 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrime and Modulate Learning: Generation of forward models with signed back-propagation and environmental cues
Sep 07, 2023Deep neural networks employing error back-propagation for learning can suffer from exploding and vanishing gradient problems. Numerous solutions have been proposed such as normalisation techniques or limiting activation functions to linear rectifying units. In this work we follow a different approach which is particularly applicable to closed-loop learning of forward models where back-propagation makes exclusive use of the sign of the error signal to prime the learning, whilst a global relevance signal modulates the rate of learning. This is inspired by the interaction between local plasticity and a global neuromodulation. For example, whilst driving on an empty road, one can allow for slow step-wise optimisation of actions, whereas, at a busy junction, an error must be corrected at once. Hence, the error is the priming signal and the intensity of the experience is a modulating factor in the weight change. The advantages of this Prime and Modulate paradigm is twofold: it is free from normalisation and it makes use of relevant cues from the environment to enrich the learning. We present a mathematical derivation of the learning rule in z-space and demonstrate the real-time performance with a robotic platform. The results show a significant improvement in the speed of convergence compared to that of the conventional back-propagation.
Sign and Relevance learning
Oct 14, 2021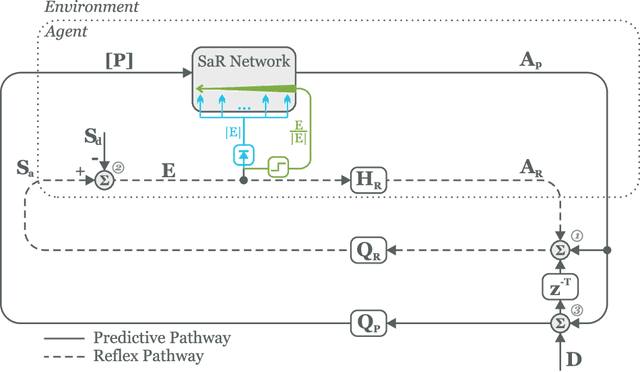
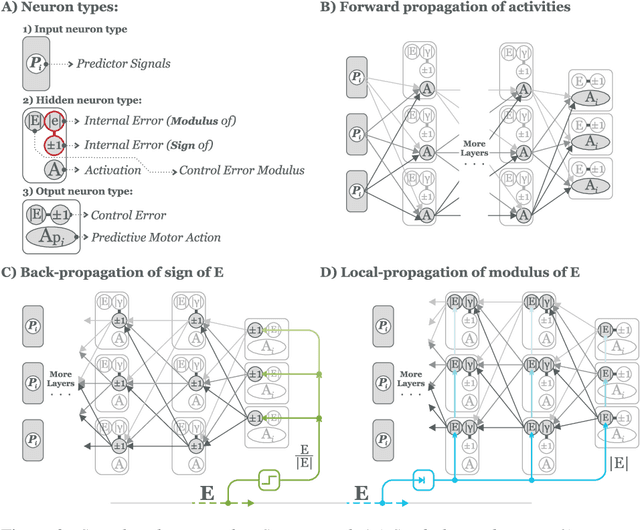
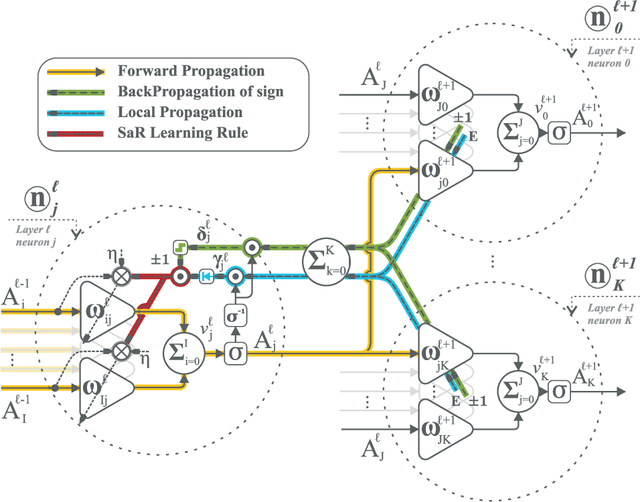
Standard models of biologically realistic, or inspired, reinforcement learning employ a global error signal which implies shallow networks. However, deep networks could offer a drastically superior performance by feeding the error signal backwards through such a network which in turn is not biologically realistic as it requires symmetric weights between top-down and bottom-up pathways. Instead, we present a network combining local learning with global modulation where neuromodulation controls the amount of plasticity change in the whole network, while only the sign of the error is backpropagated through the network. The neuromodulation can be understood as a rectified error, or relevance, signal while the bottom-up sign of the error signal decides between long-term potentiation and long-term depression. We demonstrate the performance of this paradigm with a real robotic task.
Closed-loop deep learning: generating forward models with back-propagation
Jan 13, 2020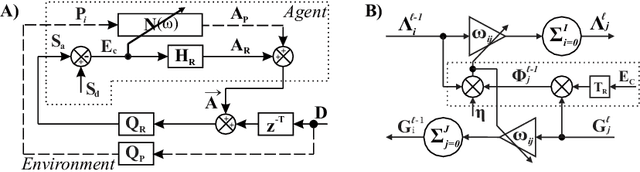
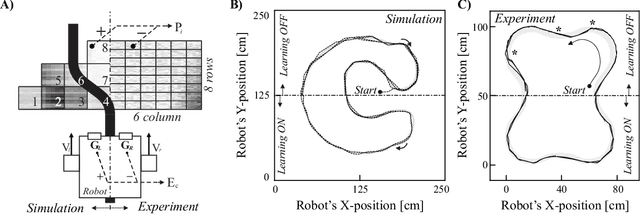
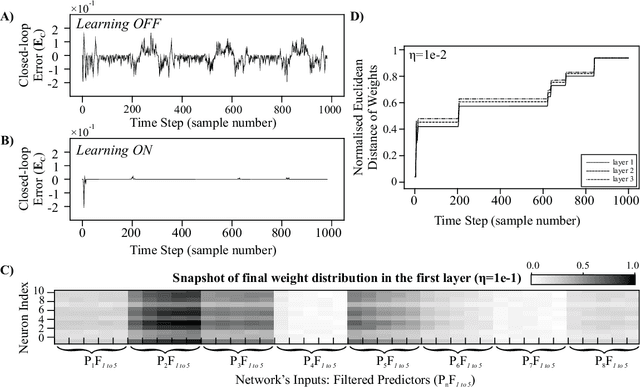
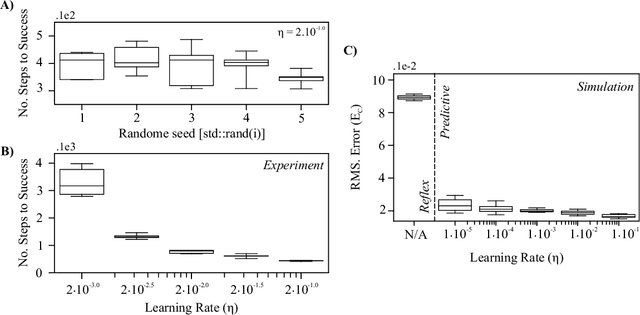
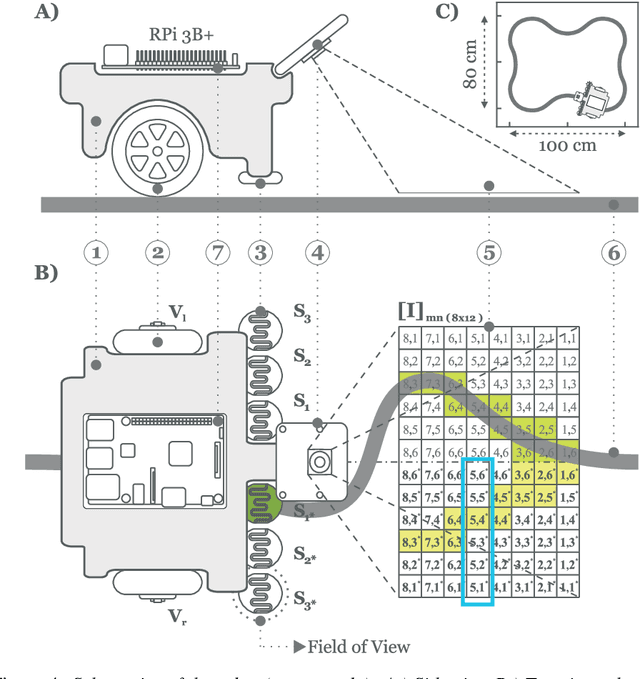
A reflex is a simple closed loop control approach which tries to minimise an error but fails to do so because it will always react too late. An adaptive algorithm can use this error to learn a forward model with the help of predictive cues. For example a driver learns to improve their steering by looking ahead to avoid steering in the last minute. In order to process complex cues such as the road ahead deep learning is a natural choice. However, this is usually only achieved indirectly by employing deep reinforcement learning having a discrete state space. Here, we show how this can be directly achieved by embedding deep learning into a closed loop system and preserving its continuous processing. We show specifically how error back-propagation can be achieved in z-space and in general how gradient based approaches can be analysed in such closed loop scenarios. The performance of this learning paradigm is demonstrated using a line-follower both in simulation and on a real robot that show very fast and continuous learning.