 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Positive Case for Faithfulness: LLM Self-Explanations Help Predict Model Behavior
Feb 02, 2026LLM self-explanations are often presented as a promising tool for AI oversight, yet their faithfulness to the model's true reasoning process is poorly understood. Existing faithfulness metrics have critical limitations, typically relying on identifying unfaithfulness via adversarial prompting or detecting reasoning errors. These methods overlook the predictive value of explanations. We introduce Normalized Simulatability Gain (NSG), a general and scalable metric based on the idea that a faithful explanation should allow an observer to learn a model's decision-making criteria, and thus better predict its behavior on related inputs. We evaluate 18 frontier proprietary and open-weight models, e.g., Gemini 3, GPT-5.2, and Claude 4.5, on 7,000 counterfactuals from popular datasets covering health, business, and ethics. We find self-explanations substantially improve prediction of model behavior (11-37% NSG). Self-explanations also provide more predictive information than explanations generated by external models, even when those models are stronger. This implies an advantage from self-knowledge that external explanation methods cannot replicate. Our approach also reveals that, across models, 5-15% of self-explanations are egregiously misleading. Despite their imperfections, we show a positive case for self-explanations: they encode information that helps predict model behavior.
Faithfulness of LLM Self-Explanations for Commonsense Tasks: Larger Is Better, and Instruction-Tuning Allows Trade-Offs but Not Pareto Dominance
Mar 17, 2025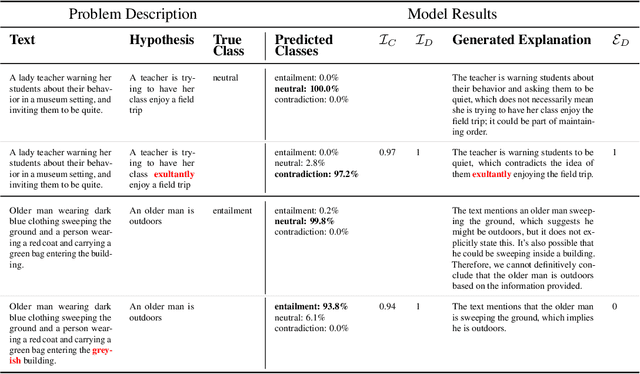
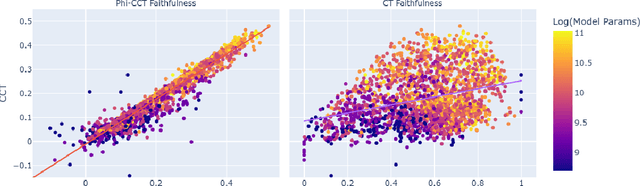
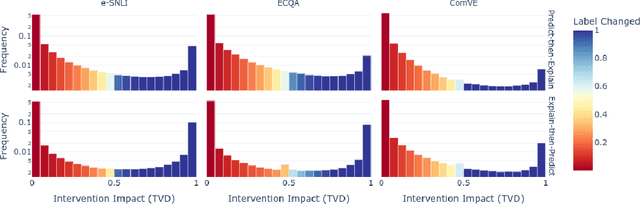
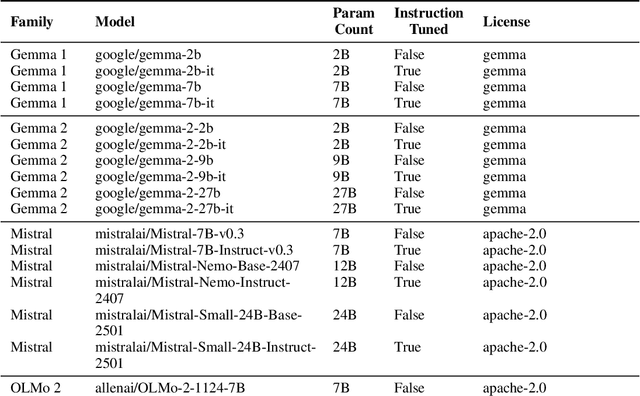
As large language models (LLMs) become increasingly capable, ensuring that their self-generated explanations are faithful to their internal decision-making process is critical for safety and oversight. In this work, we conduct a comprehensive counterfactual faithfulness analysis across 62 models from 8 families, encompassing both pretrained and instruction-tuned variants and significantly extending prior studies of counterfactual tests. We introduce phi-CCT, a simplified variant of the Correlational Counterfactual Test, which avoids the need for token probabilities while explaining most of the variance of the original test. Our findings reveal clear scaling trends: larger models are consistently more faithful on our metrics. However, when comparing instruction-tuned and human-imitated explanations, we find that observed differences in faithfulness can often be attributed to explanation verbosity, leading to shifts along the true-positive/false-positive Pareto frontier. While instruction-tuning and prompting can influence this trade-off, we find limited evidence that they fundamentally expand the frontier of explanatory faithfulness beyond what is achievable with pretrained models of comparable size. Our analysis highlights the nuanced relationship between instruction-tuning, verbosity, and the faithful representation of model decision processes.
On scalable oversight with weak LLMs judging strong LLMs
Jul 05, 2024



Scalable oversight protocols aim to enable humans to accurately supervise superhuman AI. In this paper we study debate, where two AI's compete to convince a judge; consultancy, where a single AI tries to convince a judge that asks questions; and compare to a baseline of direct question-answering, where the judge just answers outright without the AI. We use large language models (LLMs) as both AI agents and as stand-ins for human judges, taking the judge models to be weaker than agent models. We benchmark on a diverse range of asymmetries between judges and agents, extending previous work on a single extractive QA task with information asymmetry, to also include mathematics, coding, logic and multimodal reasoning asymmetries. We find that debate outperforms consultancy across all tasks when the consultant is randomly assigned to argue for the correct/incorrect answer. Comparing debate to direct question answering, the results depend on the type of task: in extractive QA tasks with information asymmetry debate outperforms direct question answering, but in other tasks without information asymmetry the results are mixed. Previous work assigned debaters/consultants an answer to argue for. When we allow them to instead choose which answer to argue for, we find judges are less frequently convinced by the wrong answer in debate than in consultancy. Further, we find that stronger debater models increase judge accuracy, though more modestly than in previous studies.
The Probabilities Also Matter: A More Faithful Metric for Faithfulness of Free-Text Explanations in Large Language Models
Apr 04, 2024



In order to oversee advanced AI systems, it is important to understand their underlying decision-making process. When prompted, large language models (LLMs) can provide natural language explanations or reasoning traces that sound plausible and receive high ratings from human annotators. However, it is unclear to what extent these explanations are faithful, i.e., truly capture the factors responsible for the model's predictions. In this work, we introduce Correlational Explanatory Faithfulness (CEF), a metric that can be used in faithfulness tests based on input interventions. Previous metrics used in such tests take into account only binary changes in the predictions. Our metric accounts for the total shift in the model's predicted label distribution, more accurately reflecting the explanations' faithfulness. We then introduce the Correlational Counterfactual Test (CCT) by instantiating CEF on the Counterfactual Test (CT) from Atanasova et al. (2023). We evaluate the faithfulness of free-text explanations generated by few-shot-prompted LLMs from the Llama2 family on three NLP tasks. We find that our metric measures aspects of faithfulness which the CT misses.
Learning Agile Soccer Skills for a Bipedal Robot with Deep Reinforcement Learning
Apr 26, 2023We investigate whether Deep Reinforcement Learning (Deep RL) is able to synthesize sophisticated and safe movement skills for a low-cost, miniature humanoid robot that can be composed into complex behavioral strategies in dynamic environments. We used Deep RL to train a humanoid robot with 20 actuated joints to play a simplified one-versus-one (1v1) soccer game. We first trained individual skills in isolation and then composed those skills end-to-end in a self-play setting. The resulting policy exhibits robust and dynamic movement skills such as rapid fall recovery, walking, turning, kicking and more; and transitions between them in a smooth, stable, and efficient manner - well beyond what is intuitively expected from the robot. The agents also developed a basic strategic understanding of the game, and learned, for instance, to anticipate ball movements and to block opponent shots. The full range of behaviors emerged from a small set of simple rewards. Our agents were trained in simulation and transferred to real robots zero-shot. We found that a combination of sufficiently high-frequency control, targeted dynamics randomization, and perturbations during training in simulation enabled good-quality transfer, despite significant unmodeled effects and variations across robot instances. Although the robots are inherently fragile, minor hardware modifications together with basic regularization of the behavior during training led the robots to learn safe and effective movements while still performing in a dynamic and agile way. Indeed, even though the agents were optimized for scoring, in experiments they walked 156% faster, took 63% less time to get up, and kicked 24% faster than a scripted baseline, while efficiently combining the skills to achieve the longer term objectives. Examples of the emergent behaviors and full 1v1 matches are available on the supplementary website.
From Motor Control to Team Play in Simulated Humanoid Football
May 25, 2021

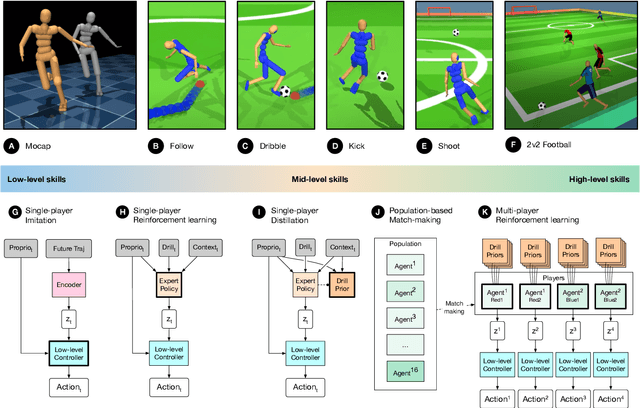

Intelligent behaviour in the physical world exhibits structure at multiple spatial and temporal scales. Although movements are ultimately executed at the level of instantaneous muscle tensions or joint torques, they must be selected to serve goals defined on much longer timescales, and in terms of relations that extend far beyond the body itself, ultimately involving coordination with other agents. Recent research in artificial intelligence has shown the promise of learning-based approaches to the respective problems of complex movement, longer-term planning and multi-agent coordination. However, there is limited research aimed at their integration. We study this problem by training teams of physically simulated humanoid avatars to play football in a realistic virtual environment. We develop a method that combines imitation learning, single- and multi-agent reinforcement learning and population-based training, and makes use of transferable representations of behaviour for decision making at different levels of abstraction. In a sequence of stages, players first learn to control a fully articulated body to perform realistic, human-like movements such as running and turning; they then acquire mid-level football skills such as dribbling and shooting; finally, they develop awareness of others and play as a team, bridging the gap between low-level motor control at a timescale of milliseconds, and coordinated goal-directed behaviour as a team at the timescale of tens of seconds. We investigate the emergence of behaviours at different levels of abstraction, as well as the representations that underlie these behaviours using several analysis techniques, including statistics from real-world sports analytics. Our work constitutes a complete demonstration of integrated decision-making at multiple scales in a physically embodied multi-agent setting. See project video at https://youtu.be/KHMwq9pv7mg.
Keep Doing What Worked: Behavioral Modelling Priors for Offline Reinforcement Learning
Feb 23, 2020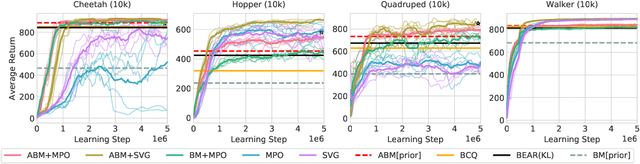

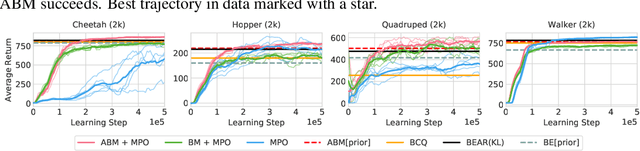
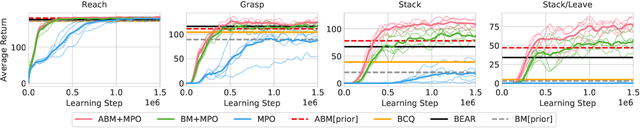
Off-policy reinforcement learning algorithms promise to be applicable in settings where only a fixed data-set (batch) of environment interactions is available and no new experience can be acquired. This property makes these algorithms appealing for real world problems such as robot control. In practice, however, standard off-policy algorithms fail in the batch setting for continuous control. In this paper, we propose a simple solution to this problem. It admits the use of data generated by arbitrary behavior policies and uses a learned prior -- the advantage-weighted behavior model (ABM) -- to bias the RL policy towards actions that have previously been executed and are likely to be successful on the new task. Our method can be seen as an extension of recent work on batch-RL that enables stable learning from conflicting data-sources. We find improvements on competitive baselines in a variety of RL tasks -- including standard continuous control benchmarks and multi-task learning for simulated and real-world robots.