 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGemini Robotics: Bringing AI into the Physical World
Mar 25, 2025Recent advancements in large multimodal models have led to the emergence of remarkable generalist capabilities in digital domains, yet their translation to physical agents such as robots remains a significant challenge. This report introduces a new family of AI models purposefully designed for robotics and built upon the foundation of Gemini 2.0. We present Gemini Robotics, an advanced Vision-Language-Action (VLA) generalist model capable of directly controlling robots. Gemini Robotics executes smooth and reactive movements to tackle a wide range of complex manipulation tasks while also being robust to variations in object types and positions, handling unseen environments as well as following diverse, open vocabulary instructions. We show that with additional fine-tuning, Gemini Robotics can be specialized to new capabilities including solving long-horizon, highly dexterous tasks, learning new short-horizon tasks from as few as 100 demonstrations and adapting to completely novel robot embodiments. This is made possible because Gemini Robotics builds on top of the Gemini Robotics-ER model, the second model we introduce in this work. Gemini Robotics-ER (Embodied Reasoning) extends Gemini's multimodal reasoning capabilities into the physical world, with enhanced spatial and temporal understanding. This enables capabilities relevant to robotics including object detection, pointing, trajectory and grasp prediction, as well as multi-view correspondence and 3D bounding box predictions. We show how this novel combination can support a variety of robotics applications. We also discuss and address important safety considerations related to this new class of robotics foundation models. The Gemini Robotics family marks a substantial step towards developing general-purpose robots that realizes AI's potential in the physical world.
GATS: Gather-Attend-Scatter
Jan 16, 2024As the AI community increasingly adopts large-scale models, it is crucial to develop general and flexible tools to integrate them. We introduce Gather-Attend-Scatter (GATS), a novel module that enables seamless combination of pretrained foundation models, both trainable and frozen, into larger multimodal networks. GATS empowers AI systems to process and generate information across multiple modalities at different rates. In contrast to traditional fine-tuning, GATS allows for the original component models to remain frozen, avoiding the risk of them losing important knowledge acquired during the pretraining phase. We demonstrate the utility and versatility of GATS with a few experiments across games, robotics, and multimodal input-output systems.
RoboCat: A Self-Improving Foundation Agent for Robotic Manipulation
Jun 20, 2023



The ability to leverage heterogeneous robotic experience from different robots and tasks to quickly master novel skills and embodiments has the potential to transform robot learning. Inspired by recent advances in foundation models for vision and language, we propose a foundation agent for robotic manipulation. This agent, named RoboCat, is a visual goal-conditioned decision transformer capable of consuming multi-embodiment action-labelled visual experience. This data spans a large repertoire of motor control skills from simulated and real robotic arms with varying sets of observations and actions. With RoboCat, we demonstrate the ability to generalise to new tasks and robots, both zero-shot as well as through adaptation using only 100--1000 examples for the target task. We also show how a trained model itself can be used to generate data for subsequent training iterations, thus providing a basic building block for an autonomous improvement loop. We investigate the agent's capabilities, with large-scale evaluations both in simulation and on three different real robot embodiments. We find that as we grow and diversify its training data, RoboCat not only shows signs of cross-task transfer, but also becomes more efficient at adapting to new tasks.
$\pi2\text{vec}$: Policy Representations with Successor Features
Jun 16, 2023



This paper describes $\pi2\text{vec}$, a method for representing behaviors of black box policies as feature vectors. The policy representations capture how the statistics of foundation model features change in response to the policy behavior in a task agnostic way, and can be trained from offline data, allowing them to be used in offline policy selection. This work provides a key piece of a recipe for fusing together three modern lines of research: Offline policy evaluation as a counterpart to offline RL, foundation models as generic and powerful state representations, and efficient policy selection in resource constrained environments.
Lossless Adaptation of Pretrained Vision Models For Robotic Manipulation
Apr 13, 2023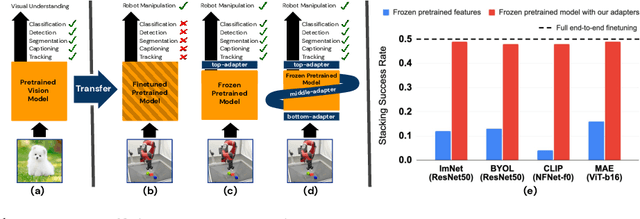
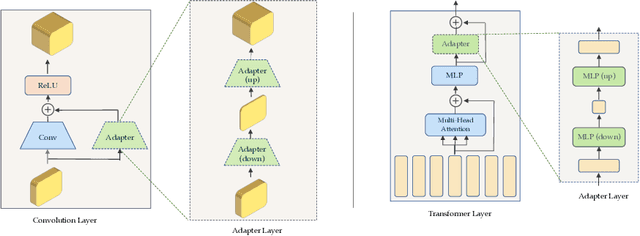

Recent works have shown that large models pretrained on common visual learning tasks can provide useful representations for a wide range of specialized perception problems, as well as a variety of robotic manipulation tasks. While prior work on robotic manipulation has predominantly used frozen pretrained features, we demonstrate that in robotics this approach can fail to reach optimal performance, and that fine-tuning of the full model can lead to significantly better results. Unfortunately, fine-tuning disrupts the pretrained visual representation, and causes representational drift towards the fine-tuned task thus leading to a loss of the versatility of the original model. We introduce "lossless adaptation" to address this shortcoming of classical fine-tuning. We demonstrate that appropriate placement of our parameter efficient adapters can significantly reduce the performance gap between frozen pretrained representations and full end-to-end fine-tuning without changes to the original representation and thus preserving original capabilities of the pretrained model. We perform a comprehensive investigation across three major model architectures (ViTs, NFNets, and ResNets), supervised (ImageNet-1K classification) and self-supervised pretrained weights (CLIP, BYOL, Visual MAE) in 3 task domains and 35 individual tasks, and demonstrate that our claims are strongly validated in various settings.
SkillS: Adaptive Skill Sequencing for Efficient Temporally-Extended Exploration
Dec 03, 2022


The ability to effectively reuse prior knowledge is a key requirement when building general and flexible Reinforcement Learning (RL) agents. Skill reuse is one of the most common approaches, but current methods have considerable limitations.For example, fine-tuning an existing policy frequently fails, as the policy can degrade rapidly early in training. In a similar vein, distillation of expert behavior can lead to poor results when given sub-optimal experts. We compare several common approaches for skill transfer on multiple domains including changes in task and system dynamics. We identify how existing methods can fail and introduce an alternative approach to mitigate these problems. Our approach learns to sequence existing temporally-extended skills for exploration but learns the final policy directly from the raw experience. This conceptual split enables rapid adaptation and thus efficient data collection but without constraining the final solution.It significantly outperforms many classical methods across a suite of evaluation tasks and we use a broad set of ablations to highlight the importance of differentc omponents of our method.
Beyond Pick-and-Place: Tackling Robotic Stacking of Diverse Shapes
Nov 03, 2021
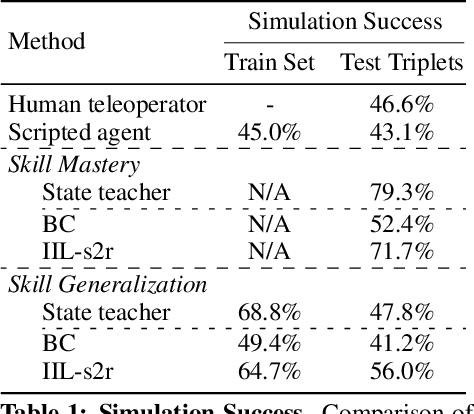
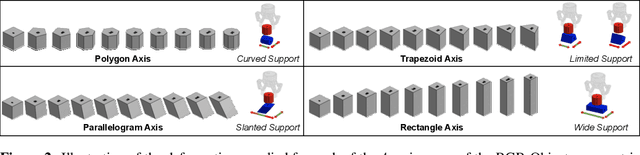
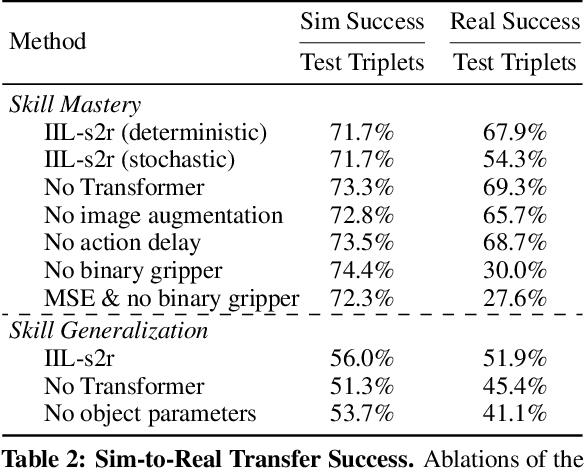
We study the problem of robotic stacking with objects of complex geometry. We propose a challenging and diverse set of such objects that was carefully designed to require strategies beyond a simple "pick-and-place" solution. Our method is a reinforcement learning (RL) approach combined with vision-based interactive policy distillation and simulation-to-reality transfer. Our learned policies can efficiently handle multiple object combinations in the real world and exhibit a large variety of stacking skills. In a large experimental study, we investigate what choices matter for learning such general vision-based agents in simulation, and what affects optimal transfer to the real robot. We then leverage data collected by such policies and improve upon them with offline RL. A video and a blog post of our work are provided as supplementary material.
In Situ Translational Hand-Eye Calibration of Laser Profile Sensors using Arbitrary Objects
Mar 22, 2021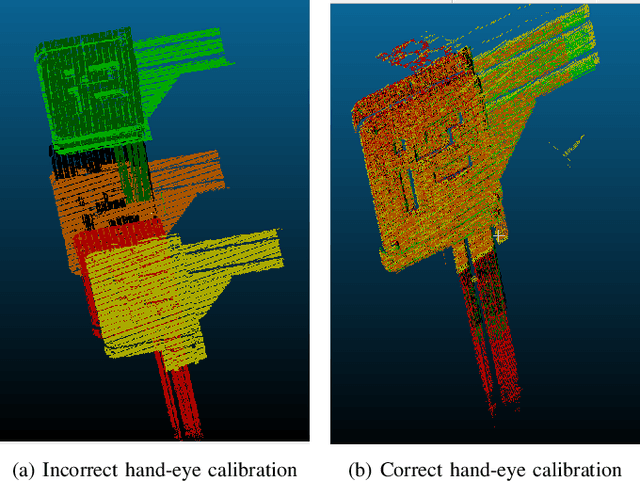
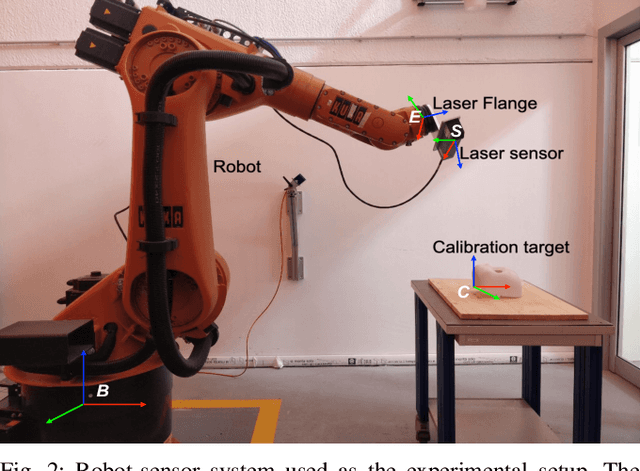


Hand-eye calibration of laser profile sensors is the process of extracting the homogeneous transformation between the laser profile sensor frame and the end-effector frame of a robot in order to express the data extracted by the sensor in the robot's global coordinate system. For laser profile scanners this is a challenging procedure, as they provide data only in two dimensions and state-of-the-art calibration procedures require the use of specialised calibration targets. This paper presents a novel method to extract the translation-part of the hand-eye calibration matrix with rotation-part known a priori in a target-agnostic way. Our methodology is applicable to any 2D image or 3D object as a calibration target and can also be performed in situ in the final application. The method is experimentally validated on a real robot-sensor setup with 2D and 3D targets.
Markerless visual servoing on unknown objects for humanoid robot platforms
Oct 12, 2017
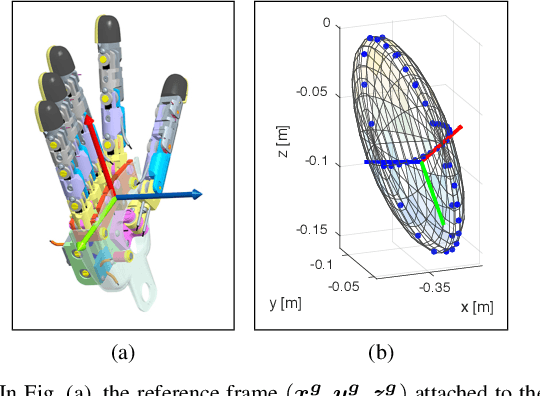
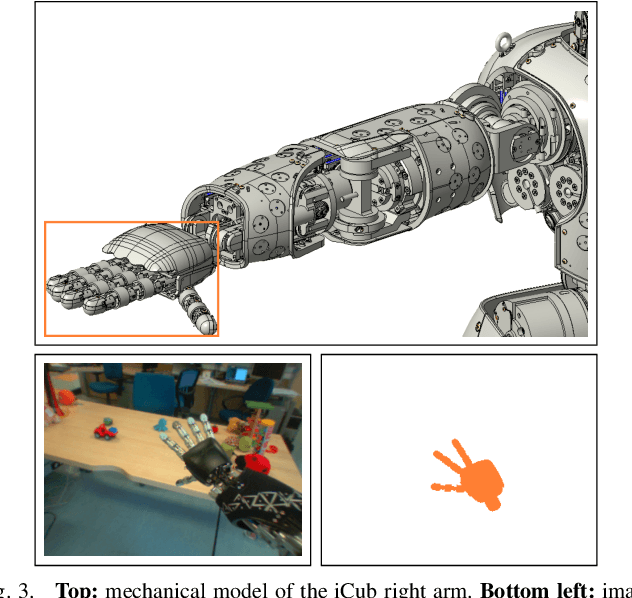
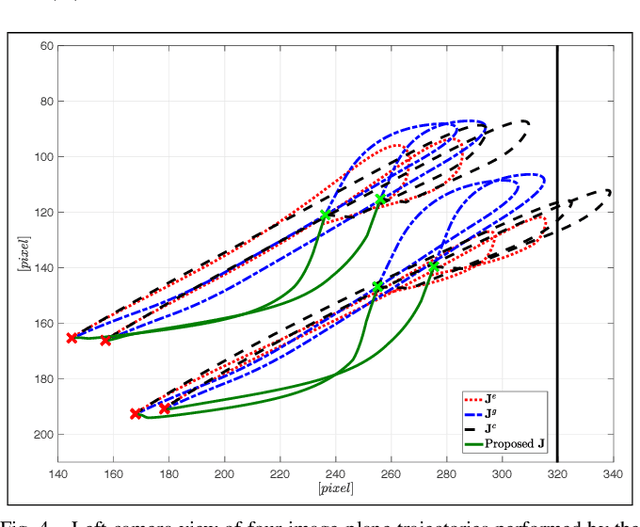
To precisely reach for an object with a humanoid robot, it is of central importance to have good knowledge of both end-effector, object pose and shape. In this work we propose a framework for markerless visual servoing on unknown objects, which is divided in four main parts: I) a least-squares minimization problem is formulated to find the volume of the object graspable by the robot's hand using its stereo vision; II) a recursive Bayesian filtering technique, based on Sequential Monte Carlo (SMC) filtering, estimates the 6D pose (position and orientation) of the robot's end-effector without the use of markers; III) a nonlinear constrained optimization problem is formulated to compute the desired graspable pose about the object; IV) an image-based visual servo control commands the robot's end-effector toward the desired pose. We demonstrate effectiveness and robustness of our approach with extensive experiments on the iCub humanoid robot platform, achieving real-time computation, smooth trajectories and sub-pixel precisions.
Visual end-effector tracking using a 3D model-aided particle filter for humanoid robot platforms
Aug 04, 2017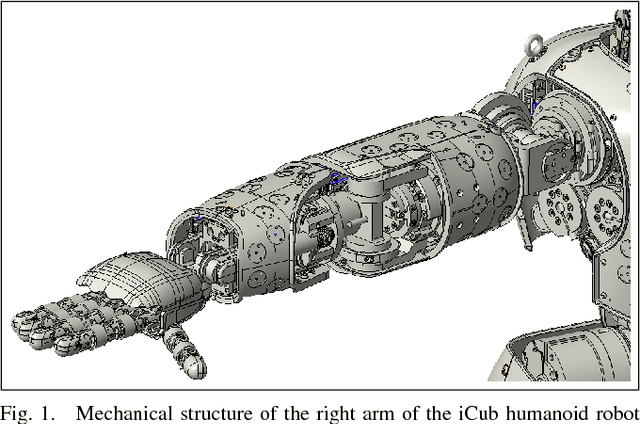


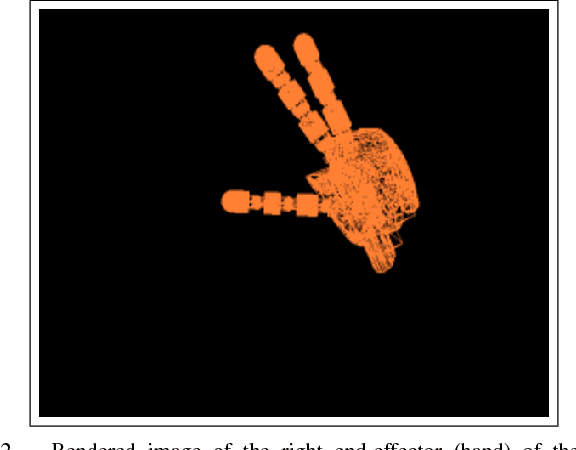
This paper addresses recursive markerless estimation of a robot's end-effector using visual observations from its cameras. The problem is formulated into the Bayesian framework and addressed using Sequential Monte Carlo (SMC) filtering. We use a 3D rendering engine and Computer Aided Design (CAD) schematics of the robot to virtually create images from the robot's camera viewpoints. These images are then used to extract information and estimate the pose of the end-effector. To this aim, we developed a particle filter for estimating the position and orientation of the robot's end-effector using the Histogram of Oriented Gradient (HOG) descriptors to capture robust characteristic features of shapes in both cameras and rendered images. We implemented the algorithm on the iCub humanoid robot and employed it in a closed-loop reaching scenario. We demonstrate that the tracking is robust to clutter, allows compensating for errors in the robot kinematics and servoing the arm in closed loop using vision.