 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeValue from Observations: Towards Large-Scale Imitation Learning via Self-Improvement
Jul 09, 2025Imitation Learning from Observation (IfO) offers a powerful way to learn behaviors at large-scale: Unlike behavior cloning or offline reinforcement learning, IfO can leverage action-free demonstrations and thus circumvents the need for costly action-labeled demonstrations or reward functions. However, current IfO research focuses on idealized scenarios with mostly bimodal-quality data distributions, restricting the meaningfulness of the results. In contrast, this paper investigates more nuanced distributions and introduces a method to learn from such data, moving closer to a paradigm in which imitation learning can be performed iteratively via self-improvement. Our method adapts RL-based imitation learning to action-free demonstrations, using a value function to transfer information between expert and non-expert data. Through comprehensive evaluation, we delineate the relation between different data distributions and the applicability of algorithms and highlight the limitations of established methods. Our findings provide valuable insights for developing more robust and practical IfO techniques on a path to scalable behaviour learning.
DemoStart: Demonstration-led auto-curriculum applied to sim-to-real with multi-fingered robots
Sep 10, 2024

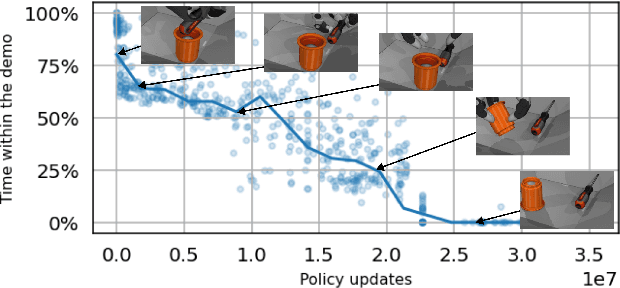
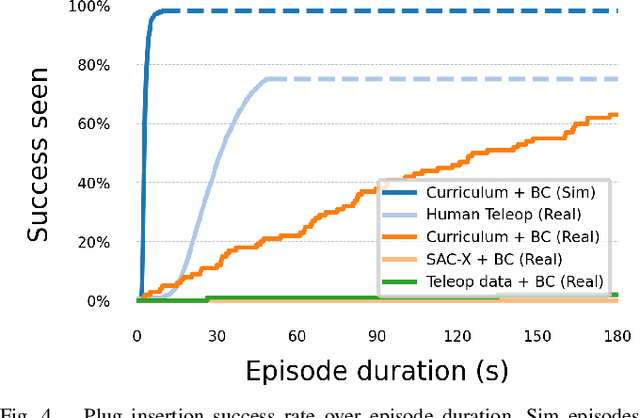
We present DemoStart, a novel auto-curriculum reinforcement learning method capable of learning complex manipulation behaviors on an arm equipped with a three-fingered robotic hand, from only a sparse reward and a handful of demonstrations in simulation. Learning from simulation drastically reduces the development cycle of behavior generation, and domain randomization techniques are leveraged to achieve successful zero-shot sim-to-real transfer. Transferred policies are learned directly from raw pixels from multiple cameras and robot proprioception. Our approach outperforms policies learned from demonstrations on the real robot and requires 100 times fewer demonstrations, collected in simulation. More details and videos in https://sites.google.com/view/demostart.
RoboCat: A Self-Improving Foundation Agent for Robotic Manipulation
Jun 20, 2023



The ability to leverage heterogeneous robotic experience from different robots and tasks to quickly master novel skills and embodiments has the potential to transform robot learning. Inspired by recent advances in foundation models for vision and language, we propose a foundation agent for robotic manipulation. This agent, named RoboCat, is a visual goal-conditioned decision transformer capable of consuming multi-embodiment action-labelled visual experience. This data spans a large repertoire of motor control skills from simulated and real robotic arms with varying sets of observations and actions. With RoboCat, we demonstrate the ability to generalise to new tasks and robots, both zero-shot as well as through adaptation using only 100--1000 examples for the target task. We also show how a trained model itself can be used to generate data for subsequent training iterations, thus providing a basic building block for an autonomous improvement loop. We investigate the agent's capabilities, with large-scale evaluations both in simulation and on three different real robot embodiments. We find that as we grow and diversify its training data, RoboCat not only shows signs of cross-task transfer, but also becomes more efficient at adapting to new tasks.
Learning Transferable Motor Skills with Hierarchical Latent Mixture Policies
Dec 09, 2021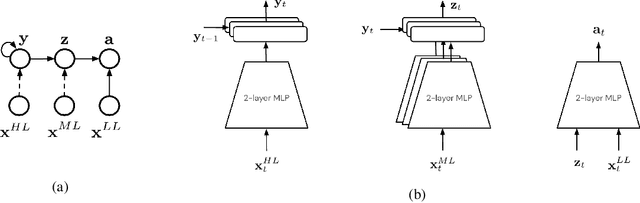
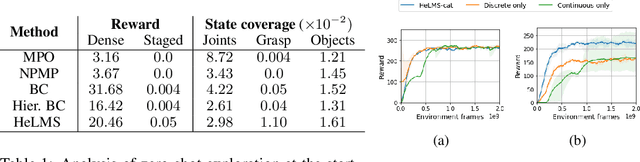
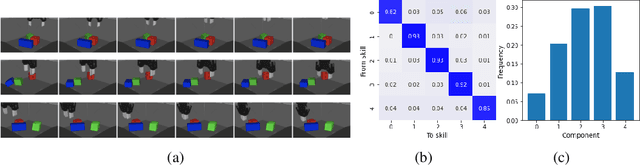
For robots operating in the real world, it is desirable to learn reusable behaviours that can effectively be transferred and adapted to numerous tasks and scenarios. We propose an approach to learn abstract motor skills from data using a hierarchical mixture latent variable model. In contrast to existing work, our method exploits a three-level hierarchy of both discrete and continuous latent variables, to capture a set of high-level behaviours while allowing for variance in how they are executed. We demonstrate in manipulation domains that the method can effectively cluster offline data into distinct, executable behaviours, while retaining the flexibility of a continuous latent variable model. The resulting skills can be transferred and fine-tuned on new tasks, unseen objects, and from state to vision-based policies, yielding better sample efficiency and asymptotic performance compared to existing skill- and imitation-based methods. We further analyse how and when the skills are most beneficial: they encourage directed exploration to cover large regions of the state space relevant to the task, making them most effective in challenging sparse-reward settings.
Learning rich touch representations through cross-modal self-supervision
Jan 21, 2021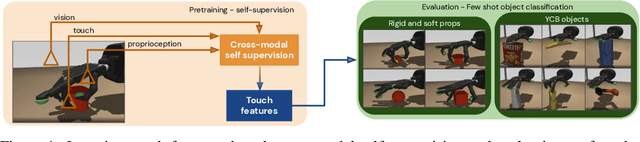
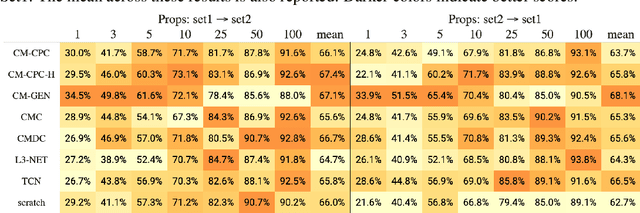
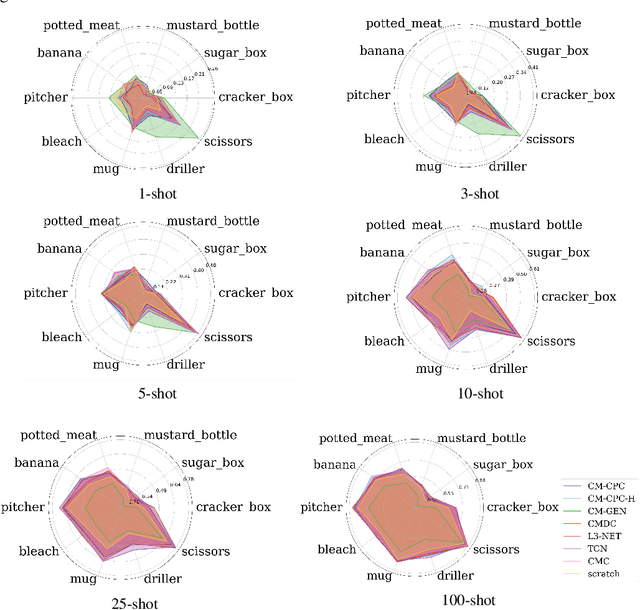
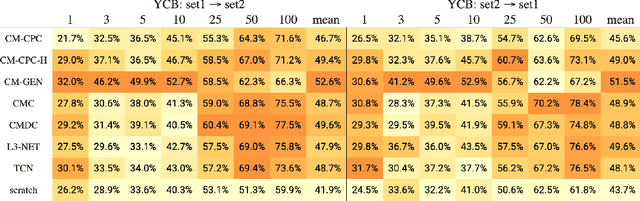
The sense of touch is fundamental in several manipulation tasks, but rarely used in robot manipulation. In this work we tackle the problem of learning rich touch features from cross-modal self-supervision. We evaluate them identifying objects and their properties in a few-shot classification setting. Two new datasets are introduced using a simulated anthropomorphic robotic hand equipped with tactile sensors on both synthetic and daily life objects. Several self-supervised learning methods are benchmarked on these datasets, by evaluating few-shot classification on unseen objects and poses. Our experiments indicate that cross-modal self-supervision effectively improves touch representation, and in turn has great potential to enhance robot manipulation skills.
A Distributional View on Multi-Objective Policy Optimization
May 15, 2020
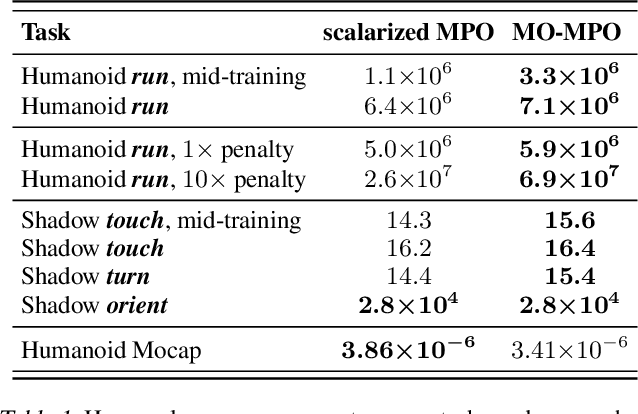
Many real-world problems require trading off multiple competing objectives. However, these objectives are often in different units and/or scales, which can make it challenging for practitioners to express numerical preferences over objectives in their native units. In this paper we propose a novel algorithm for multi-objective reinforcement learning that enables setting desired preferences for objectives in a scale-invariant way. We propose to learn an action distribution for each objective, and we use supervised learning to fit a parametric policy to a combination of these distributions. We demonstrate the effectiveness of our approach on challenging high-dimensional real and simulated robotics tasks, and show that setting different preferences in our framework allows us to trace out the space of nondominated solutions.
Multimodal representation models for prediction and control from partial information
Oct 09, 2019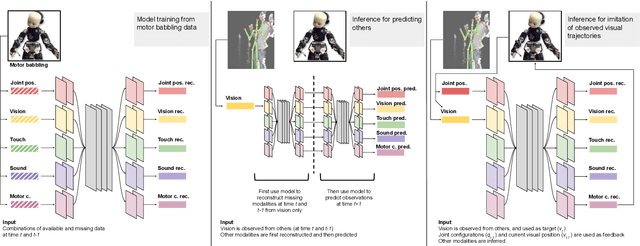



Similar to humans, robots benefit from interacting with their environment through a number of different sensor modalities, such as vision, touch, sound. However, learning from different sensor modalities is difficult, because the learning model must be able to handle diverse types of signals, and learn a coherent representation even when parts of the sensor inputs are missing. In this paper, a multimodal variational autoencoder is proposed to enable an iCub humanoid robot to learn representations of its sensorimotor capabilities from different sensor modalities. The proposed model is able to (1) reconstruct missing sensory modalities, (2) predict the sensorimotor state of self and the visual trajectories of other agents actions, and (3) control the agent to imitate an observed visual trajectory. Also, the proposed multimodal variational autoencoder can capture the kinematic redundancy of the robot motion through the learned probability distribution. Training multimodal models is not trivial due to the combinatorial complexity given by the possibility of missing modalities. We propose a strategy to train multimodal models, which successfully achieves improved performance of different reconstruction models. Finally, extensive experiments have been carried out using an iCub humanoid robot, showing high performance in multiple reconstruction, prediction and imitation tasks.
Learning Gentle Object Manipulation with Curiosity-Driven Deep Reinforcement Learning
Mar 20, 2019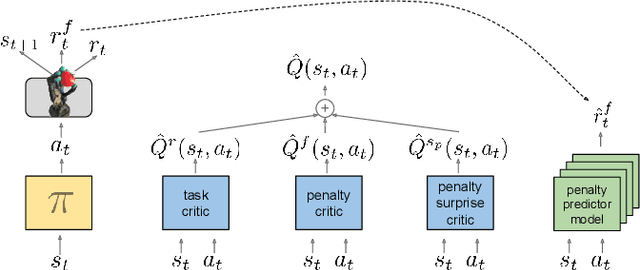

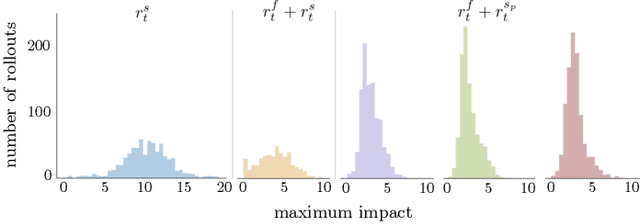

Robots must know how to be gentle when they need to interact with fragile objects, or when the robot itself is prone to wear and tear. We propose an approach that enables deep reinforcement learning to train policies that are gentle, both during exploration and task execution. In a reward-based learning environment, a natural approach involves augmenting the (task) reward with a penalty for non-gentleness, which can be defined as excessive impact force. However, augmenting with only this penalty impairs learning: policies get stuck in a local optimum which avoids all contact with the environment. Prior research has shown that combining auxiliary tasks or intrinsic rewards can be beneficial for stabilizing and accelerating learning in sparse-reward domains, and indeed we find that introducing a surprise-based intrinsic reward does avoid the no-contact failure case. However, we show that a simple dynamics-based surprise is not as effective as penalty-based surprise. Penalty-based surprise, based on predicting forceful contacts, has a further benefit: it encourages exploration which is contact-rich yet gentle. We demonstrate the effectiveness of the approach using a complex, tendon-powered robot hand with tactile sensors. Videos are available at http://sites.google.com/view/gentlemanipulation.
DAC-h3: A Proactive Robot Cognitive Architecture to Acquire and Express Knowledge About the World and the Self
Sep 18, 2017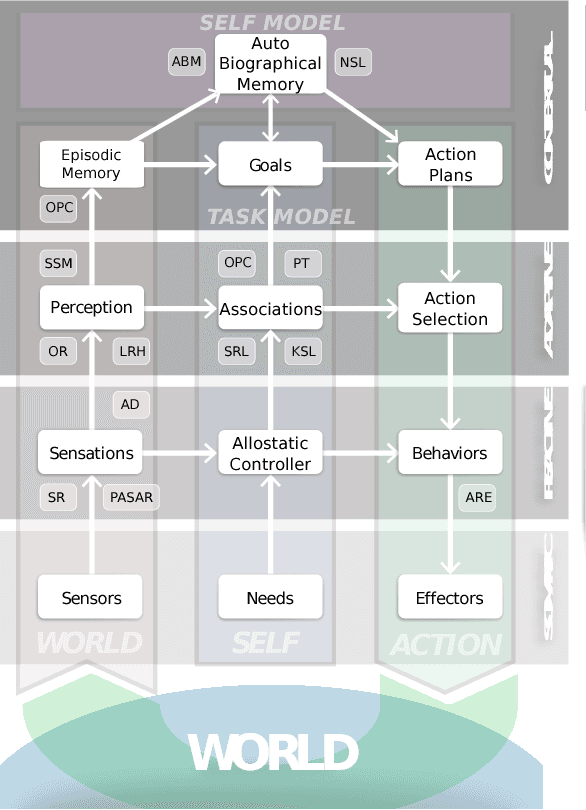
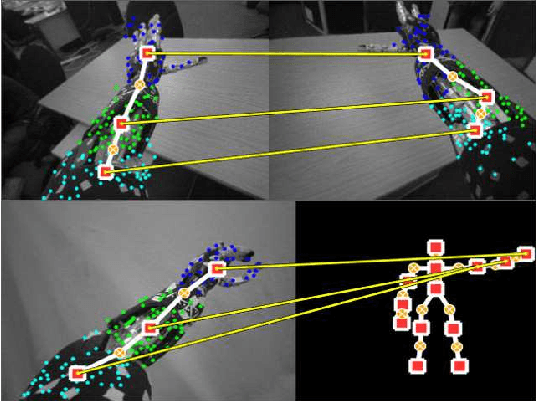


This paper introduces a cognitive architecture for a humanoid robot to engage in a proactive, mixed-initiative exploration and manipulation of its environment, where the initiative can originate from both the human and the robot. The framework, based on a biologically-grounded theory of the brain and mind, integrates a reactive interaction engine, a number of state-of-the-art perceptual and motor learning algorithms, as well as planning abilities and an autobiographical memory. The architecture as a whole drives the robot behavior to solve the symbol grounding problem, acquire language capabilities, execute goal-oriented behavior, and express a verbal narrative of its own experience in the world. We validate our approach in human-robot interaction experiments with the iCub humanoid robot, showing that the proposed cognitive architecture can be applied in real time within a realistic scenario and that it can be used with naive users.
* Preprint version; final version available at http://ieeexplore.ieee.org/ IEEE Transactions on Cognitive and Developmental Systems (Accepted) DOI: 10.1109/TCDS.2017.2754143