 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDemoStart: Demonstration-led auto-curriculum applied to sim-to-real with multi-fingered robots
Sep 10, 2024

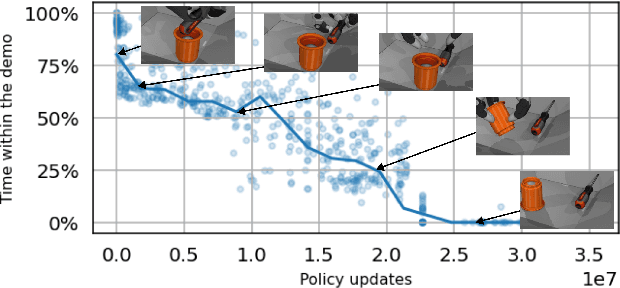
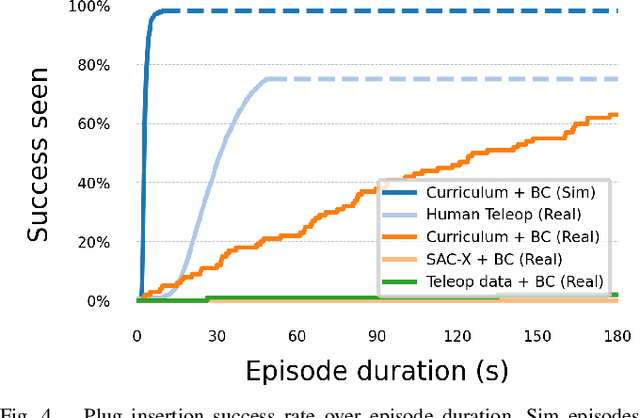
We present DemoStart, a novel auto-curriculum reinforcement learning method capable of learning complex manipulation behaviors on an arm equipped with a three-fingered robotic hand, from only a sparse reward and a handful of demonstrations in simulation. Learning from simulation drastically reduces the development cycle of behavior generation, and domain randomization techniques are leveraged to achieve successful zero-shot sim-to-real transfer. Transferred policies are learned directly from raw pixels from multiple cameras and robot proprioception. Our approach outperforms policies learned from demonstrations on the real robot and requires 100 times fewer demonstrations, collected in simulation. More details and videos in https://sites.google.com/view/demostart.
A Distributional View on Multi-Objective Policy Optimization
May 15, 2020
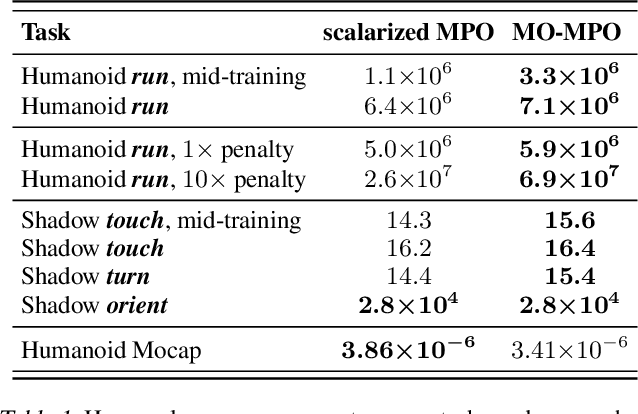
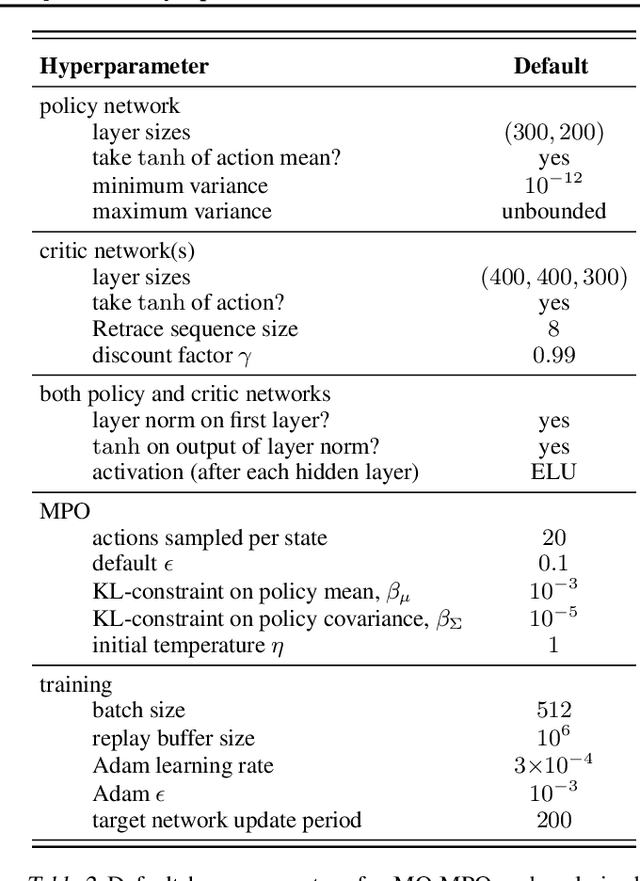
Many real-world problems require trading off multiple competing objectives. However, these objectives are often in different units and/or scales, which can make it challenging for practitioners to express numerical preferences over objectives in their native units. In this paper we propose a novel algorithm for multi-objective reinforcement learning that enables setting desired preferences for objectives in a scale-invariant way. We propose to learn an action distribution for each objective, and we use supervised learning to fit a parametric policy to a combination of these distributions. We demonstrate the effectiveness of our approach on challenging high-dimensional real and simulated robotics tasks, and show that setting different preferences in our framework allows us to trace out the space of nondominated solutions.
Learning Gentle Object Manipulation with Curiosity-Driven Deep Reinforcement Learning
Mar 20, 2019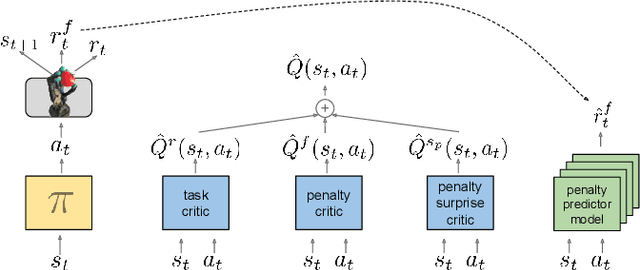

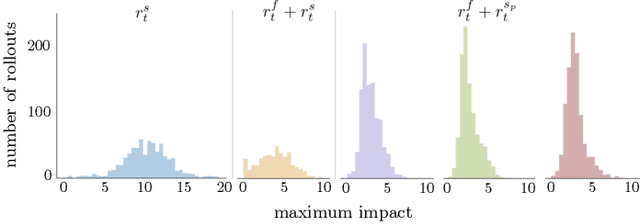

Robots must know how to be gentle when they need to interact with fragile objects, or when the robot itself is prone to wear and tear. We propose an approach that enables deep reinforcement learning to train policies that are gentle, both during exploration and task execution. In a reward-based learning environment, a natural approach involves augmenting the (task) reward with a penalty for non-gentleness, which can be defined as excessive impact force. However, augmenting with only this penalty impairs learning: policies get stuck in a local optimum which avoids all contact with the environment. Prior research has shown that combining auxiliary tasks or intrinsic rewards can be beneficial for stabilizing and accelerating learning in sparse-reward domains, and indeed we find that introducing a surprise-based intrinsic reward does avoid the no-contact failure case. However, we show that a simple dynamics-based surprise is not as effective as penalty-based surprise. Penalty-based surprise, based on predicting forceful contacts, has a further benefit: it encourages exploration which is contact-rich yet gentle. We demonstrate the effectiveness of the approach using a complex, tendon-powered robot hand with tactile sensors. Videos are available at http://sites.google.com/view/gentlemanipulation.
Simultaneously Learning Vision and Feature-based Control Policies for Real-world Ball-in-a-Cup
Feb 18, 2019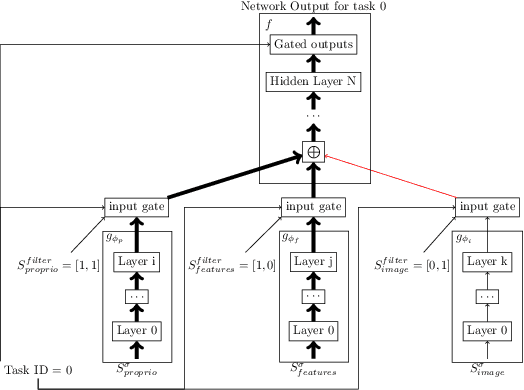

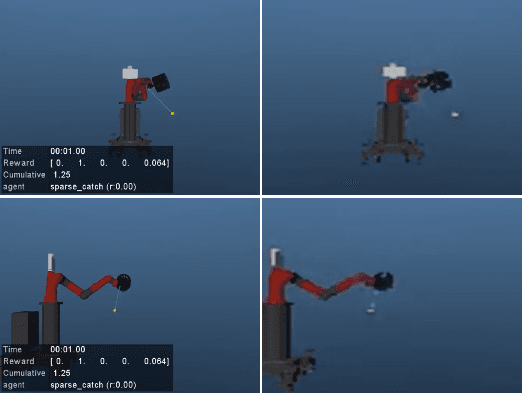

We present a method for fast training of vision based control policies on real robots. The key idea behind our method is to perform multi-task Reinforcement Learning with auxiliary tasks that differ not only in the reward to be optimized but also in the state-space in which they operate. In particular, we allow auxiliary task policies to utilize task features that are available only at training-time. This allows for fast learning of auxiliary policies, which subsequently generate good data for training the main, vision-based control policies. This method can be seen as an extension of the Scheduled Auxiliary Control (SAC-X) framework. We demonstrate the efficacy of our method by using both a simulated and real-world Ball-in-a-Cup game controlled by a robot arm. In simulation, our approach leads to significant learning speed-ups when compared to standard SAC-X. On the real robot we show that the task can be learned from-scratch, i.e., with no transfer from simulation and no imitation learning. Videos of our learned policies running on the real robot can be found at https://sites.google.com/view/rss-2019-sawyer-bic/.