 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimultaneously Learning Vision and Feature-based Control Policies for Real-world Ball-in-a-Cup
Paper and Code
Feb 18, 2019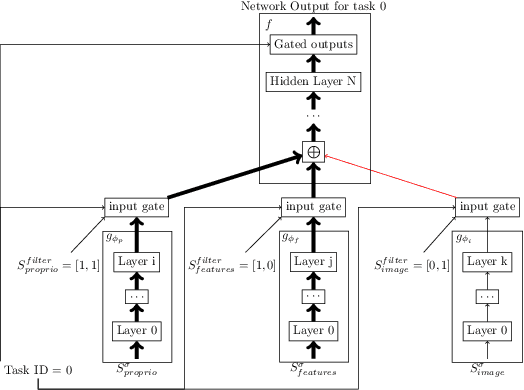

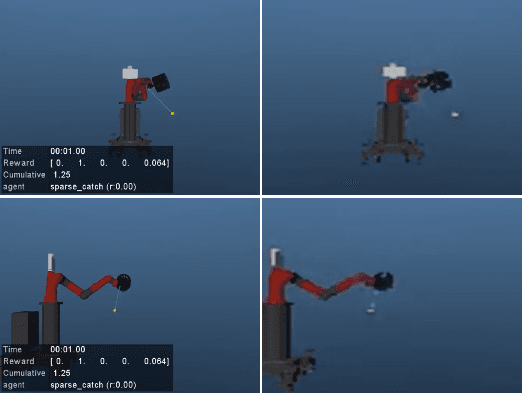

We present a method for fast training of vision based control policies on real robots. The key idea behind our method is to perform multi-task Reinforcement Learning with auxiliary tasks that differ not only in the reward to be optimized but also in the state-space in which they operate. In particular, we allow auxiliary task policies to utilize task features that are available only at training-time. This allows for fast learning of auxiliary policies, which subsequently generate good data for training the main, vision-based control policies. This method can be seen as an extension of the Scheduled Auxiliary Control (SAC-X) framework. We demonstrate the efficacy of our method by using both a simulated and real-world Ball-in-a-Cup game controlled by a robot arm. In simulation, our approach leads to significant learning speed-ups when compared to standard SAC-X. On the real robot we show that the task can be learned from-scratch, i.e., with no transfer from simulation and no imitation learning. Videos of our learned policies running on the real robot can be found at https://sites.google.com/view/rss-2019-sawyer-bic/.