 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImagen 3
Aug 13, 2024We introduce Imagen 3, a latent diffusion model that generates high quality images from text prompts. We describe our quality and responsibility evaluations. Imagen 3 is preferred over other state-of-the-art (SOTA) models at the time of evaluation. In addition, we discuss issues around safety and representation, as well as methods we used to minimize the potential harm of our models.
GATS: Gather-Attend-Scatter
Jan 16, 2024As the AI community increasingly adopts large-scale models, it is crucial to develop general and flexible tools to integrate them. We introduce Gather-Attend-Scatter (GATS), a novel module that enables seamless combination of pretrained foundation models, both trainable and frozen, into larger multimodal networks. GATS empowers AI systems to process and generate information across multiple modalities at different rates. In contrast to traditional fine-tuning, GATS allows for the original component models to remain frozen, avoiding the risk of them losing important knowledge acquired during the pretraining phase. We demonstrate the utility and versatility of GATS with a few experiments across games, robotics, and multimodal input-output systems.
Resonance: Replacing Software Constants with Context-Aware Models in Real-time Communication
Nov 23, 2020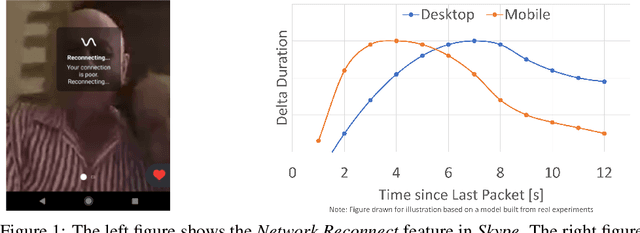


Large software systems tune hundreds of 'constants' to optimize their runtime performance. These values are commonly derived through intuition, lab tests, or A/B tests. A 'one-size-fits-all' approach is often sub-optimal as the best value depends on runtime context. In this paper, we provide an experimental approach to replace constants with learned contextual functions for Skype - a widely used real-time communication (RTC) application. We present Resonance, a system based on contextual bandits (CB). We describe experiences from three real-world experiments: applying it to the audio, video, and transport components in Skype. We surface a unique and practical challenge of performing machine learning (ML) inference in large software systems written using encapsulation principles. Finally, we open-source FeatureBroker, a library to reduce the friction in adopting ML models in such development environments
Recurrent and Contextual Models for Visual Question Answering
Mar 23, 2017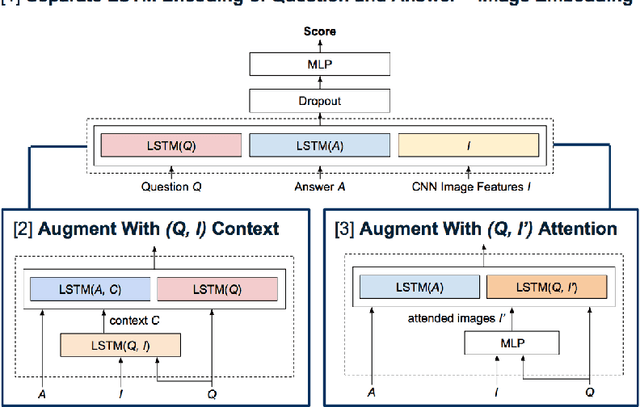
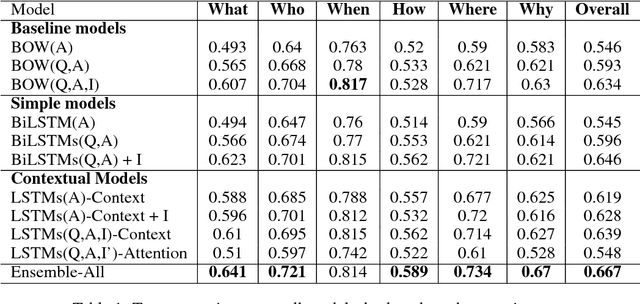


We propose a series of recurrent and contextual neural network models for multiple choice visual question answering on the Visual7W dataset. Motivated by divergent trends in model complexities in the literature, we explore the balance between model expressiveness and simplicity by studying incrementally more complex architectures. We start with LSTM-encoding of input questions and answers; build on this with context generation by LSTM-encodings of neural image and question representations and attention over images; and evaluate the diversity and predictive power of our models and the ensemble thereof. All models are evaluated against a simple baseline inspired by the current state-of-the-art, consisting of involving simple concatenation of bag-of-words and CNN representations for the text and images, respectively. Generally, we observe marked variation in image-reasoning performance between our models not obvious from their overall performance, as well as evidence of dataset bias. Our standalone models achieve accuracies up to $64.6\%$, while the ensemble of all models achieves the best accuracy of $66.67\%$, within $0.5\%$ of the current state-of-the-art for Visual7W.