 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Multimodal Interactive Agents
Paper and Code
May 26, 2022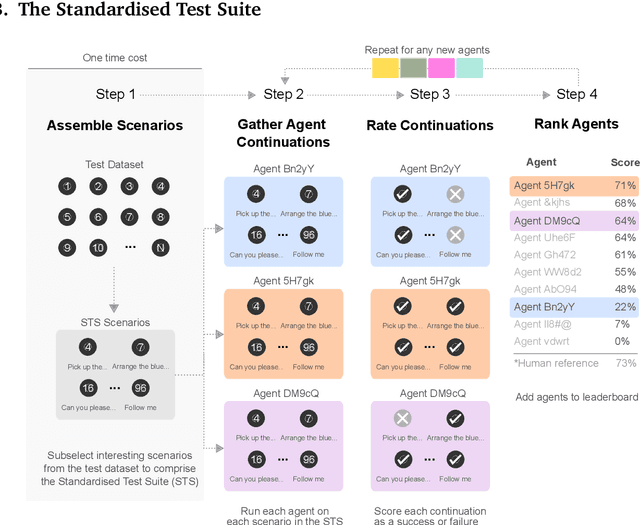
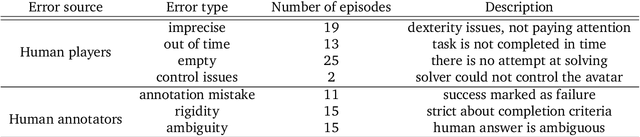
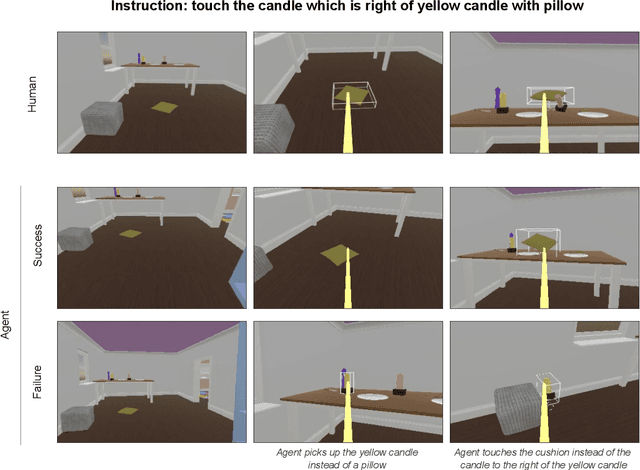

Creating agents that can interact naturally with humans is a common goal in artificial intelligence (AI) research. However, evaluating these interactions is challenging: collecting online human-agent interactions is slow and expensive, yet faster proxy metrics often do not correlate well with interactive evaluation. In this paper, we assess the merits of these existing evaluation metrics and present a novel approach to evaluation called the Standardised Test Suite (STS). The STS uses behavioural scenarios mined from real human interaction data. Agents see replayed scenario context, receive an instruction, and are then given control to complete the interaction offline. These agent continuations are recorded and sent to human annotators to mark as success or failure, and agents are ranked according to the proportion of continuations in which they succeed. The resulting STS is fast, controlled, interpretable, and representative of naturalistic interactions. Altogether, the STS consolidates much of what is desirable across many of our standard evaluation metrics, allowing us to accelerate research progress towards producing agents that can interact naturally with humans. https://youtu.be/YR1TngGORGQ