 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenAI GPT-5 System Card
Dec 19, 2025This is the system card published alongside the OpenAI GPT-5 launch, August 2025. GPT-5 is a unified system with a smart and fast model that answers most questions, a deeper reasoning model for harder problems, and a real-time router that quickly decides which model to use based on conversation type, complexity, tool needs, and explicit intent (for example, if you say 'think hard about this' in the prompt). The router is continuously trained on real signals, including when users switch models, preference rates for responses, and measured correctness, improving over time. Once usage limits are reached, a mini version of each model handles remaining queries. This system card focuses primarily on gpt-5-thinking and gpt-5-main, while evaluations for other models are available in the appendix. The GPT-5 system not only outperforms previous models on benchmarks and answers questions more quickly, but -- more importantly -- is more useful for real-world queries. We've made significant advances in reducing hallucinations, improving instruction following, and minimizing sycophancy, and have leveled up GPT-5's performance in three of ChatGPT's most common uses: writing, coding, and health. All of the GPT-5 models additionally feature safe-completions, our latest approach to safety training to prevent disallowed content. Similarly to ChatGPT agent, we have decided to treat gpt-5-thinking as High capability in the Biological and Chemical domain under our Preparedness Framework, activating the associated safeguards. While we do not have definitive evidence that this model could meaningfully help a novice to create severe biological harm -- our defined threshold for High capability -- we have chosen to take a precautionary approach.
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Mar 08, 2024In this report, we present the latest model of the Gemini family, Gemini 1.5 Pro, a highly compute-efficient multimodal mixture-of-experts model capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. Gemini 1.5 Pro achieves near-perfect recall on long-context retrieval tasks across modalities, improves the state-of-the-art in long-document QA, long-video QA and long-context ASR, and matches or surpasses Gemini 1.0 Ultra's state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5 Pro's long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 2.1 (200k) and GPT-4 Turbo (128k). Finally, we highlight surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
Vision-Language Models as Success Detectors
Mar 13, 2023Detecting successful behaviour is crucial for training intelligent agents. As such, generalisable reward models are a prerequisite for agents that can learn to generalise their behaviour. In this work we focus on developing robust success detectors that leverage large, pretrained vision-language models (Flamingo, Alayrac et al. (2022)) and human reward annotations. Concretely, we treat success detection as a visual question answering (VQA) problem, denoted SuccessVQA. We study success detection across three vastly different domains: (i) interactive language-conditioned agents in a simulated household, (ii) real world robotic manipulation, and (iii) "in-the-wild" human egocentric videos. We investigate the generalisation properties of a Flamingo-based success detection model across unseen language and visual changes in the first two domains, and find that the proposed method is able to outperform bespoke reward models in out-of-distribution test scenarios with either variation. In the last domain of "in-the-wild" human videos, we show that success detection on unseen real videos presents an even more challenging generalisation task warranting future work. We hope our initial results encourage further work in real world success detection and reward modelling.
Improving Multimodal Interactive Agents with Reinforcement Learning from Human Feedback
Nov 21, 2022An important goal in artificial intelligence is to create agents that can both interact naturally with humans and learn from their feedback. Here we demonstrate how to use reinforcement learning from human feedback (RLHF) to improve upon simulated, embodied agents trained to a base level of competency with imitation learning. First, we collected data of humans interacting with agents in a simulated 3D world. We then asked annotators to record moments where they believed that agents either progressed toward or regressed from their human-instructed goal. Using this annotation data we leveraged a novel method - which we call "Inter-temporal Bradley-Terry" (IBT) modelling - to build a reward model that captures human judgments. Agents trained to optimise rewards delivered from IBT reward models improved with respect to all of our metrics, including subsequent human judgment during live interactions with agents. Altogether our results demonstrate how one can successfully leverage human judgments to improve agent behaviour, allowing us to use reinforcement learning in complex, embodied domains without programmatic reward functions. Videos of agent behaviour may be found at https://youtu.be/v_Z9F2_eKk4.
Evaluating Multimodal Interactive Agents
May 26, 2022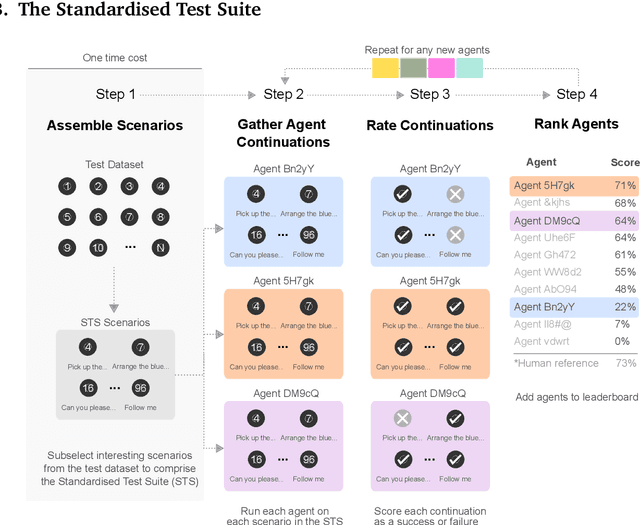
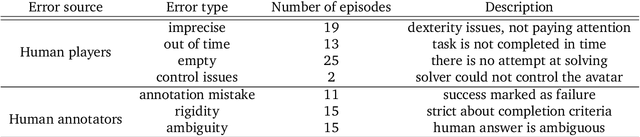
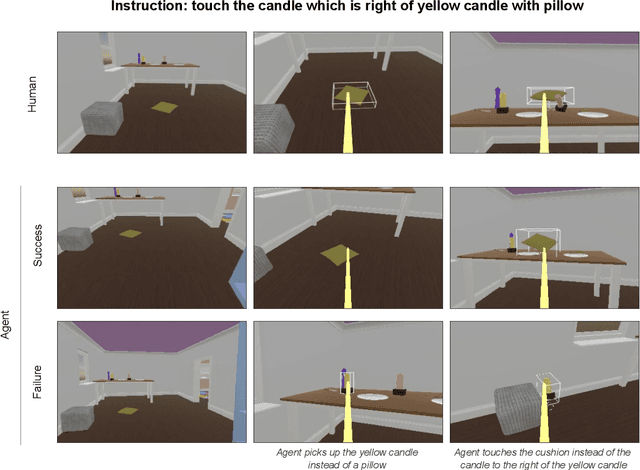

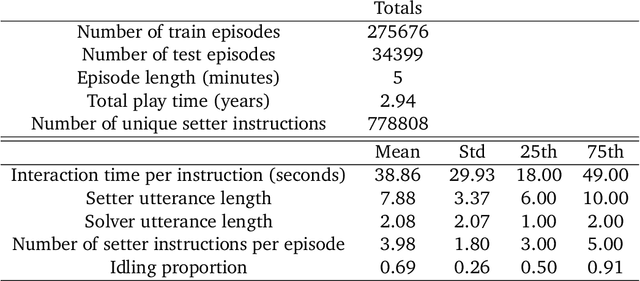
Creating agents that can interact naturally with humans is a common goal in artificial intelligence (AI) research. However, evaluating these interactions is challenging: collecting online human-agent interactions is slow and expensive, yet faster proxy metrics often do not correlate well with interactive evaluation. In this paper, we assess the merits of these existing evaluation metrics and present a novel approach to evaluation called the Standardised Test Suite (STS). The STS uses behavioural scenarios mined from real human interaction data. Agents see replayed scenario context, receive an instruction, and are then given control to complete the interaction offline. These agent continuations are recorded and sent to human annotators to mark as success or failure, and agents are ranked according to the proportion of continuations in which they succeed. The resulting STS is fast, controlled, interpretable, and representative of naturalistic interactions. Altogether, the STS consolidates much of what is desirable across many of our standard evaluation metrics, allowing us to accelerate research progress towards producing agents that can interact naturally with humans. https://youtu.be/YR1TngGORGQ
Creating Multimodal Interactive Agents with Imitation and Self-Supervised Learning
Dec 07, 2021
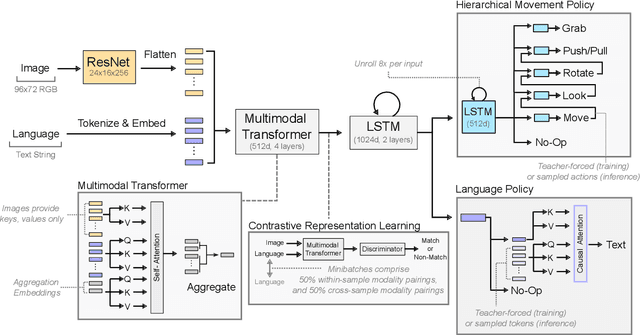
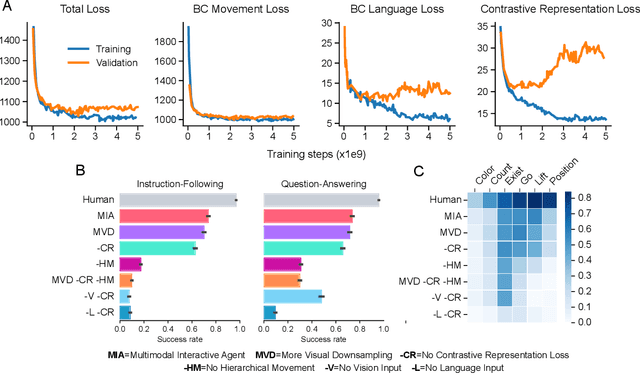
A common vision from science fiction is that robots will one day inhabit our physical spaces, sense the world as we do, assist our physical labours, and communicate with us through natural language. Here we study how to design artificial agents that can interact naturally with humans using the simplification of a virtual environment. We show that imitation learning of human-human interactions in a simulated world, in conjunction with self-supervised learning, is sufficient to produce a multimodal interactive agent, which we call MIA, that successfully interacts with non-adversarial humans 75% of the time. We further identify architectural and algorithmic techniques that improve performance, such as hierarchical action selection. Altogether, our results demonstrate that imitation of multi-modal, real-time human behaviour may provide a straightforward and surprisingly effective means of imbuing agents with a rich behavioural prior from which agents might then be fine-tuned for specific purposes, thus laying a foundation for training capable agents for interactive robots or digital assistants. A video of MIA's behaviour may be found at https://youtu.be/ZFgRhviF7mY
Imitating Interactive Intelligence
Jan 21, 2021
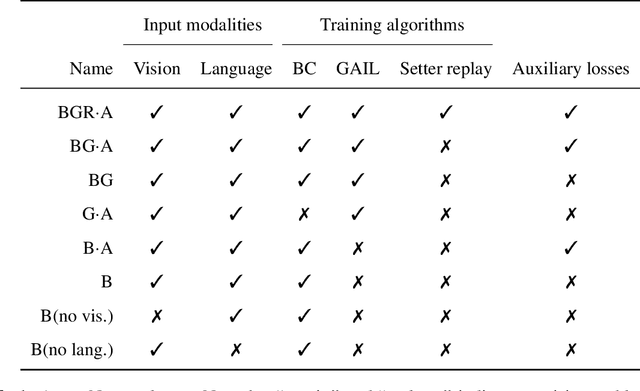
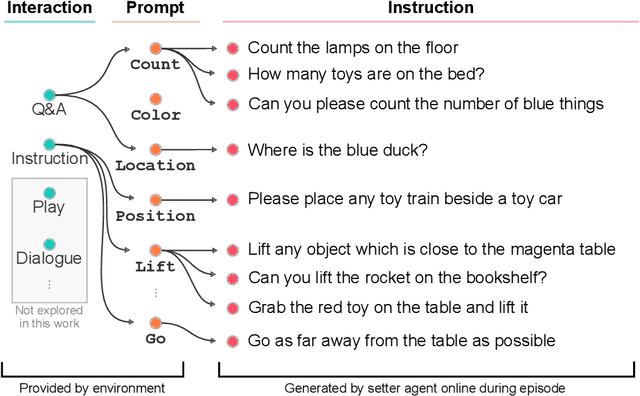
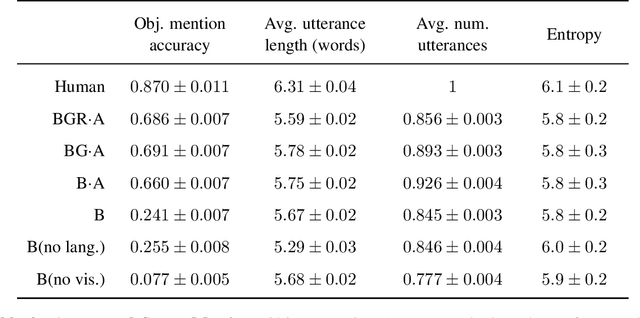
A common vision from science fiction is that robots will one day inhabit our physical spaces, sense the world as we do, assist our physical labours, and communicate with us through natural language. Here we study how to design artificial agents that can interact naturally with humans using the simplification of a virtual environment. This setting nevertheless integrates a number of the central challenges of artificial intelligence (AI) research: complex visual perception and goal-directed physical control, grounded language comprehension and production, and multi-agent social interaction. To build agents that can robustly interact with humans, we would ideally train them while they interact with humans. However, this is presently impractical. Therefore, we approximate the role of the human with another learned agent, and use ideas from inverse reinforcement learning to reduce the disparities between human-human and agent-agent interactive behaviour. Rigorously evaluating our agents poses a great challenge, so we develop a variety of behavioural tests, including evaluation by humans who watch videos of agents or interact directly with them. These evaluations convincingly demonstrate that interactive training and auxiliary losses improve agent behaviour beyond what is achieved by supervised learning of actions alone. Further, we demonstrate that agent capabilities generalise beyond literal experiences in the dataset. Finally, we train evaluation models whose ratings of agents agree well with human judgement, thus permitting the evaluation of new agent models without additional effort. Taken together, our results in this virtual environment provide evidence that large-scale human behavioural imitation is a promising tool to create intelligent, interactive agents, and the challenge of reliably evaluating such agents is possible to surmount.