 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGMCR: Graph-based Maximum Consensus Estimation for Point Cloud Registration
Mar 07, 2023



Point cloud registration is a fundamental and challenging problem for autonomous robots interacting in unstructured environments for applications such as object pose estimation, simultaneous localization and mapping, robot-sensor calibration, and so on. In global correspondence-based point cloud registration, data association is a highly brittle task and commonly produces high amounts of outliers. Failure to reject outliers can lead to errors propagating to downstream perception tasks. Maximum Consensus (MC) is a widely used technique for robust estimation, which is however known to be NP-hard. Exact methods struggle to scale to realistic problem instances, whereas high outlier rates are challenging for approximate methods. To this end, we propose Graph-based Maximum Consensus Registration (GMCR), which is highly robust to outliers and scales to realistic problem instances. We propose novel consensus functions to map the decoupled MC-objective to the graph domain, wherein we find a tight approximation to the maximum consensus set as the maximum clique. The final pose estimate is given in closed-form. We extensively evaluated our proposed GMCR on a synthetic registration benchmark, robotic object localization task, and additionally on a scan matching benchmark. Our proposed method shows high accuracy and time efficiency compared to other state-of-the-art MC methods and compares favorably to other robust registration methods.
Active Visuo-Tactile Interactive Robotic Perception for Accurate Object Pose Estimation in Dense Clutter
Feb 04, 2022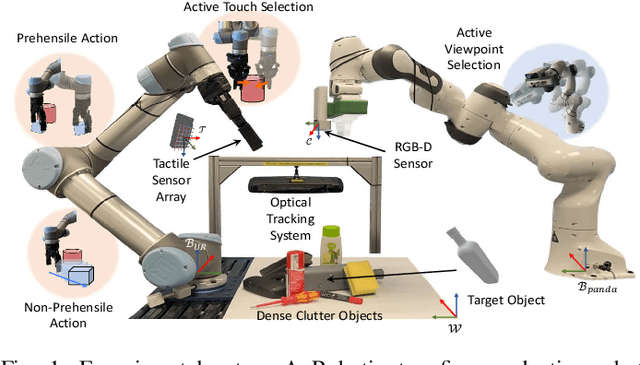
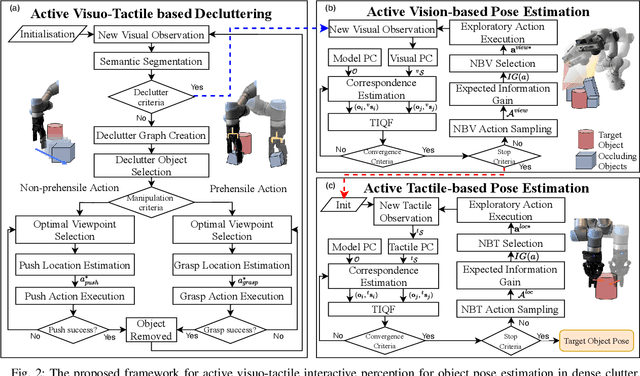
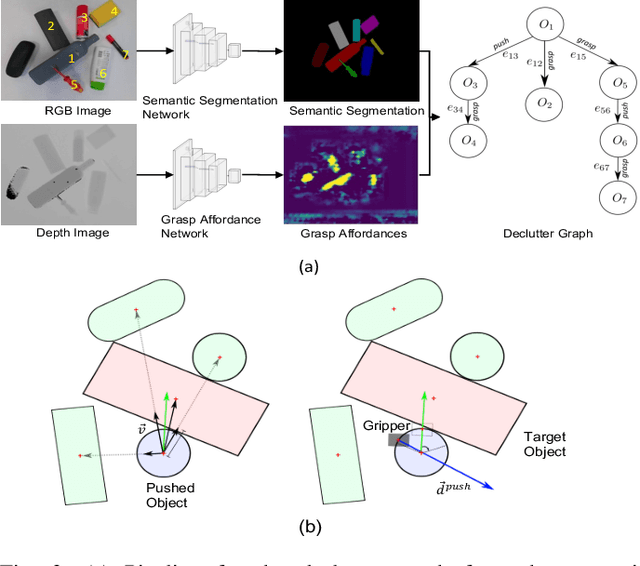
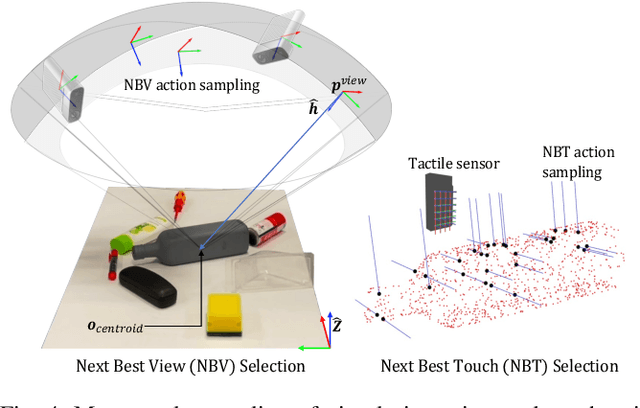
This work presents a novel active visuo-tactile based framework for robotic systems to accurately estimate pose of objects in dense cluttered environments. The scene representation is derived using a novel declutter graph (DG) which describes the relationship among objects in the scene for decluttering by leveraging semantic segmentation and grasp affordances networks. The graph formulation allows robots to efficiently declutter the workspace by autonomously selecting the next best object to remove and the optimal action (prehensile or non-prehensile) to perform. Furthermore, we propose a novel translation-invariant Quaternion filter (TIQF) for active vision and active tactile based pose estimation. Both active visual and active tactile points are selected by maximizing the expected information gain. We evaluate our proposed framework on a system with two robots coordinating on randomized scenes of dense cluttered objects and perform ablation studies with static vision and active vision based estimation prior and post decluttering as baselines. Our proposed active visuo-tactile interactive perception framework shows upto 36% improvement in pose accuracy compared to the active vision baseline.
Active Visuo-Tactile Point Cloud Registration for Accurate Pose Estimation of Objects in an Unknown Workspace
Aug 09, 2021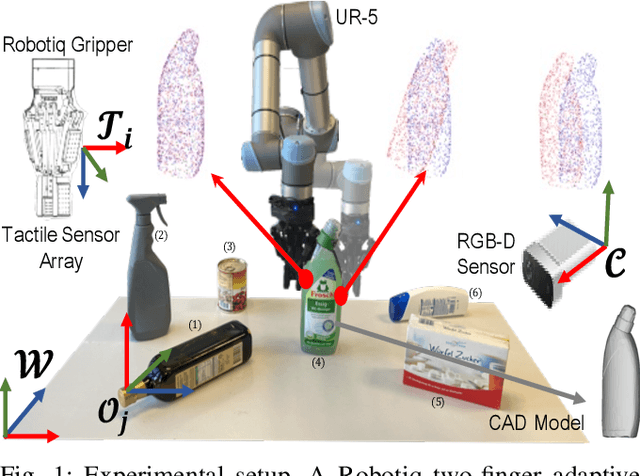
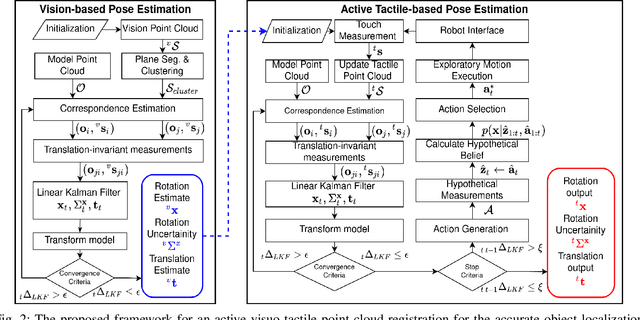
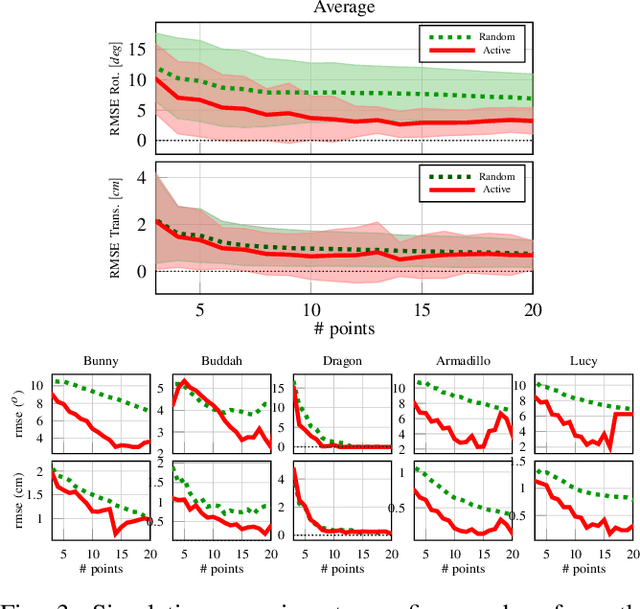
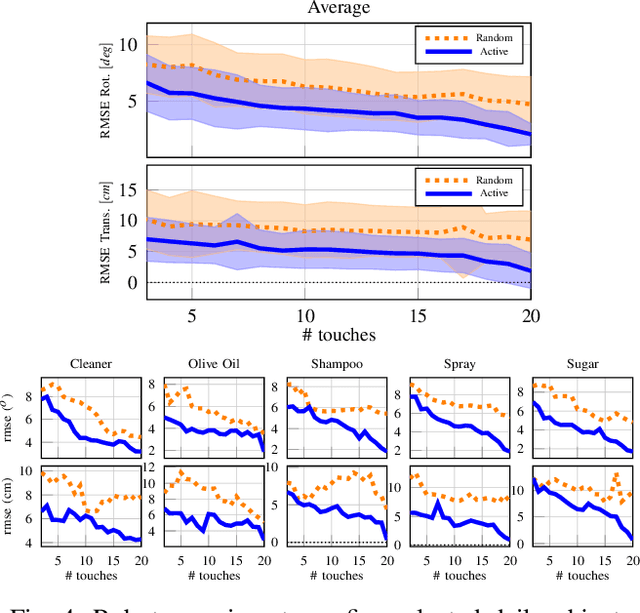
This paper proposes a novel active visuo-tactile based methodology wherein the accurate estimation of the time-invariant SE(3) pose of objects is considered for autonomous robotic manipulators. The robot equipped with tactile sensors on the gripper is guided by a vision estimate to actively explore and localize the objects in the unknown workspace. The robot is capable of reasoning over multiple potential actions, and execute the action to maximize information gain to update the current belief of the object. We formulate the pose estimation process as a linear translation invariant quaternion filter (TIQF) by decoupling the estimation of translation and rotation and formulating the update and measurement model in linear form. We perform pose estimation sequentially on acquired measurements using very sparse point cloud as acquiring each measurement using tactile sensing is time consuming. Furthermore, our proposed method is computationally efficient to perform an exhaustive uncertainty-based active touch selection strategy in real-time without the need for trading information gain with execution time. We evaluated the performance of our approach extensively in simulation and by a robotic system.