 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal representation models for prediction and control from partial information
Paper and Code
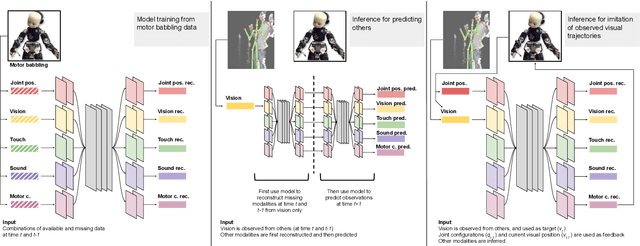



Similar to humans, robots benefit from interacting with their environment through a number of different sensor modalities, such as vision, touch, sound. However, learning from different sensor modalities is difficult, because the learning model must be able to handle diverse types of signals, and learn a coherent representation even when parts of the sensor inputs are missing. In this paper, a multimodal variational autoencoder is proposed to enable an iCub humanoid robot to learn representations of its sensorimotor capabilities from different sensor modalities. The proposed model is able to (1) reconstruct missing sensory modalities, (2) predict the sensorimotor state of self and the visual trajectories of other agents actions, and (3) control the agent to imitate an observed visual trajectory. Also, the proposed multimodal variational autoencoder can capture the kinematic redundancy of the robot motion through the learned probability distribution. Training multimodal models is not trivial due to the combinatorial complexity given by the possibility of missing modalities. We propose a strategy to train multimodal models, which successfully achieves improved performance of different reconstruction models. Finally, extensive experiments have been carried out using an iCub humanoid robot, showing high performance in multiple reconstruction, prediction and imitation tasks.