicked 24% faster than a scripted baseline, while efficiently combining the skills to achieve the longer term objectives. Examples of the emergent behaviors and full 1v1 matches are available on the supplementary website.