 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision-Language Model Dialog Games for Self-Improvement
Feb 04, 2025



The increasing demand for high-quality, diverse training data poses a significant bottleneck in advancing vision-language models (VLMs). This paper presents VLM Dialog Games, a novel and scalable self-improvement framework for VLMs. Our approach leverages self-play between two agents engaged in a goal-oriented play centered around image identification. By filtering for successful game interactions, we automatically curate a high-quality dataset of interleaved images and text. We demonstrate that fine-tuning on this synthetic data leads to performance gains on downstream tasks and generalises across datasets. Moreover, as the improvements in the model lead to better game play, this procedure can be applied iteratively. This work paves the way for self-improving VLMs, with potential applications in various real-world scenarios especially when the high-quality multimodal data is scarce.
Rapid Object Annotation
Jul 26, 2024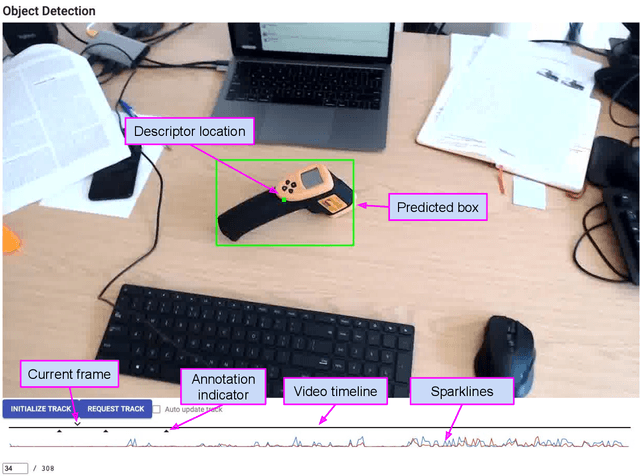


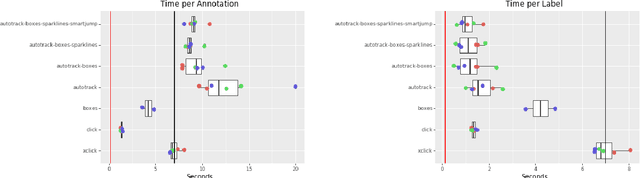
In this report we consider the problem of rapidly annotating a video with bounding boxes for a novel object. We describe a UI and associated workflow designed to make this process fast for an arbitrary novel target.
RoboCat: A Self-Improving Foundation Agent for Robotic Manipulation
Jun 20, 2023



The ability to leverage heterogeneous robotic experience from different robots and tasks to quickly master novel skills and embodiments has the potential to transform robot learning. Inspired by recent advances in foundation models for vision and language, we propose a foundation agent for robotic manipulation. This agent, named RoboCat, is a visual goal-conditioned decision transformer capable of consuming multi-embodiment action-labelled visual experience. This data spans a large repertoire of motor control skills from simulated and real robotic arms with varying sets of observations and actions. With RoboCat, we demonstrate the ability to generalise to new tasks and robots, both zero-shot as well as through adaptation using only 100--1000 examples for the target task. We also show how a trained model itself can be used to generate data for subsequent training iterations, thus providing a basic building block for an autonomous improvement loop. We investigate the agent's capabilities, with large-scale evaluations both in simulation and on three different real robot embodiments. We find that as we grow and diversify its training data, RoboCat not only shows signs of cross-task transfer, but also becomes more efficient at adapting to new tasks.
$\pi2\text{vec}$: Policy Representations with Successor Features
Jun 16, 2023



This paper describes $\pi2\text{vec}$, a method for representing behaviors of black box policies as feature vectors. The policy representations capture how the statistics of foundation model features change in response to the policy behavior in a task agnostic way, and can be trained from offline data, allowing them to be used in offline policy selection. This work provides a key piece of a recipe for fusing together three modern lines of research: Offline policy evaluation as a counterpart to offline RL, foundation models as generic and powerful state representations, and efficient policy selection in resource constrained environments.
Vision-Language Models as Success Detectors
Mar 13, 2023Detecting successful behaviour is crucial for training intelligent agents. As such, generalisable reward models are a prerequisite for agents that can learn to generalise their behaviour. In this work we focus on developing robust success detectors that leverage large, pretrained vision-language models (Flamingo, Alayrac et al. (2022)) and human reward annotations. Concretely, we treat success detection as a visual question answering (VQA) problem, denoted SuccessVQA. We study success detection across three vastly different domains: (i) interactive language-conditioned agents in a simulated household, (ii) real world robotic manipulation, and (iii) "in-the-wild" human egocentric videos. We investigate the generalisation properties of a Flamingo-based success detection model across unseen language and visual changes in the first two domains, and find that the proposed method is able to outperform bespoke reward models in out-of-distribution test scenarios with either variation. In the last domain of "in-the-wild" human videos, we show that success detection on unseen real videos presents an even more challenging generalisation task warranting future work. We hope our initial results encourage further work in real world success detection and reward modelling.
Interactive decoding of words from visual speech recognition models
Jul 01, 2021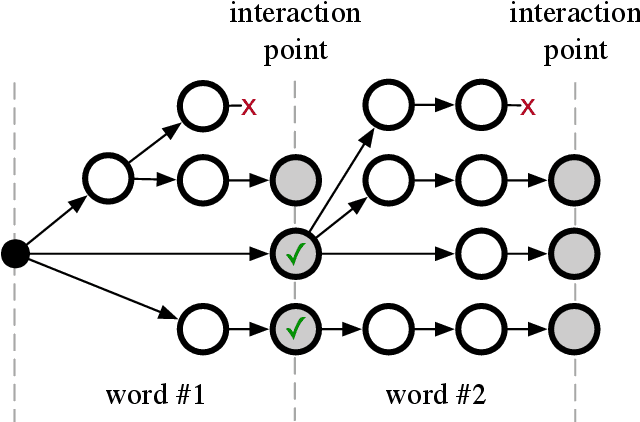


This work describes an interactive decoding method to improve the performance of visual speech recognition systems using user input to compensate for the inherent ambiguity of the task. Unlike most phoneme-to-word decoding pipelines, which produce phonemes and feed these through a finite state transducer, our method instead expands words in lockstep, facilitating the insertion of interaction points at each word position. Interaction points enable us to solicit input during decoding, allowing users to interactively direct the decoding process. We simulate the behavior of user input using an oracle to give an automated evaluation, and show promise for the use of this method for text input.
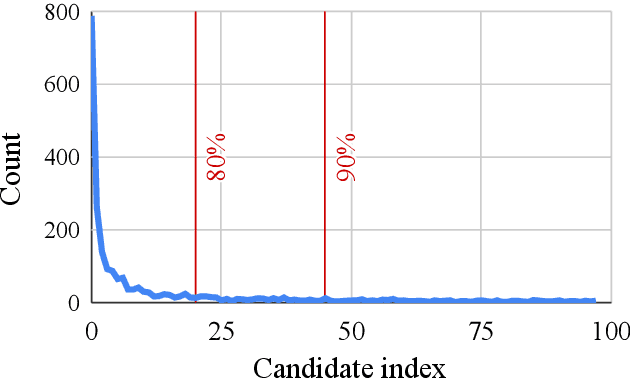
Active Offline Policy Selection
Jun 18, 2021
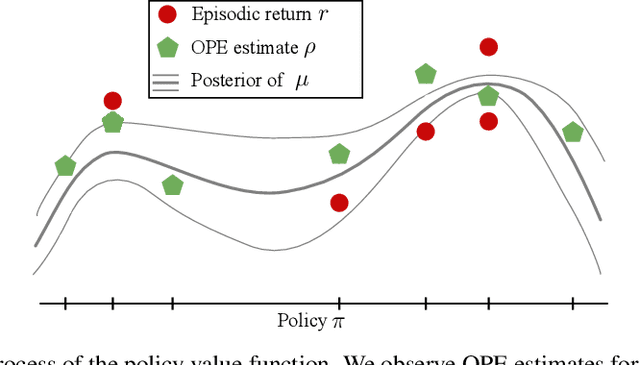
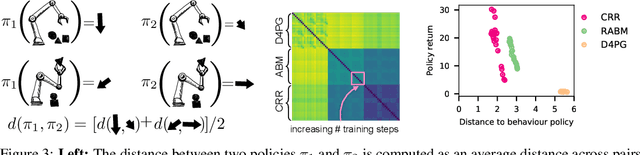

This paper addresses the problem of policy selection in domains with abundant logged data, but with a very restricted interaction budget. Solving this problem would enable safe evaluation and deployment of offline reinforcement learning policies in industry, robotics, and healthcare domain among others. Several off-policy evaluation (OPE) techniques have been proposed to assess the value of policies using only logged data. However, there is still a big gap between the evaluation by OPE and the full online evaluation in the real environment. To reduce this gap, we introduce a novel \emph{active offline policy selection} problem formulation, which combined logged data and limited online interactions to identify the best policy. We rely on the advances in OPE to warm start the evaluation. We build upon Bayesian optimization to iteratively decide which policies to evaluate in order to utilize the limited environment interactions wisely. Many candidate policies could be proposed, thus, we focus on making our approach scalable and introduce a kernel function to model similarity between policies. We use several benchmark environments to show that the proposed approach improves upon state-of-the-art OPE estimates and fully online policy evaluation with limited budget. Additionally, we show that each component of the proposed method is important, it works well with various number and quality of OPE estimates and even with a large number of candidate policies.
Offline Learning from Demonstrations and Unlabeled Experience
Nov 27, 2020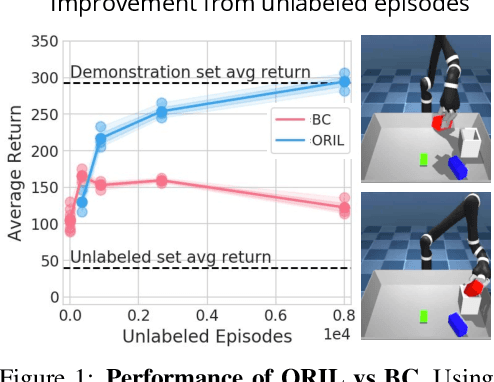
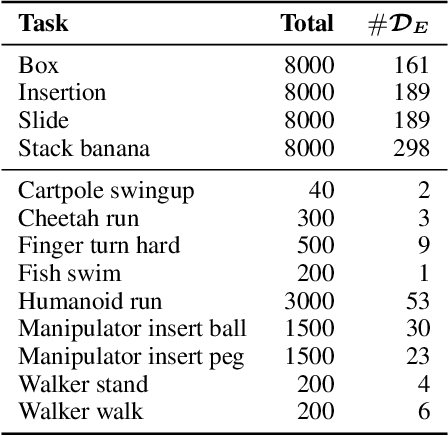
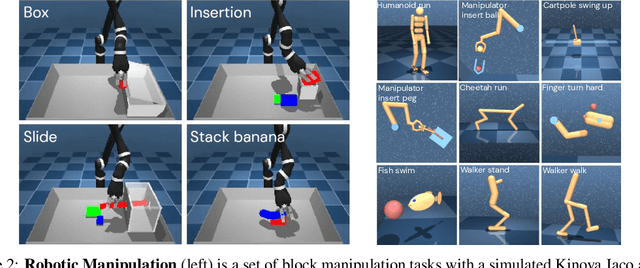

Behavior cloning (BC) is often practical for robot learning because it allows a policy to be trained offline without rewards, by supervised learning on expert demonstrations. However, BC does not effectively leverage what we will refer to as unlabeled experience: data of mixed and unknown quality without reward annotations. This unlabeled data can be generated by a variety of sources such as human teleoperation, scripted policies and other agents on the same robot. Towards data-driven offline robot learning that can use this unlabeled experience, we introduce Offline Reinforced Imitation Learning (ORIL). ORIL first learns a reward function by contrasting observations from demonstrator and unlabeled trajectories, then annotates all data with the learned reward, and finally trains an agent via offline reinforcement learning. Across a diverse set of continuous control and simulated robotic manipulation tasks, we show that ORIL consistently outperforms comparable BC agents by effectively leveraging unlabeled experience.
Large-scale multilingual audio visual dubbing
Nov 06, 2020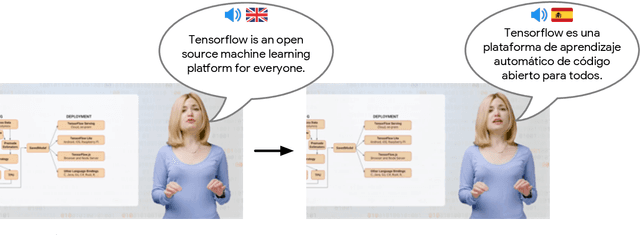
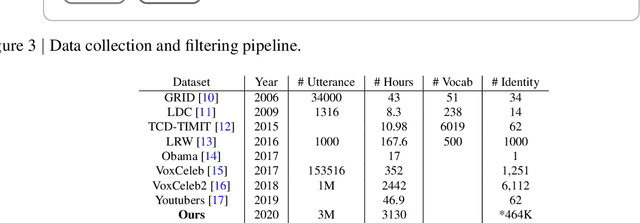
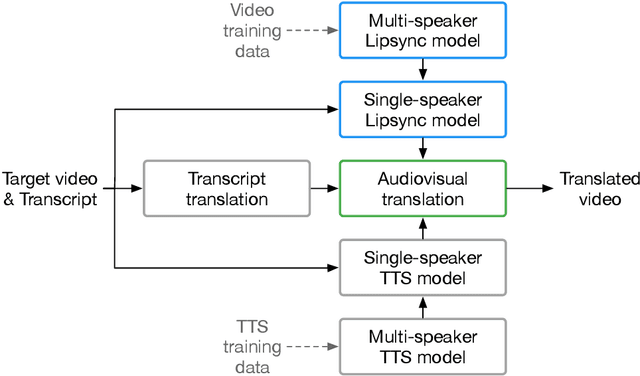
We describe a system for large-scale audiovisual translation and dubbing, which translates videos from one language to another. The source language's speech content is transcribed to text, translated, and automatically synthesized into target language speech using the original speaker's voice. The visual content is translated by synthesizing lip movements for the speaker to match the translated audio, creating a seamless audiovisual experience in the target language. The audio and visual translation subsystems each contain a large-scale generic synthesis model trained on thousands of hours of data in the corresponding domain. These generic models are fine-tuned to a specific speaker before translation, either using an auxiliary corpus of data from the target speaker, or using the video to be translated itself as the input to the fine-tuning process. This report gives an architectural overview of the full system, as well as an in-depth discussion of the video dubbing component. The role of the audio and text components in relation to the full system is outlined, but their design is not discussed in detail. Translated and dubbed demo videos generated using our system can be viewed at https://www.youtube.com/playlist?list=PLSi232j2ZA6_1Exhof5vndzyfbxAhhEs5
Positive-Unlabeled Reward Learning
Nov 01, 2019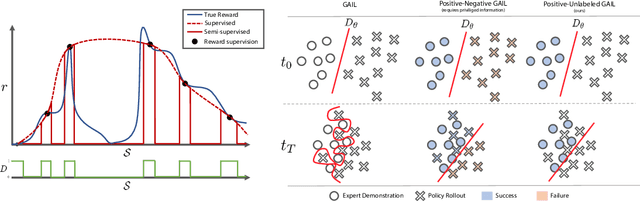

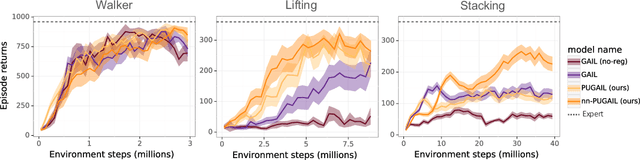
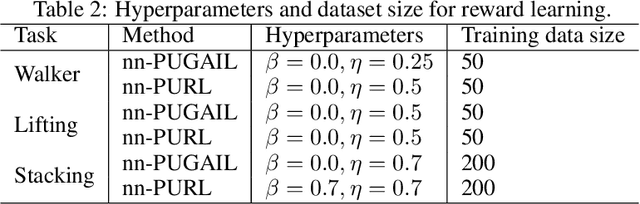
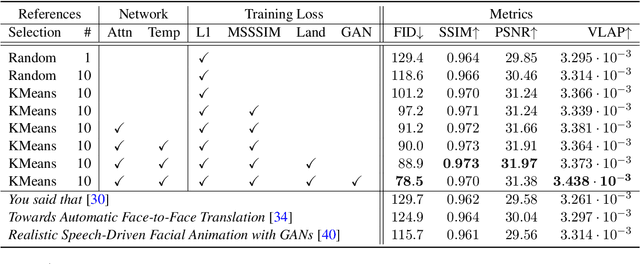
Learning reward functions from data is a promising path towards achieving scalable Reinforcement Learning (RL) for robotics. However, a major challenge in training agents from learned reward models is that the agent can learn to exploit errors in the reward model to achieve high reward behaviors that do not correspond to the intended task. These reward delusions can lead to unintended and even dangerous behaviors. On the other hand, adversarial imitation learning frameworks tend to suffer the opposite problem, where the discriminator learns to trivially distinguish agent and expert behavior, resulting in reward models that produce low reward signal regardless of the input state. In this paper, we connect these two classes of reward learning methods to positive-unlabeled (PU) learning, and we show that by applying a large-scale PU learning algorithm to the reward learning problem, we can address both the reward under- and over-estimation problems simultaneously. Our approach drastically improves both GAIL and supervised reward learning, without any additional assumptions.