 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoboCat: A Self-Improving Foundation Agent for Robotic Manipulation
Jun 20, 2023



The ability to leverage heterogeneous robotic experience from different robots and tasks to quickly master novel skills and embodiments has the potential to transform robot learning. Inspired by recent advances in foundation models for vision and language, we propose a foundation agent for robotic manipulation. This agent, named RoboCat, is a visual goal-conditioned decision transformer capable of consuming multi-embodiment action-labelled visual experience. This data spans a large repertoire of motor control skills from simulated and real robotic arms with varying sets of observations and actions. With RoboCat, we demonstrate the ability to generalise to new tasks and robots, both zero-shot as well as through adaptation using only 100--1000 examples for the target task. We also show how a trained model itself can be used to generate data for subsequent training iterations, thus providing a basic building block for an autonomous improvement loop. We investigate the agent's capabilities, with large-scale evaluations both in simulation and on three different real robot embodiments. We find that as we grow and diversify its training data, RoboCat not only shows signs of cross-task transfer, but also becomes more efficient at adapting to new tasks.
Vision-Language Models as Success Detectors
Mar 13, 2023Detecting successful behaviour is crucial for training intelligent agents. As such, generalisable reward models are a prerequisite for agents that can learn to generalise their behaviour. In this work we focus on developing robust success detectors that leverage large, pretrained vision-language models (Flamingo, Alayrac et al. (2022)) and human reward annotations. Concretely, we treat success detection as a visual question answering (VQA) problem, denoted SuccessVQA. We study success detection across three vastly different domains: (i) interactive language-conditioned agents in a simulated household, (ii) real world robotic manipulation, and (iii) "in-the-wild" human egocentric videos. We investigate the generalisation properties of a Flamingo-based success detection model across unseen language and visual changes in the first two domains, and find that the proposed method is able to outperform bespoke reward models in out-of-distribution test scenarios with either variation. In the last domain of "in-the-wild" human videos, we show that success detection on unseen real videos presents an even more challenging generalisation task warranting future work. We hope our initial results encourage further work in real world success detection and reward modelling.
Beyond Pick-and-Place: Tackling Robotic Stacking of Diverse Shapes
Nov 03, 2021
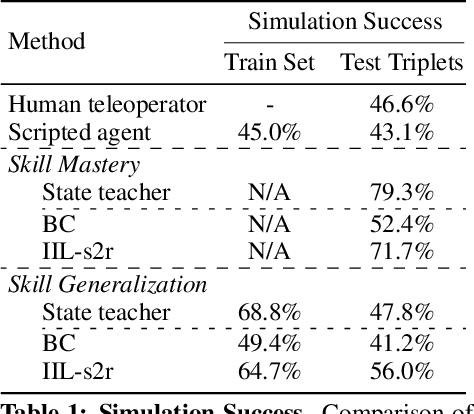
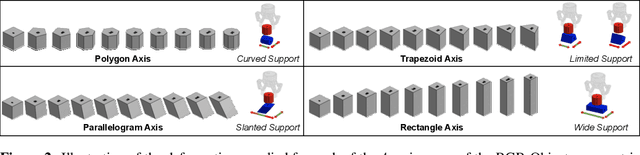
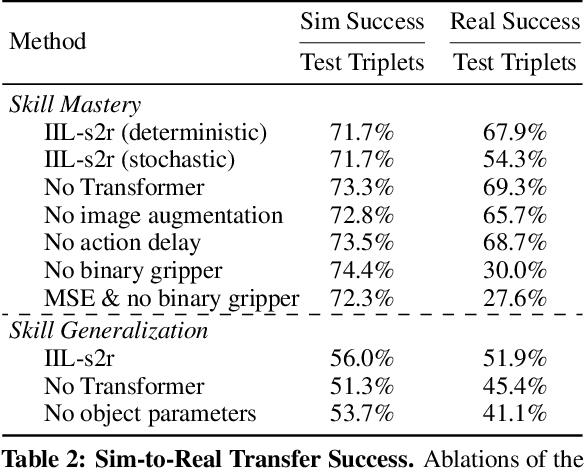
We study the problem of robotic stacking with objects of complex geometry. We propose a challenging and diverse set of such objects that was carefully designed to require strategies beyond a simple "pick-and-place" solution. Our method is a reinforcement learning (RL) approach combined with vision-based interactive policy distillation and simulation-to-reality transfer. Our learned policies can efficiently handle multiple object combinations in the real world and exhibit a large variety of stacking skills. In a large experimental study, we investigate what choices matter for learning such general vision-based agents in simulation, and what affects optimal transfer to the real robot. We then leverage data collected by such policies and improve upon them with offline RL. A video and a blog post of our work are provided as supplementary material.