 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive Offline Policy Selection
Jun 18, 2021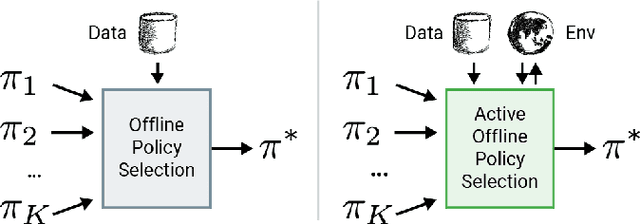
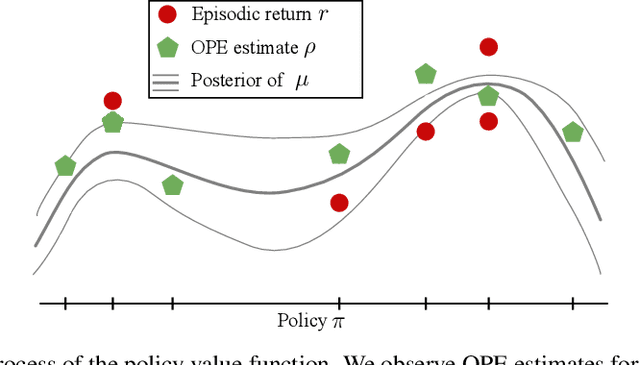
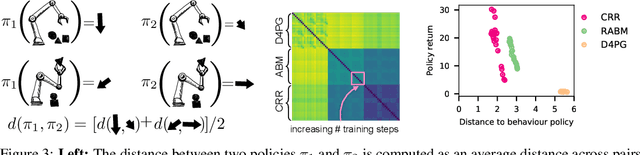

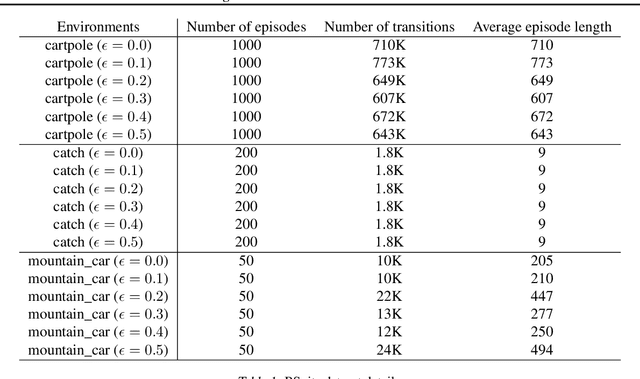
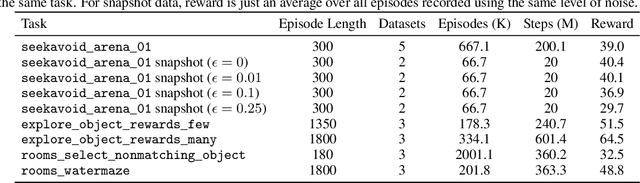
This paper addresses the problem of policy selection in domains with abundant logged data, but with a very restricted interaction budget. Solving this problem would enable safe evaluation and deployment of offline reinforcement learning policies in industry, robotics, and healthcare domain among others. Several off-policy evaluation (OPE) techniques have been proposed to assess the value of policies using only logged data. However, there is still a big gap between the evaluation by OPE and the full online evaluation in the real environment. To reduce this gap, we introduce a novel \emph{active offline policy selection} problem formulation, which combined logged data and limited online interactions to identify the best policy. We rely on the advances in OPE to warm start the evaluation. We build upon Bayesian optimization to iteratively decide which policies to evaluate in order to utilize the limited environment interactions wisely. Many candidate policies could be proposed, thus, we focus on making our approach scalable and introduce a kernel function to model similarity between policies. We use several benchmark environments to show that the proposed approach improves upon state-of-the-art OPE estimates and fully online policy evaluation with limited budget. Additionally, we show that each component of the proposed method is important, it works well with various number and quality of OPE estimates and even with a large number of candidate policies.
Regularized Behavior Value Estimation
Mar 17, 2021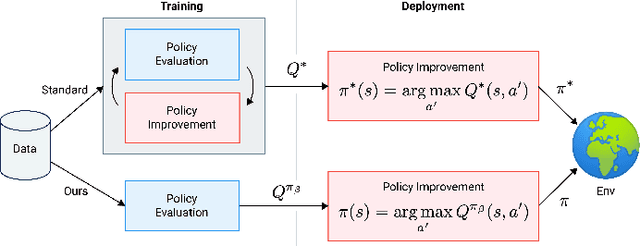
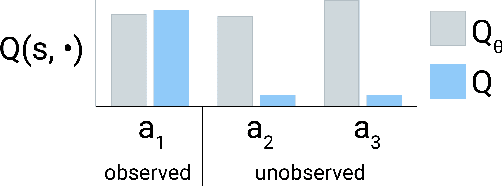
Offline reinforcement learning restricts the learning process to rely only on logged-data without access to an environment. While this enables real-world applications, it also poses unique challenges. One important challenge is dealing with errors caused by the overestimation of values for state-action pairs not well-covered by the training data. Due to bootstrapping, these errors get amplified during training and can lead to divergence, thereby crippling learning. To overcome this challenge, we introduce Regularized Behavior Value Estimation (R-BVE). Unlike most approaches, which use policy improvement during training, R-BVE estimates the value of the behavior policy during training and only performs policy improvement at deployment time. Further, R-BVE uses a ranking regularisation term that favours actions in the dataset that lead to successful outcomes. We provide ample empirical evidence of R-BVE's effectiveness, including state-of-the-art performance on the RL Unplugged ATARI dataset. We also test R-BVE on new datasets, from bsuite and a challenging DeepMind Lab task, and show that R-BVE outperforms other state-of-the-art discrete control offline RL methods.
Large-Scale Visual Speech Recognition
Oct 01, 2018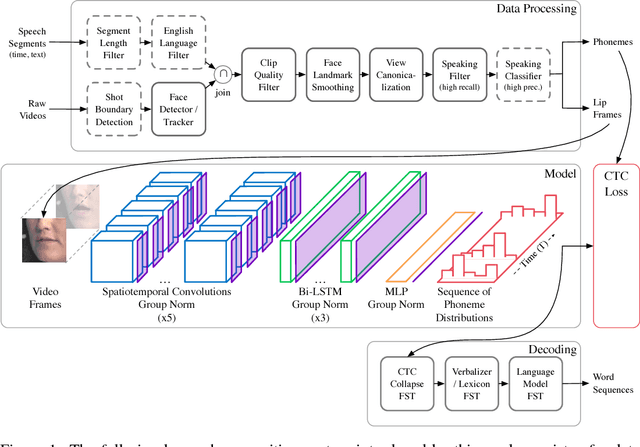
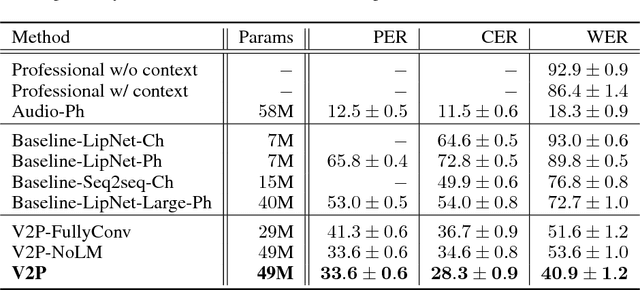


This work presents a scalable solution to open-vocabulary visual speech recognition. To achieve this, we constructed the largest existing visual speech recognition dataset, consisting of pairs of text and video clips of faces speaking (3,886 hours of video). In tandem, we designed and trained an integrated lipreading system, consisting of a video processing pipeline that maps raw video to stable videos of lips and sequences of phonemes, a scalable deep neural network that maps the lip videos to sequences of phoneme distributions, and a production-level speech decoder that outputs sequences of words. The proposed system achieves a word error rate (WER) of 40.9% as measured on a held-out set. In comparison, professional lipreaders achieve either 86.4% or 92.9% WER on the same dataset when having access to additional types of contextual information. Our approach significantly improves on other lipreading approaches, including variants of LipNet and of Watch, Attend, and Spell (WAS), which are only capable of 89.8% and 76.8% WER respectively.
Few-shot Autoregressive Density Estimation: Towards Learning to Learn Distributions
Feb 28, 2018
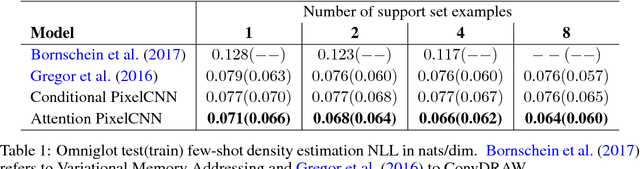

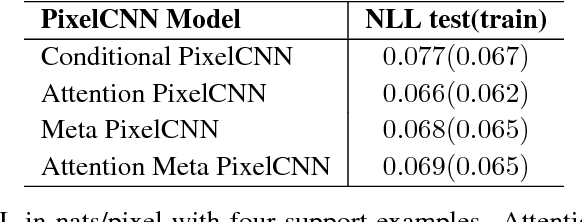
Deep autoregressive models have shown state-of-the-art performance in density estimation for natural images on large-scale datasets such as ImageNet. However, such models require many thousands of gradient-based weight updates and unique image examples for training. Ideally, the models would rapidly learn visual concepts from only a handful of examples, similar to the manner in which humans learns across many vision tasks. In this paper, we show how 1) neural attention and 2) meta learning techniques can be used in combination with autoregressive models to enable effective few-shot density estimation. Our proposed modifications to PixelCNN result in state-of-the art few-shot density estimation on the Omniglot dataset. Furthermore, we visualize the learned attention policy and find that it learns intuitive algorithms for simple tasks such as image mirroring on ImageNet and handwriting on Omniglot without supervision. Finally, we extend the model to natural images and demonstrate few-shot image generation on the Stanford Online Products dataset.
GPU Asynchronous Stochastic Gradient Descent to Speed Up Neural Network Training
Dec 21, 2013
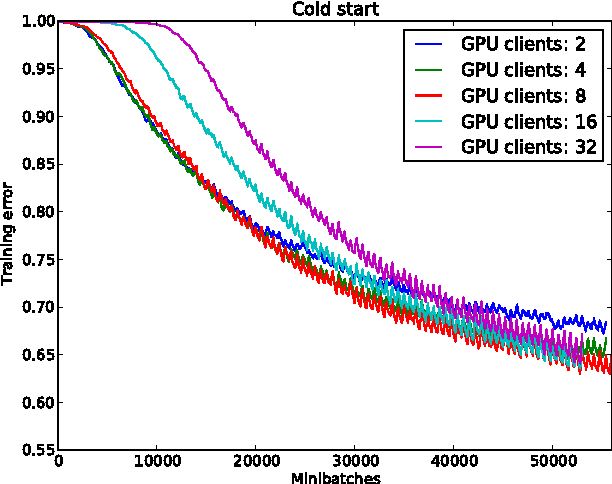
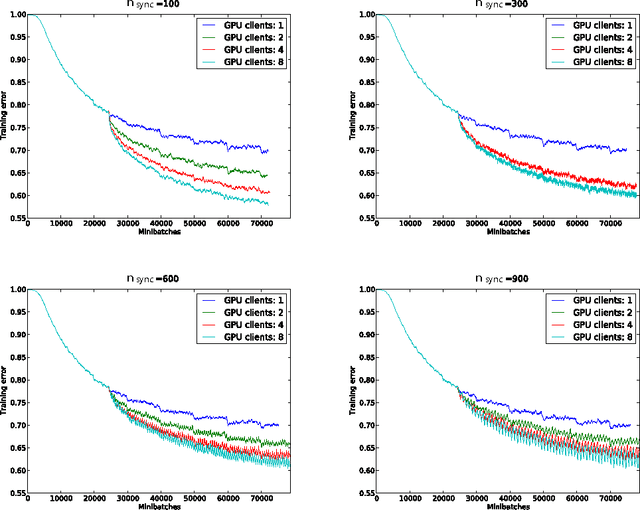
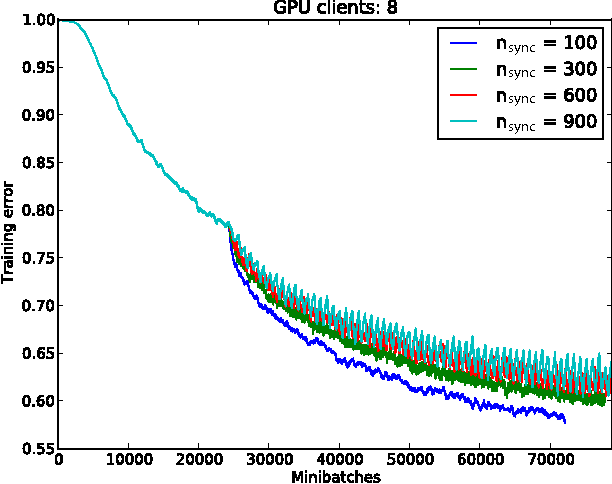
The ability to train large-scale neural networks has resulted in state-of-the-art performance in many areas of computer vision. These results have largely come from computational break throughs of two forms: model parallelism, e.g. GPU accelerated training, which has seen quick adoption in computer vision circles, and data parallelism, e.g. A-SGD, whose large scale has been used mostly in industry. We report early experiments with a system that makes use of both model parallelism and data parallelism, we call GPU A-SGD. We show using GPU A-SGD it is possible to speed up training of large convolutional neural networks useful for computer vision. We believe GPU A-SGD will make it possible to train larger networks on larger training sets in a reasonable amount of time.