 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-Time Model Checking for Closed-Loop Robot Reactive Planning
Aug 26, 2025
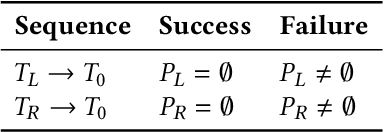


We present a new application of model checking which achieves real-time multi-step planning and obstacle avoidance on a real autonomous robot. We have developed a small, purpose-built model checking algorithm which generates plans in situ based on "core" knowledge and attention as found in biological agents. This is achieved in real-time using no pre-computed data on a low-powered device. Our approach is based on chaining temporary control systems which are spawned to counteract disturbances in the local environment that disrupt an autonomous agent from its preferred action (or resting state). A novel discretization of 2D LiDAR data sensitive to bounded variations in the local environment is used. Multi-step planning using model checking by forward depth-first search is applied to cul-de-sac and playground scenarios. Both empirical results and informal proofs of two fundamental properties of our approach demonstrate that model checking can be used to create efficient multi-step plans for local obstacle avoidance, improving on the performance of a reactive agent which can only plan one step. Our approach is an instructional case study for the development of safe, reliable and explainable planning in the context of autonomous vehicles.
Closed-loop multi-step planning with innate physics knowledge
Nov 18, 2024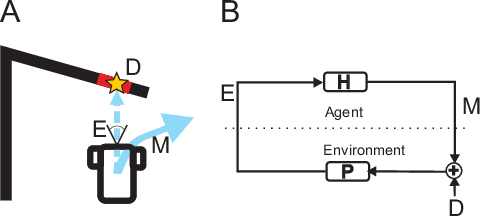
We present a hierarchical framework to solve robot planning as an input control problem. At the lowest level are temporary closed control loops, ("tasks"), each representing a behaviour, contingent on a specific sensory input and therefore temporary. At the highest level, a supervising "Configurator" directs task creation and termination. Here resides "core" knowledge as a physics engine, where sequences of tasks can be simulated. The Configurator encodes and interprets simulation results,based on which it can choose a sequence of tasks as a plan. We implement this framework on a real robot and test it in an overtaking scenario as proof-of-concept.
An Empirical Investigation Into the Time and Frequency Response Characteristics of Hopf Resonators
Jul 18, 2024



We present an empirical investigation of software developed by the Science and Music Research Group at the University of Glasgow. Initially created for musicological applications, it is equally applicable in any area where precise time and frequency information is required from a signal, without encountering the problems associated with the uncertainty principle. By constructing a bank of non-linear tuned resonators (`detectors'), each of which operates at a Hopf bifurcation, it is possible to detect frequencies within half a period of oscillation, even in the presence of wideband noise. The time and frequency response characteristics of these detectors will be examined here.
Homeostatic motion planning with innate physics knowledge
Feb 23, 2024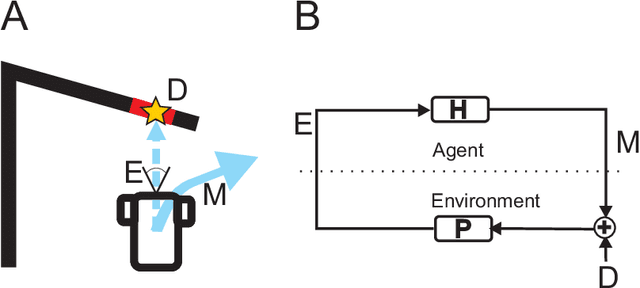
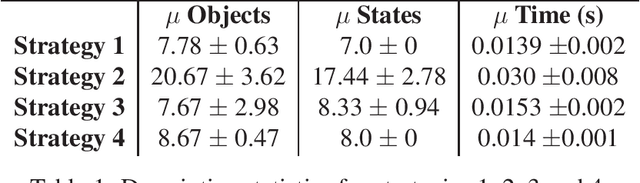
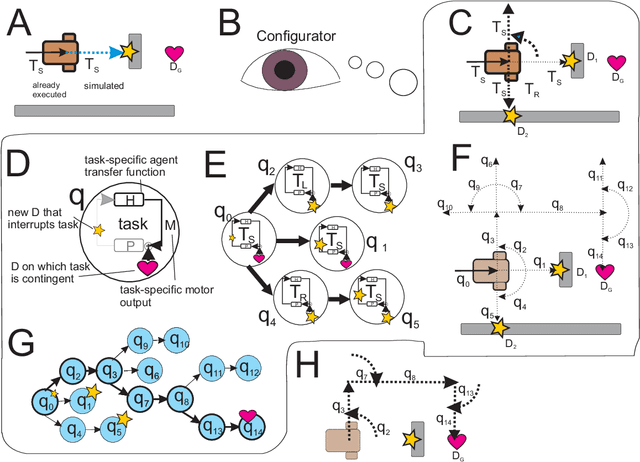
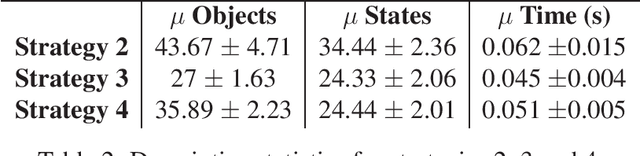
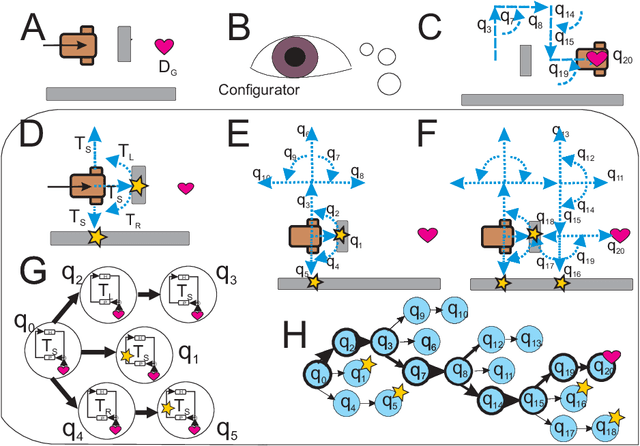
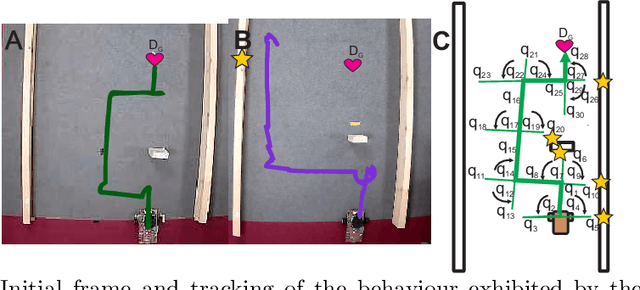
Living organisms interact with their surroundings in a closed-loop fashion, where sensory inputs dictate the initiation and termination of behaviours. Even simple animals are able to develop and execute complex plans, which has not yet been replicated in robotics using pure closed-loop input control. We propose a solution to this problem by defining a set of discrete and temporary closed-loop controllers, called "tasks", each representing a closed-loop behaviour. We further introduce a supervisory module which has an innate understanding of physics and causality, through which it can simulate the execution of task sequences over time and store the results in a model of the environment. On the basis of this model, plans can be made by chaining temporary closed-loop controllers. The proposed framework was implemented for a real robot and tested in two scenarios as proof of concept.
Model Checking for Closed-Loop Robot Reactive Planning
Nov 16, 2023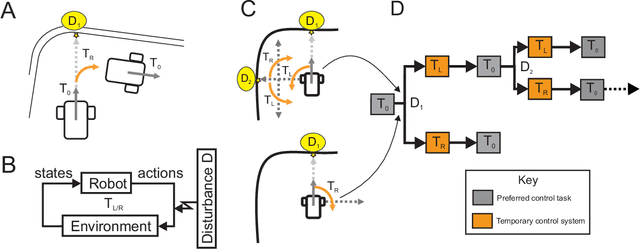
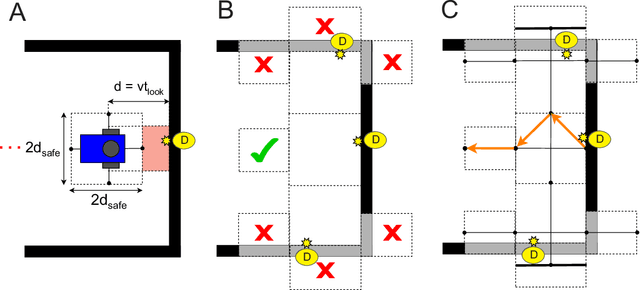
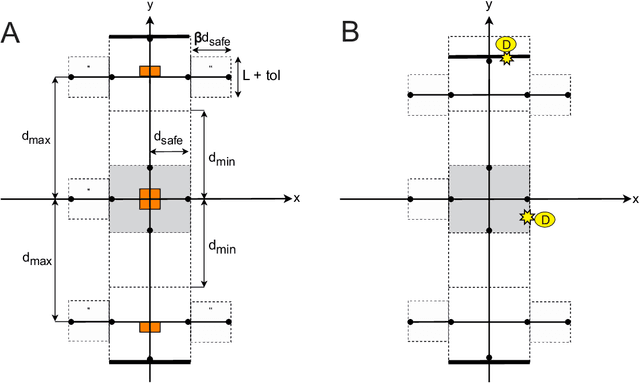
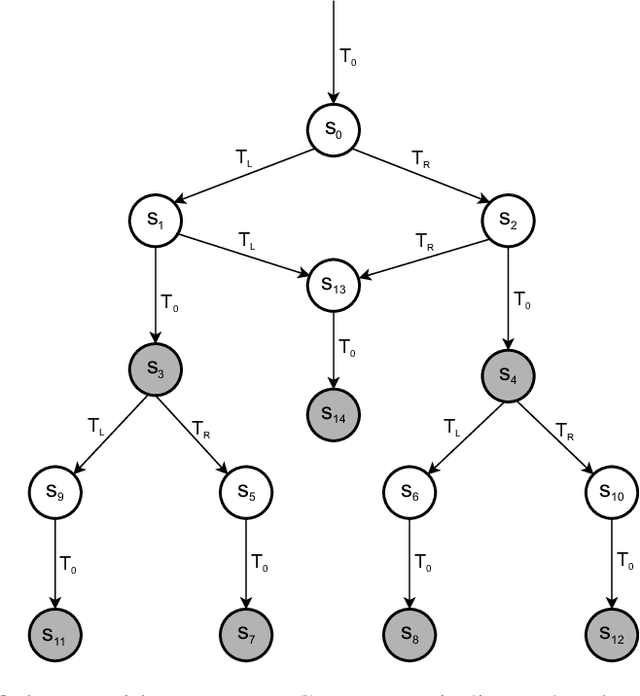
In this paper, we show how model checking can be used to create multi-step plans for a differential drive wheeled robot so that it can avoid immediate danger. Using a small, purpose built model checking algorithm in situ we generate plans in real-time in a way that reflects the egocentric reactive response of simple biological agents. Our approach is based on chaining temporary control systems which are spawned to eliminate disturbances in the local environment that disrupt an autonomous agent from its preferred action (or resting state). The method involves a novel discretization of 2D LiDAR data which is sensitive to bounded stochastic variations in the immediate environment. We operationalise multi-step planning using invariant checking by forward depth-first search, using a cul-de-sac scenario as a first test case. Our results demonstrate that model checking can be used to plan efficient trajectories for local obstacle avoidance, improving on the performance of a reactive agent which can only plan one step. We achieve this in near real-time using no pre-computed data. While our method has limitations, we believe our approach shows promise as an avenue for the development of safe, reliable and transparent trajectory planning in the context of autonomous vehicles.
* In Proceedings FMAS 2023, arXiv:2311.08987
Prime and Modulate Learning: Generation of forward models with signed back-propagation and environmental cues
Sep 07, 2023Deep neural networks employing error back-propagation for learning can suffer from exploding and vanishing gradient problems. Numerous solutions have been proposed such as normalisation techniques or limiting activation functions to linear rectifying units. In this work we follow a different approach which is particularly applicable to closed-loop learning of forward models where back-propagation makes exclusive use of the sign of the error signal to prime the learning, whilst a global relevance signal modulates the rate of learning. This is inspired by the interaction between local plasticity and a global neuromodulation. For example, whilst driving on an empty road, one can allow for slow step-wise optimisation of actions, whereas, at a busy junction, an error must be corrected at once. Hence, the error is the priming signal and the intensity of the experience is a modulating factor in the weight change. The advantages of this Prime and Modulate paradigm is twofold: it is free from normalisation and it makes use of relevant cues from the environment to enrich the learning. We present a mathematical derivation of the learning rule in z-space and demonstrate the real-time performance with a robotic platform. The results show a significant improvement in the speed of convergence compared to that of the conventional back-propagation.
Touch if it's transparent! ACTOR: Active Tactile-based Category-Level Transparent Object Reconstruction
Jul 30, 2023



Accurate shape reconstruction of transparent objects is a challenging task due to their non-Lambertian surfaces and yet necessary for robots for accurate pose perception and safe manipulation. As vision-based sensing can produce erroneous measurements for transparent objects, the tactile modality is not sensitive to object transparency and can be used for reconstructing the object's shape. We propose ACTOR, a novel framework for ACtive tactile-based category-level Transparent Object Reconstruction. ACTOR leverages large datasets of synthetic object with our proposed self-supervised learning approach for object shape reconstruction as the collection of real-world tactile data is prohibitively expensive. ACTOR can be used during inference with tactile data from category-level unknown transparent objects for reconstruction. Furthermore, we propose an active-tactile object exploration strategy as probing every part of the object surface can be sample inefficient. We also demonstrate tactile-based category-level object pose estimation task using ACTOR. We perform an extensive evaluation of our proposed methodology with real-world robotic experiments with comprehensive comparison studies with state-of-the-art approaches. Our proposed method outperforms these approaches in terms of tactile-based object reconstruction and object pose estimation.
BCI-Walls: A robust methodology to predict success or failure in brain computer interfaces
Oct 30, 2022Brain computer interfaces (BCI) require realtime detection of conscious EEG changes so that a user can for example control a video game. However scalp recordings are contaminated with noise, in particular muscle activity and eye movement artefacts. This noise is non-stationary because subjects will voluntarily or involuntarily use their facial muscles or move their eyes. If such non-stationary noise is powerful enough a detector will no longer be able to distinguish between signal and noise which is called SNR-wall. As a relevant and instructional example for BCI we have recorded scalp signals from the central electrode Cz during 8 different activities ranging from relaxed, over playing a video game to reading out loud. We then filtered the raw signals using four different postprocessing scenarios which are popular in the BCI-literature. The results show that filtering with a 1st order highpass makes it impossible to detect conscious EEG changes during any of the physical activities. A wideband bandpass filter between 8-18 Hz allows the detection of conscious EEG changes while playing a phone app, Sudoku, word search and colouring. Reducing the bandwidth during postprocessing to 8-12 Hz allows additionally conscious detection of EEG during reading out loud. The SNR-wall applied to BCI gives now a hard and measurable criterion to determine if a BCI experiment can detect conscious EEG changes or not. It enables one to flag up experimental setups and postprocessing scenarios where misinterpreting of scalp recordings is highly likely, in particular misinterpreting non-stationary muscle activity as conscious EEG changes.
Simulation and Model Checking for Close to Realtime Overtaking Planning
Oct 25, 2021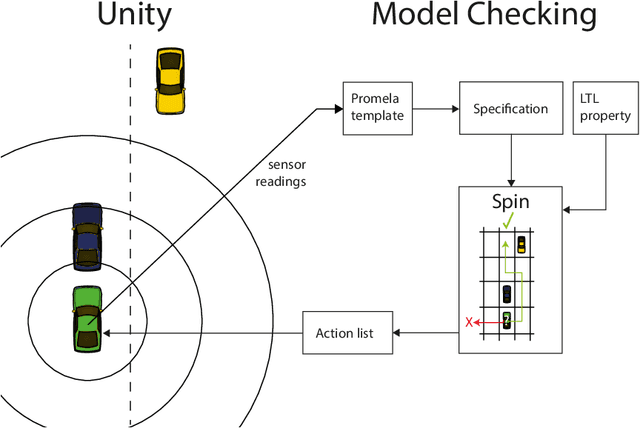
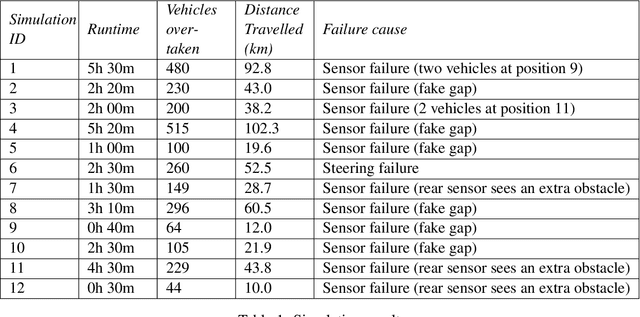
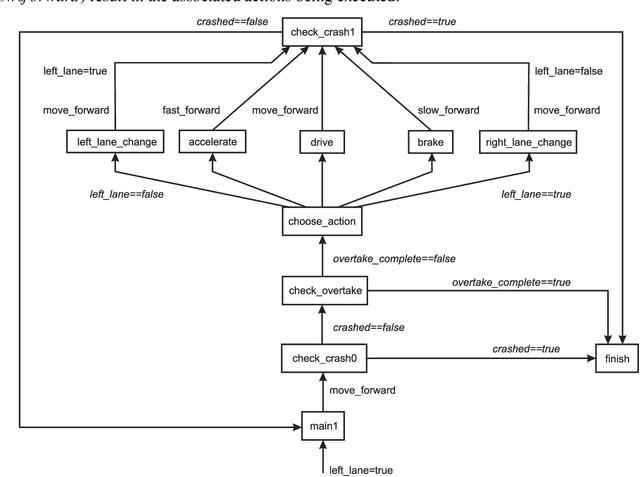
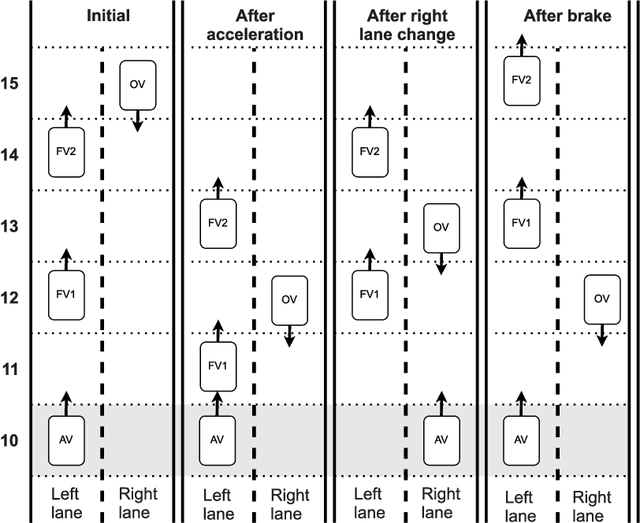
Fast and reliable trajectory planning is a key requirement of autonomous vehicles. In this paper we introduce a novel technique for planning the route of an autonomous vehicle on a straight rural road using the Spin model checker. We show how we can combine Spins ability to identify paths violating temporal properties with sensor information from a 3D Unity simulation of an autonomous vehicle, to plan and perform consecutive overtaking manoeuvres on a traffic heavy road. This involves discretising the sensory information and combining multiple sequential Spin models with a Linear Time Temporal Logic specification to generate an error path. This path provides the autonomous vehicle with an action plan. The entire process takes place in close to realtime using no precomputed data and the action plan is specifically tailored for individual scenarios. Our experiments demonstrate that the simulated autonomous vehicle implementing our approach can drive on average at least 40km and overtake 214 vehicles before experiencing a collision, which is usually caused by inaccuracies in the sensory system. While the proposed system has some drawbacks, we believe that our novel approach demonstrates a potentially powerful future tool for efficient trajectory planning for autonomous vehicles.
* In Proceedings FMAS 2021, arXiv:2110.11527
Sign and Relevance learning
Oct 14, 2021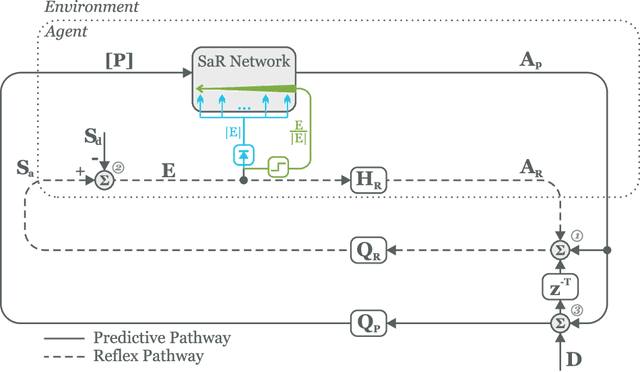
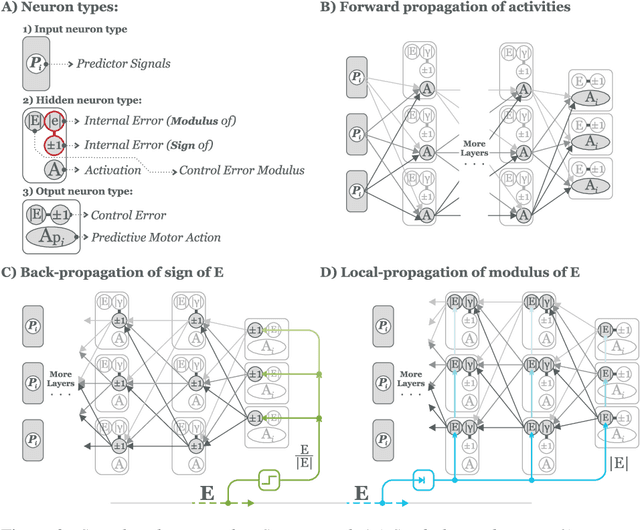
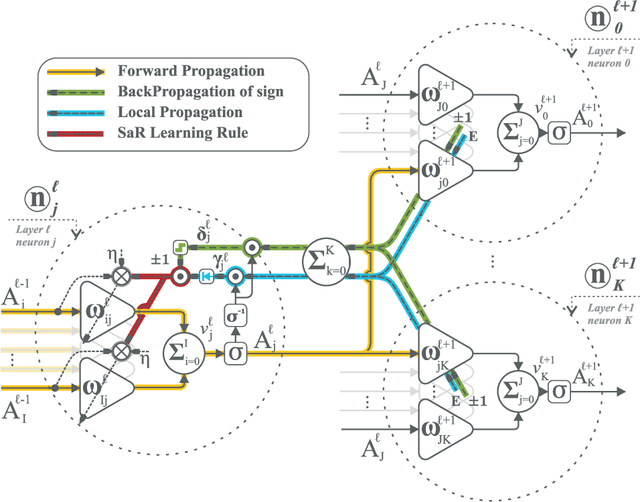
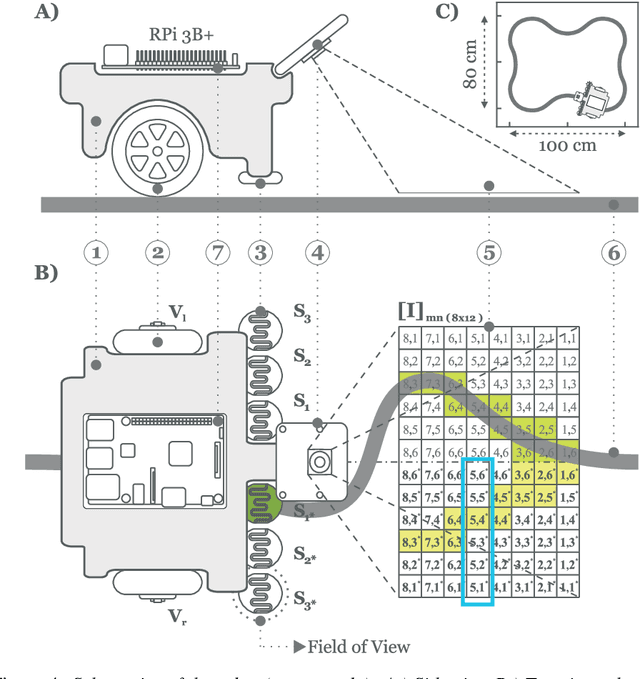
Standard models of biologically realistic, or inspired, reinforcement learning employ a global error signal which implies shallow networks. However, deep networks could offer a drastically superior performance by feeding the error signal backwards through such a network which in turn is not biologically realistic as it requires symmetric weights between top-down and bottom-up pathways. Instead, we present a network combining local learning with global modulation where neuromodulation controls the amount of plasticity change in the whole network, while only the sign of the error is backpropagated through the network. The neuromodulation can be understood as a rectified error, or relevance, signal while the bottom-up sign of the error signal decides between long-term potentiation and long-term depression. We demonstrate the performance of this paradigm with a real robotic task.