 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArtReg: Visuo-Tactile based Pose Tracking and Manipulation of Unseen Articulated Objects
Nov 09, 2025



Robots operating in real-world environments frequently encounter unknown objects with complex structures and articulated components, such as doors, drawers, cabinets, and tools. The ability to perceive, track, and manipulate these objects without prior knowledge of their geometry or kinematic properties remains a fundamental challenge in robotics. In this work, we present a novel method for visuo-tactile-based tracking of unseen objects (single, multiple, or articulated) during robotic interaction without assuming any prior knowledge regarding object shape or dynamics. Our novel pose tracking approach termed ArtReg (stands for Articulated Registration) integrates visuo-tactile point clouds in an unscented Kalman Filter formulation in the SE(3) Lie Group for point cloud registration. ArtReg is used to detect possible articulated joints in objects using purposeful manipulation maneuvers such as pushing or hold-pulling with a two-robot team. Furthermore, we leverage ArtReg to develop a closed-loop controller for goal-driven manipulation of articulated objects to move the object into the desired pose configuration. We have extensively evaluated our approach on various types of unknown objects through real robot experiments. We also demonstrate the robustness of our method by evaluating objects with varying center of mass, low-light conditions, and with challenging visual backgrounds. Furthermore, we benchmarked our approach on a standard dataset of articulated objects and demonstrated improved performance in terms of pose accuracy compared to state-of-the-art methods. Our experiments indicate that robust and accurate pose tracking leveraging visuo-tactile information enables robots to perceive and interact with unseen complex articulated objects (with revolute or prismatic joints).
Touch if it's transparent! ACTOR: Active Tactile-based Category-Level Transparent Object Reconstruction
Jul 30, 2023



Accurate shape reconstruction of transparent objects is a challenging task due to their non-Lambertian surfaces and yet necessary for robots for accurate pose perception and safe manipulation. As vision-based sensing can produce erroneous measurements for transparent objects, the tactile modality is not sensitive to object transparency and can be used for reconstructing the object's shape. We propose ACTOR, a novel framework for ACtive tactile-based category-level Transparent Object Reconstruction. ACTOR leverages large datasets of synthetic object with our proposed self-supervised learning approach for object shape reconstruction as the collection of real-world tactile data is prohibitively expensive. ACTOR can be used during inference with tactile data from category-level unknown transparent objects for reconstruction. Furthermore, we propose an active-tactile object exploration strategy as probing every part of the object surface can be sample inefficient. We also demonstrate tactile-based category-level object pose estimation task using ACTOR. We perform an extensive evaluation of our proposed methodology with real-world robotic experiments with comprehensive comparison studies with state-of-the-art approaches. Our proposed method outperforms these approaches in terms of tactile-based object reconstruction and object pose estimation.
GMCR: Graph-based Maximum Consensus Estimation for Point Cloud Registration
Mar 07, 2023



Point cloud registration is a fundamental and challenging problem for autonomous robots interacting in unstructured environments for applications such as object pose estimation, simultaneous localization and mapping, robot-sensor calibration, and so on. In global correspondence-based point cloud registration, data association is a highly brittle task and commonly produces high amounts of outliers. Failure to reject outliers can lead to errors propagating to downstream perception tasks. Maximum Consensus (MC) is a widely used technique for robust estimation, which is however known to be NP-hard. Exact methods struggle to scale to realistic problem instances, whereas high outlier rates are challenging for approximate methods. To this end, we propose Graph-based Maximum Consensus Registration (GMCR), which is highly robust to outliers and scales to realistic problem instances. We propose novel consensus functions to map the decoupled MC-objective to the graph domain, wherein we find a tight approximation to the maximum consensus set as the maximum clique. The final pose estimate is given in closed-form. We extensively evaluated our proposed GMCR on a synthetic registration benchmark, robotic object localization task, and additionally on a scan matching benchmark. Our proposed method shows high accuracy and time efficiency compared to other state-of-the-art MC methods and compares favorably to other robust registration methods.
An Empirical Evaluation of Various Information Gain Criteria for Active Tactile Action Selection for Pose Estimation
May 10, 2022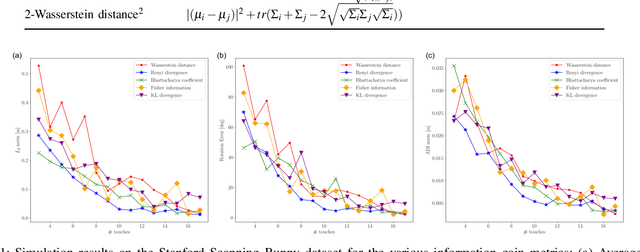
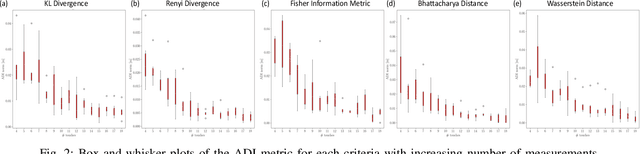
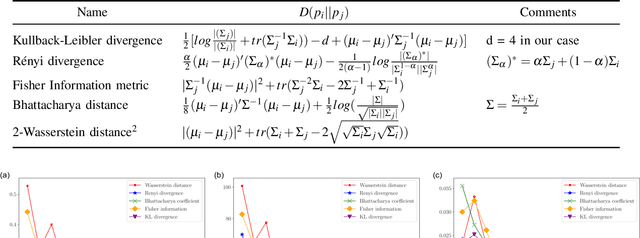
Accurate object pose estimation using multi-modal perception such as visual and tactile sensing have been used for autonomous robotic manipulators in literature. Due to variation in density of visual and tactile data, we previously proposed a novel probabilistic Bayesian filter-based approach termed translation-invariant Quaternion filter (TIQF) for pose estimation. As tactile data collection is time consuming, active tactile data collection is preferred by reasoning over multiple potential actions for maximal expected information gain. In this paper, we empirically evaluate various information gain criteria for action selection in the context of object pose estimation. We demonstrate the adaptability and effectiveness of our proposed TIQF pose estimation approach with various information gain criteria. We find similar performance in terms of pose accuracy with sparse measurements across all the selected criteria.
Towards Robust 3D Object Recognition with Dense-to-Sparse Deep Domain Adaptation
May 07, 2022
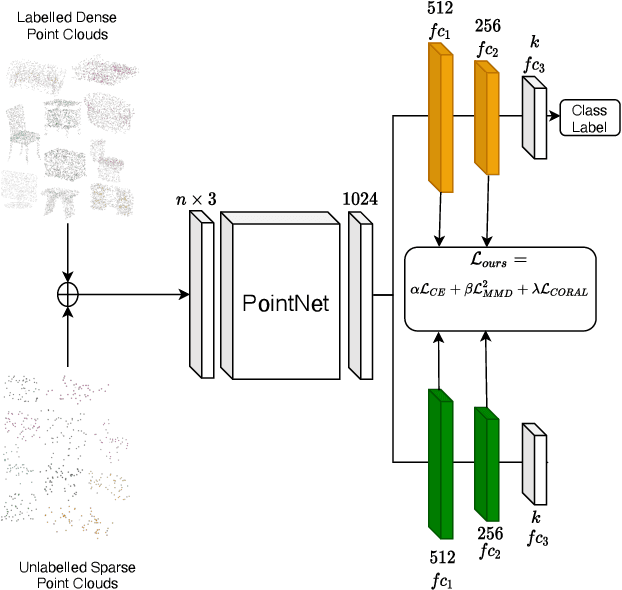
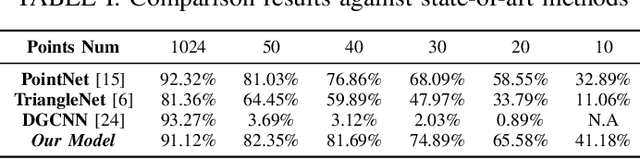
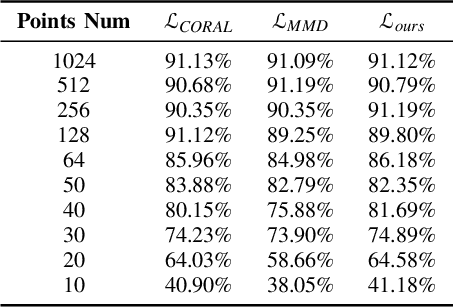
Three-dimensional (3D) object recognition is crucial for intelligent autonomous agents such as autonomous vehicles and robots alike to operate effectively in unstructured environments. Most state-of-art approaches rely on relatively dense point clouds and performance drops significantly for sparse point clouds. Unsupervised domain adaption allows to minimise the discrepancy between dense and sparse point clouds with minimal unlabelled sparse point clouds, thereby saving additional sparse data collection, annotation and retraining costs. In this work, we propose a novel method for point cloud based object recognition with competitive performance with state-of-art methods on dense and sparse point clouds while being trained only with dense point clouds.
Active Visuo-Tactile Interactive Robotic Perception for Accurate Object Pose Estimation in Dense Clutter
Feb 04, 2022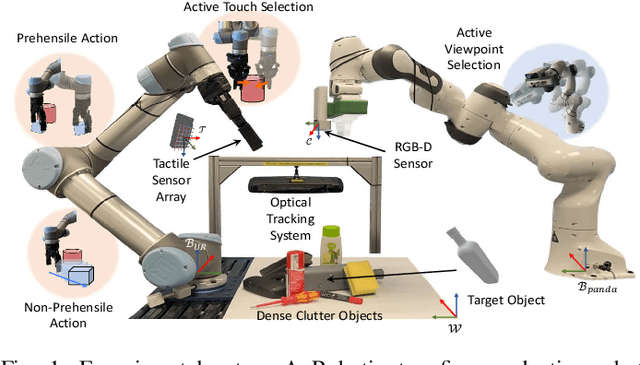
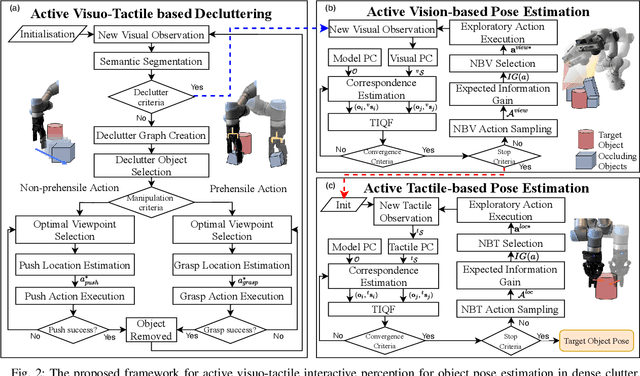
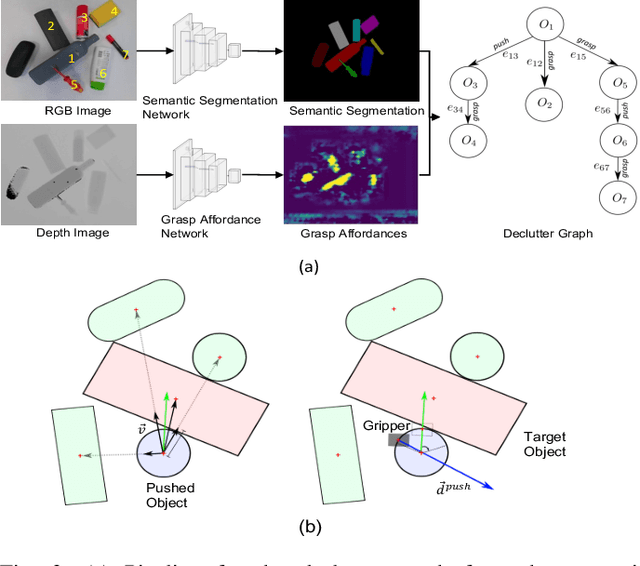
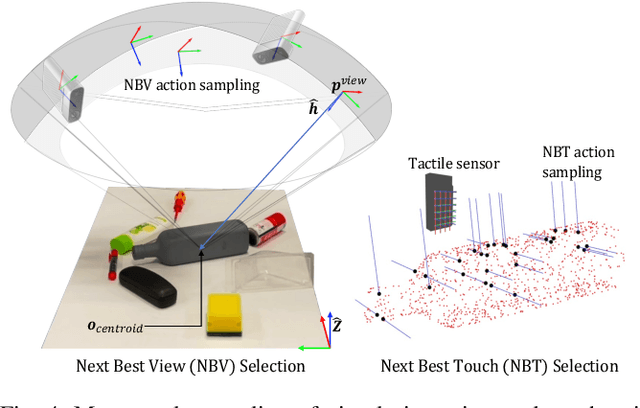
This work presents a novel active visuo-tactile based framework for robotic systems to accurately estimate pose of objects in dense cluttered environments. The scene representation is derived using a novel declutter graph (DG) which describes the relationship among objects in the scene for decluttering by leveraging semantic segmentation and grasp affordances networks. The graph formulation allows robots to efficiently declutter the workspace by autonomously selecting the next best object to remove and the optimal action (prehensile or non-prehensile) to perform. Furthermore, we propose a novel translation-invariant Quaternion filter (TIQF) for active vision and active tactile based pose estimation. Both active visual and active tactile points are selected by maximizing the expected information gain. We evaluate our proposed framework on a system with two robots coordinating on randomized scenes of dense cluttered objects and perform ablation studies with static vision and active vision based estimation prior and post decluttering as baselines. Our proposed active visuo-tactile interactive perception framework shows upto 36% improvement in pose accuracy compared to the active vision baseline.
On the Empirical Evaluation of Information Gain Criteria for Active Action Selection
Sep 28, 2021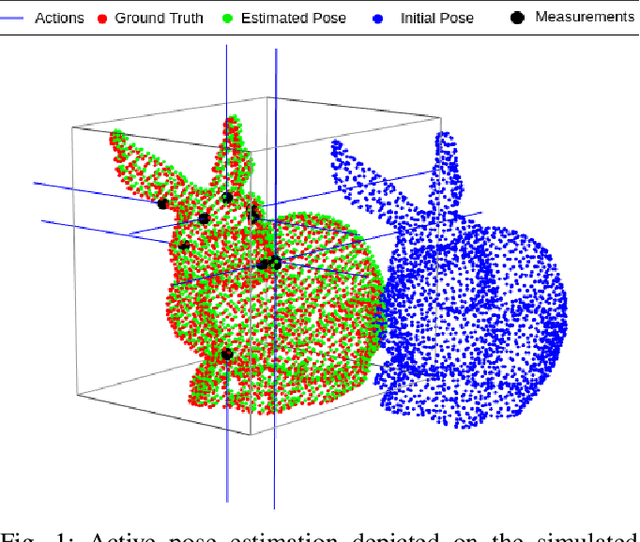
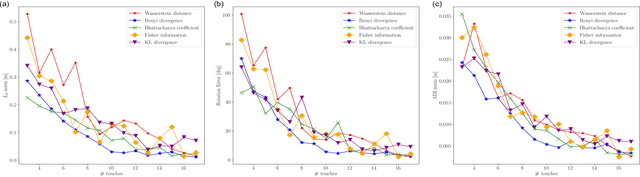


Accurate object pose estimation using multi-modal perception such as visual and tactile sensing have been used for autonomous robotic manipulators in literature. Due to variation in density of visual and tactile data, a novel probabilistic Bayesian filter-based approach termed translation-invariant Quaternion filter (TIQF) is proposed for pose estimation using point cloud registration. Active tactile data collection is preferred by reasoning over multiple potential actions for maximal expected information gain as tactile data collection is time consuming. In this paper, we empirically evaluate various information gain criteria for action selection in the context of object pose estimation. We demonstrate the adaptability and effectiveness of our proposed TIQF pose estimation approach with various information gain criteria. We find similar performance in terms of pose accuracy with sparse measurements ($<15$ points) across all the selected criteria. Furthermore, we explore the use of uncommon information theoretic criteria in the robotics domain for action selection.
Active Visuo-Tactile Point Cloud Registration for Accurate Pose Estimation of Objects in an Unknown Workspace
Aug 09, 2021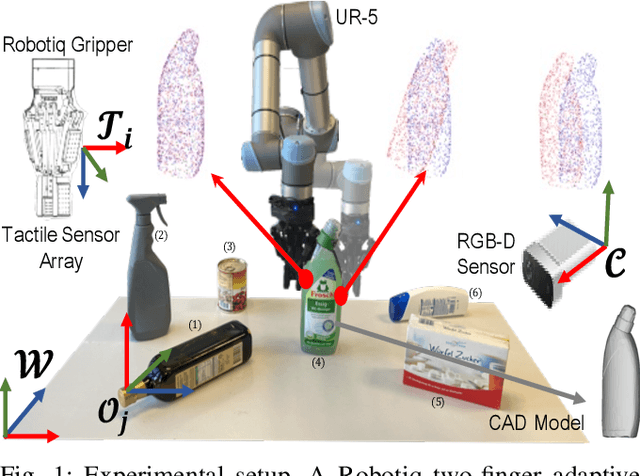
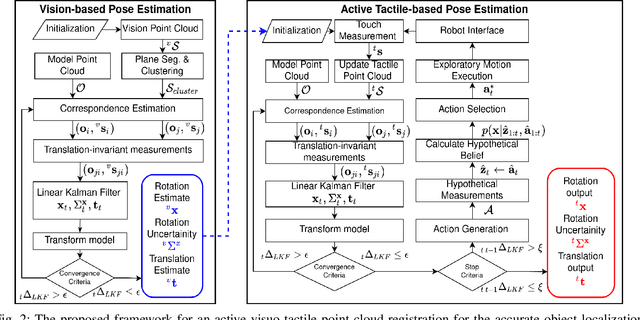
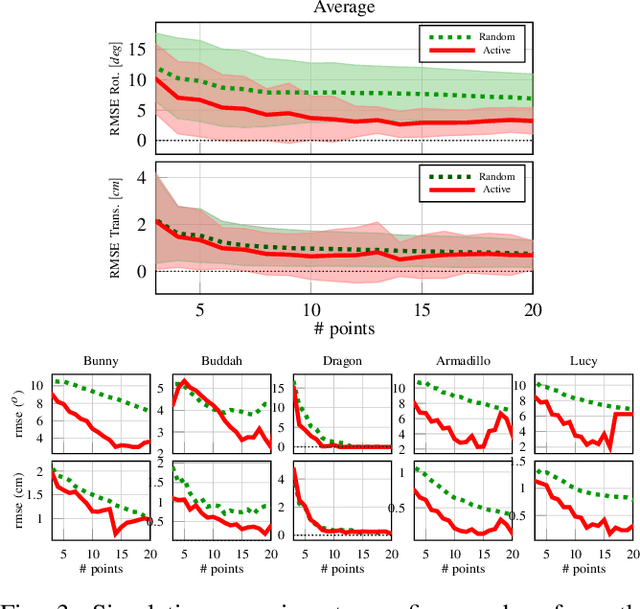
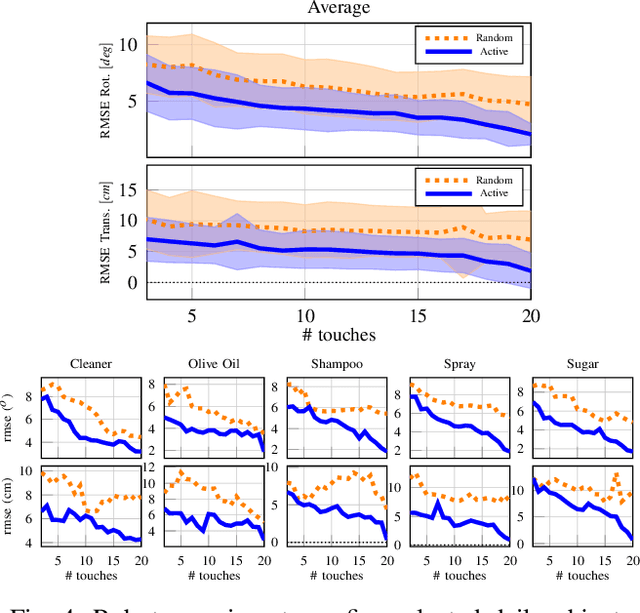
This paper proposes a novel active visuo-tactile based methodology wherein the accurate estimation of the time-invariant SE(3) pose of objects is considered for autonomous robotic manipulators. The robot equipped with tactile sensors on the gripper is guided by a vision estimate to actively explore and localize the objects in the unknown workspace. The robot is capable of reasoning over multiple potential actions, and execute the action to maximize information gain to update the current belief of the object. We formulate the pose estimation process as a linear translation invariant quaternion filter (TIQF) by decoupling the estimation of translation and rotation and formulating the update and measurement model in linear form. We perform pose estimation sequentially on acquired measurements using very sparse point cloud as acquiring each measurement using tactile sensing is time consuming. Furthermore, our proposed method is computationally efficient to perform an exhaustive uncertainty-based active touch selection strategy in real-time without the need for trading information gain with execution time. We evaluated the performance of our approach extensively in simulation and by a robotic system.
In Situ Translational Hand-Eye Calibration of Laser Profile Sensors using Arbitrary Objects
Mar 22, 2021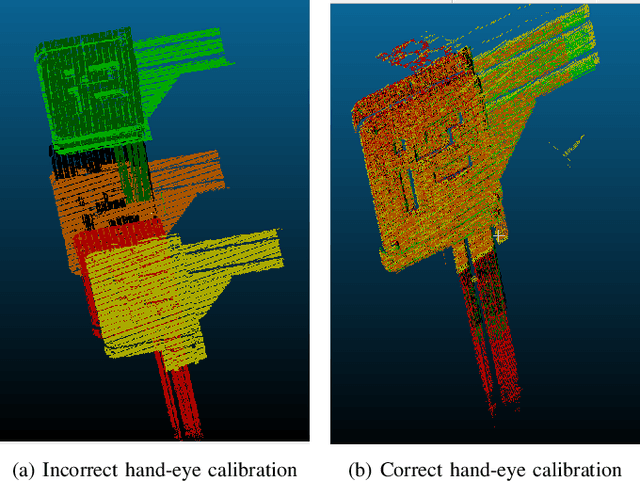
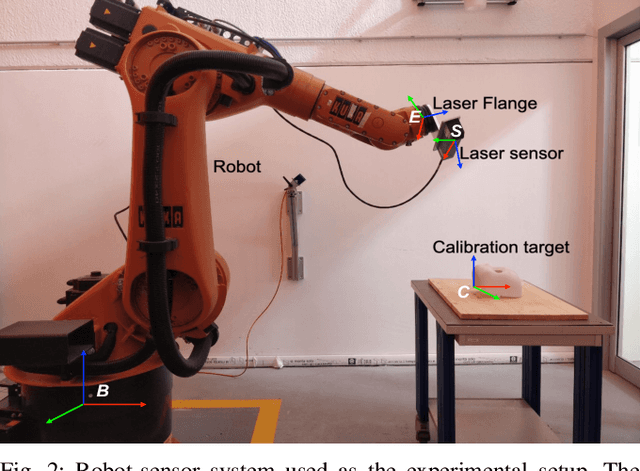


Hand-eye calibration of laser profile sensors is the process of extracting the homogeneous transformation between the laser profile sensor frame and the end-effector frame of a robot in order to express the data extracted by the sensor in the robot's global coordinate system. For laser profile scanners this is a challenging procedure, as they provide data only in two dimensions and state-of-the-art calibration procedures require the use of specialised calibration targets. This paper presents a novel method to extract the translation-part of the hand-eye calibration matrix with rotation-part known a priori in a target-agnostic way. Our methodology is applicable to any 2D image or 3D object as a calibration target and can also be performed in situ in the final application. The method is experimentally validated on a real robot-sensor setup with 2D and 3D targets.
Deployment and Evaluation of a Flexible Human-Robot Collaboration Model Based on AND/OR Graphs in a Manufacturing Environment
Jul 13, 2020

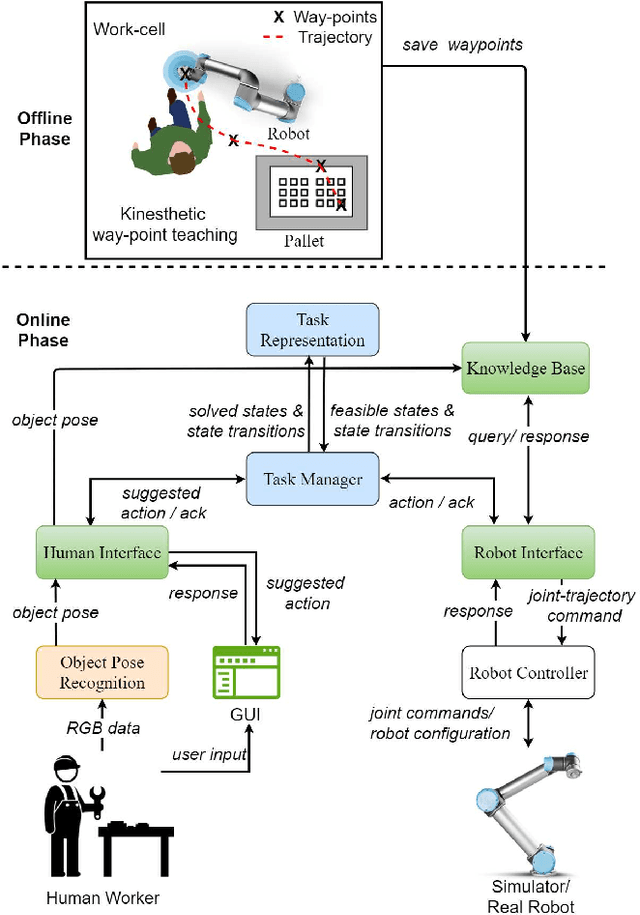

The Industry 4.0 paradigm promises shorter development times, increased ergonomy, higher flexibility, and resource efficiency in manufacturing environments. Collaborative robots are an important tangible technology for implementing such a paradigm. A major bottleneck to effectively deploy collaborative robots to manufacturing industries is developing task planning algorithms that enable them to recognize and naturally adapt to varying and even unpredictable human actions while simultaneously ensuring an overall efficiency in terms of production cycle time. In this context, an architecture encompassing task representation, task planning, sensing, and robot control has been designed, developed and evaluated in a real industrial environment. A pick-and-place palletization task, which requires the collaboration between humans and robots, is investigated. The architecture uses AND/OR graphs for representing and reasoning upon human-robot collaboration models online. Furthermore, objective measures of the overall computational performance and subjective measures of naturalness in human-robot collaboration have been evaluated by performing experiments with production-line operators. The results of this user study demonstrate how human-robot collaboration models like the one we propose can leverage the flexibility and the comfort of operators in the workplace. In this regard, an extensive comparison study among recent models has been carried out.