 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Trajectory Bundle Method: Unifying Sequential-Convex Programming and Sampling-Based Trajectory Optimization
Sep 30, 2025



We present a unified framework for solving trajectory optimization problems in a derivative-free manner through the use of sequential convex programming. Traditionally, nonconvex optimization problems are solved by forming and solving a sequence of convex optimization problems, where the cost and constraint functions are approximated locally through Taylor series expansions. This presents a challenge for functions where differentiation is expensive or unavailable. In this work, we present a derivative-free approach to form these convex approximations by computing samples of the dynamics, cost, and constraint functions and letting the solver interpolate between them. Our framework includes sample-based trajectory optimization techniques like model-predictive path integral (MPPI) control as a special case and generalizes them to enable features like multiple shooting and general equality and inequality constraints that are traditionally associated with derivative-based sequential convex programming methods. The resulting framework is simple, flexible, and capable of solving a wide variety of practical motion planning and control problems.
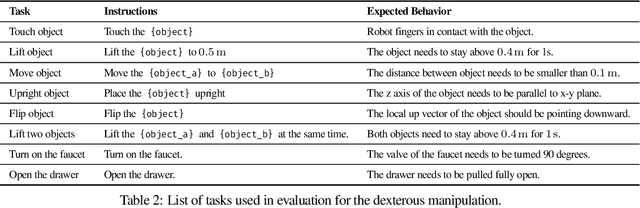
ExoStart: Efficient learning for dexterous manipulation with sensorized exoskeleton demonstrations
Jun 13, 2025



Recent advancements in teleoperation systems have enabled high-quality data collection for robotic manipulators, showing impressive results in learning manipulation at scale. This progress suggests that extending these capabilities to robotic hands could unlock an even broader range of manipulation skills, especially if we could achieve the same level of dexterity that human hands exhibit. However, teleoperating robotic hands is far from a solved problem, as it presents a significant challenge due to the high degrees of freedom of robotic hands and the complex dynamics occurring during contact-rich settings. In this work, we present ExoStart, a general and scalable learning framework that leverages human dexterity to improve robotic hand control. In particular, we obtain high-quality data by collecting direct demonstrations without a robot in the loop using a sensorized low-cost wearable exoskeleton, capturing the rich behaviors that humans can demonstrate with their own hands. We also propose a simulation-based dynamics filter that generates dynamically feasible trajectories from the collected demonstrations and use the generated trajectories to bootstrap an auto-curriculum reinforcement learning method that relies only on simple sparse rewards. The ExoStart pipeline is generalizable and yields robust policies that transfer zero-shot to the real robot. Our results demonstrate that ExoStart can generate dexterous real-world hand skills, achieving a success rate above 50% on a wide range of complex tasks such as opening an AirPods case or inserting and turning a key in a lock. More details and videos can be found in https://sites.google.com/view/exostart.
Splatting Physical Scenes: End-to-End Real-to-Sim from Imperfect Robot Data
Jun 09, 2025Creating accurate, physical simulations directly from real-world robot motion holds great value for safe, scalable, and affordable robot learning, yet remains exceptionally challenging. Real robot data suffers from occlusions, noisy camera poses, dynamic scene elements, which hinder the creation of geometrically accurate and photorealistic digital twins of unseen objects. We introduce a novel real-to-sim framework tackling all these challenges at once. Our key insight is a hybrid scene representation merging the photorealistic rendering of 3D Gaussian Splatting with explicit object meshes suitable for physics simulation within a single representation. We propose an end-to-end optimization pipeline that leverages differentiable rendering and differentiable physics within MuJoCo to jointly refine all scene components - from object geometry and appearance to robot poses and physical parameters - directly from raw and imprecise robot trajectories. This unified optimization allows us to simultaneously achieve high-fidelity object mesh reconstruction, generate photorealistic novel views, and perform annotation-free robot pose calibration. We demonstrate the effectiveness of our approach both in simulation and on challenging real-world sequences using an ALOHA 2 bi-manual manipulator, enabling more practical and robust real-to-simulation pipelines.
Whole-Body Model-Predictive Control of Legged Robots with MuJoCo
Mar 06, 2025
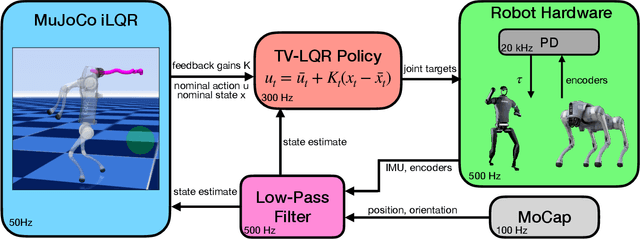

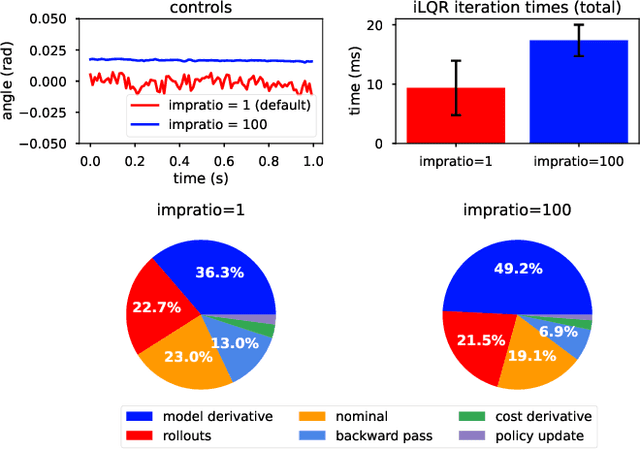
We demonstrate the surprising real-world effectiveness of a very simple approach to whole-body model-predictive control (MPC) of quadruped and humanoid robots: the iterative LQR (iLQR) algorithm with MuJoCo dynamics and finite-difference approximated derivatives. Building upon the previous success of model-based behavior synthesis and control of locomotion and manipulation tasks with MuJoCo in simulation, we show that these policies can easily generalize to the real world with few sim-to-real considerations. Our baseline method achieves real-time whole-body MPC on a variety of hardware experiments, including dynamic quadruped locomotion, quadruped walking on two legs, and full-sized humanoid bipedal locomotion. We hope this easy-to-reproduce hardware baseline lowers the barrier to entry for real-world whole-body MPC research and contributes to accelerating research velocity in the community. Our code and experiment videos will be available online at:https://johnzhang3.github.io/mujoco_ilqr
Efficient Online Learning of Contact Force Models for Connector Insertion
Dec 14, 2023Contact-rich manipulation tasks with stiff frictional elements like connector insertion are difficult to model with rigid-body simulators. In this work, we propose a new approach for modeling these environments by learning a quasi-static contact force model instead of a full simulator. Using a feature vector that contains information about the configuration and control, we find a linear mapping adequately captures the relationship between this feature vector and the sensed contact forces. A novel Linear Model Learning (LML) algorithm is used to solve for the globally optimal mapping in real time without any matrix inversions, resulting in an algorithm that runs in nearly constant time on a GPU as the model size increases. We validate the proposed approach for connector insertion both in simulation and hardware experiments, where the learned model is combined with an optimization-based controller to achieve smooth insertions in the presence of misalignments and uncertainty. Our website featuring videos, code, and more materials is available at https://model-based-plugging.github.io/.
Language to Rewards for Robotic Skill Synthesis
Jun 16, 2023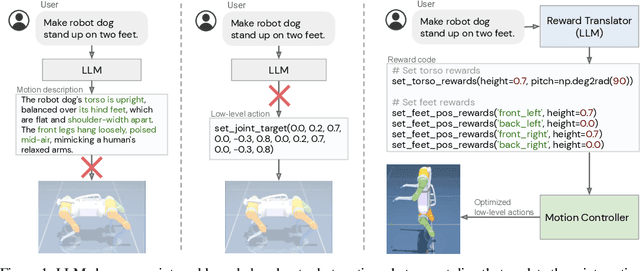
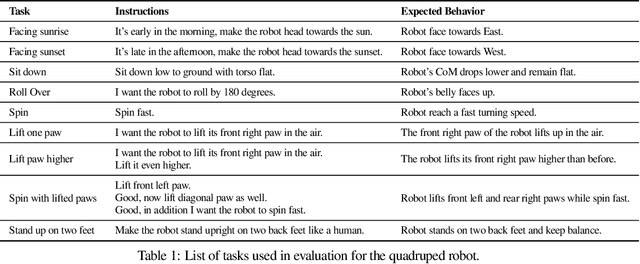

Large language models (LLMs) have demonstrated exciting progress in acquiring diverse new capabilities through in-context learning, ranging from logical reasoning to code-writing. Robotics researchers have also explored using LLMs to advance the capabilities of robotic control. However, since low-level robot actions are hardware-dependent and underrepresented in LLM training corpora, existing efforts in applying LLMs to robotics have largely treated LLMs as semantic planners or relied on human-engineered control primitives to interface with the robot. On the other hand, reward functions are shown to be flexible representations that can be optimized for control policies to achieve diverse tasks, while their semantic richness makes them suitable to be specified by LLMs. In this work, we introduce a new paradigm that harnesses this realization by utilizing LLMs to define reward parameters that can be optimized and accomplish variety of robotic tasks. Using reward as the intermediate interface generated by LLMs, we can effectively bridge the gap between high-level language instructions or corrections to low-level robot actions. Meanwhile, combining this with a real-time optimizer, MuJoCo MPC, empowers an interactive behavior creation experience where users can immediately observe the results and provide feedback to the system. To systematically evaluate the performance of our proposed method, we designed a total of 17 tasks for a simulated quadruped robot and a dexterous manipulator robot. We demonstrate that our proposed method reliably tackles 90% of the designed tasks, while a baseline using primitive skills as the interface with Code-as-policies achieves 50% of the tasks. We further validated our method on a real robot arm where complex manipulation skills such as non-prehensile pushing emerge through our interactive system.
Predictive Sampling: Real-time Behaviour Synthesis with MuJoCo
Dec 01, 2022We introduce MuJoCo MPC (MJPC), an open-source, interactive application and software framework for real-time predictive control, based on MuJoCo physics. MJPC allows the user to easily author and solve complex robotics tasks, and currently supports three shooting-based planners: derivative-based iLQG and Gradient Descent, and a simple derivative-free method we call Predictive Sampling. Predictive Sampling was designed as an elementary baseline, mostly for its pedagogical value, but turned out to be surprisingly competitive with the more established algorithms. This work does not present algorithmic advances, and instead, prioritises performant algorithms, simple code, and accessibility of model-based methods via intuitive and interactive software. MJPC is available at: github.com/deepmind/mujoco_mpc, a video summary can be viewed at: dpmd.ai/mjpc.
Shaking the foundations: delusions in sequence models for interaction and control
Oct 20, 2021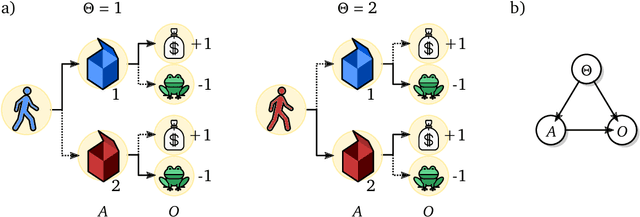
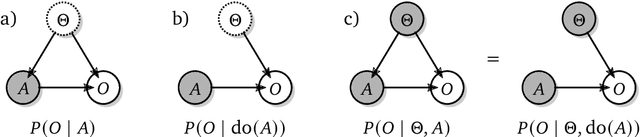
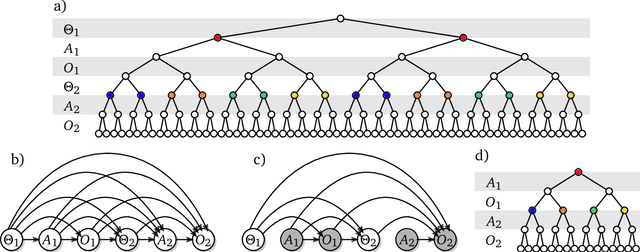
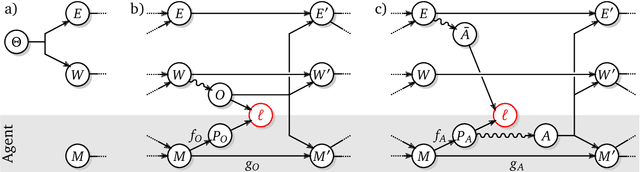
The recent phenomenal success of language models has reinvigorated machine learning research, and large sequence models such as transformers are being applied to a variety of domains. One important problem class that has remained relatively elusive however is purposeful adaptive behavior. Currently there is a common perception that sequence models "lack the understanding of the cause and effect of their actions" leading them to draw incorrect inferences due to auto-suggestive delusions. In this report we explain where this mismatch originates, and show that it can be resolved by treating actions as causal interventions. Finally, we show that in supervised learning, one can teach a system to condition or intervene on data by training with factual and counterfactual error signals respectively.
dm_control: Software and Tasks for Continuous Control
Jun 22, 2020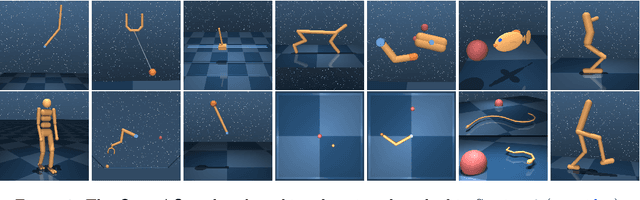

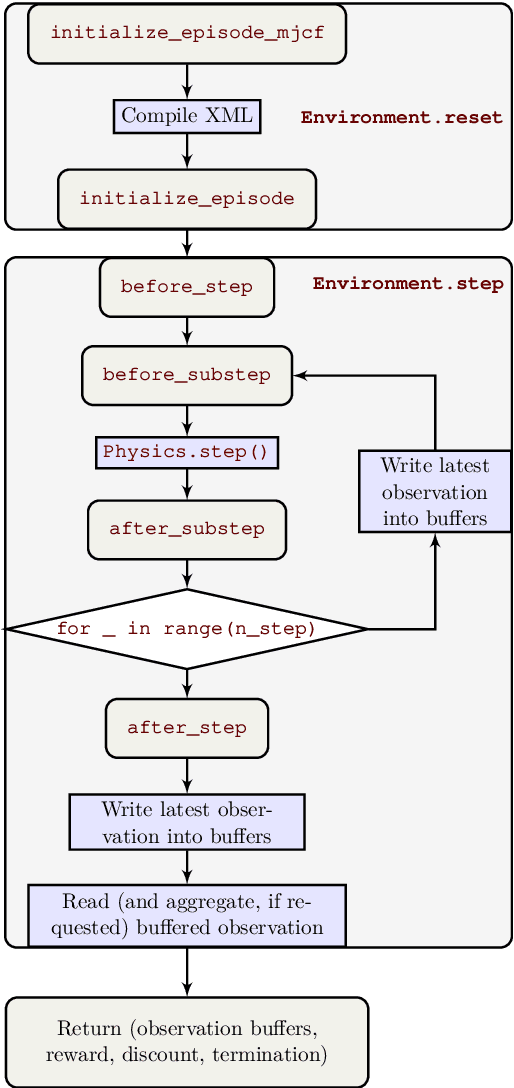
The dm_control software package is a collection of Python libraries and task suites for reinforcement learning agents in an articulated-body simulation. A MuJoCo wrapper provides convenient bindings to functions and data structures. The PyMJCF and Composer libraries enable procedural model manipulation and task authoring. The Control Suite is a fixed set of tasks with standardised structure, intended to serve as performance benchmarks. The Locomotion framework provides high-level abstractions and examples of locomotion tasks. A set of configurable manipulation tasks with a robot arm and snap-together bricks is also included. dm_control is publicly available at https://www.github.com/deepmind/dm_control
Reusable neural skill embeddings for vision-guided whole body movement and object manipulation
Nov 15, 2019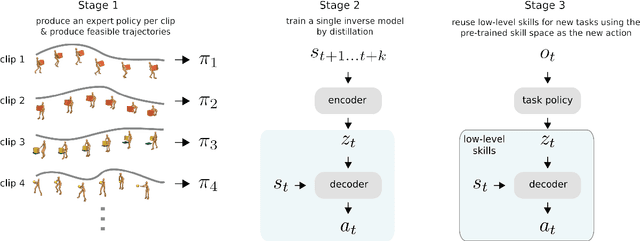
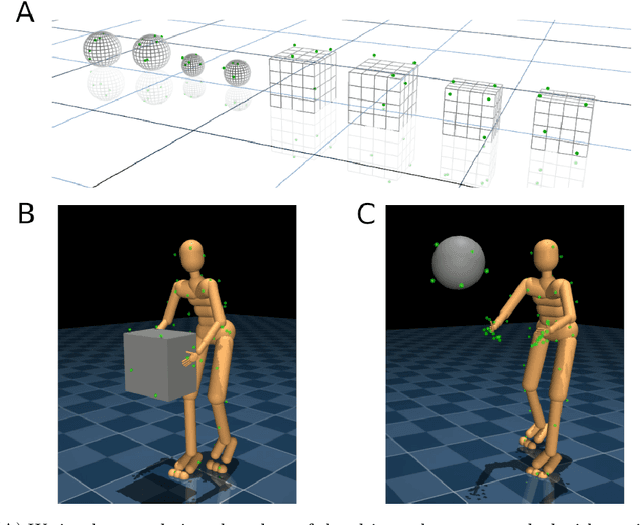
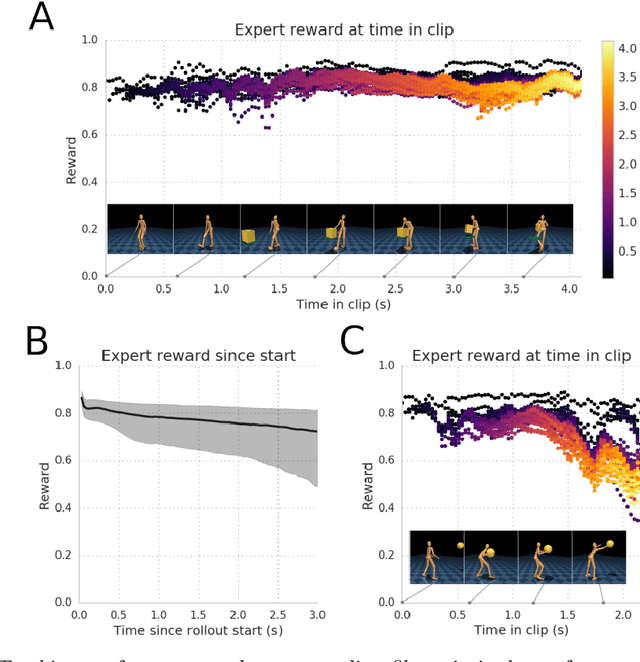
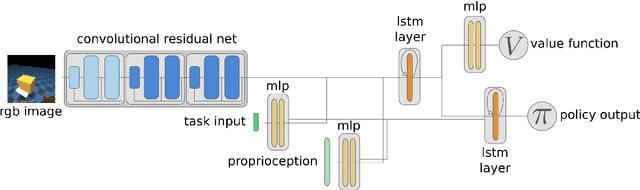
Both in simulation settings and robotics, there is an ambition to produce flexible control systems that can enable complex bodies to perform dynamic locomotion and natural object manipulation. In previous work, we developed a framework to train locomotor skills and reuse these skills for whole-body visuomotor tasks. Here, we extend this line of work to tasks involving whole body movement as well as visually guided manipulation of objects. This setting poses novel challenges in terms of task specification, exploration, and generalization. We develop an integrated approach consisting of a flexible motor primitive module, demonstrations, an instructed training regime as well as curricula in the form of task variations. We demonstrate the utility of our approach for solving challenging whole body tasks that require joint locomotion and manipulation, and characterize its behavioral robustness. We also provide a high-level overview video, see https://youtu.be/t0RDGSnE3cM .