 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgemjlab: A Lightweight Framework for GPU-Accelerated Robot Learning
Jan 29, 2026We present mjlab, a lightweight, open-source framework for robot learning that combines GPU-accelerated simulation with composable environments and minimal setup friction. mjlab adopts the manager-based API introduced by Isaac Lab, where users compose modular building blocks for observations, rewards, and events, and pairs it with MuJoCo Warp for GPU-accelerated physics. The result is a framework installable with a single command, requiring minimal dependencies, and providing direct access to native MuJoCo data structures. mjlab ships with reference implementations of velocity tracking, motion imitation, and manipulation tasks.
MuJoCo Playground
Feb 12, 2025We introduce MuJoCo Playground, a fully open-source framework for robot learning built with MJX, with the express goal of streamlining simulation, training, and sim-to-real transfer onto robots. With a simple "pip install playground", researchers can train policies in minutes on a single GPU. Playground supports diverse robotic platforms, including quadrupeds, humanoids, dexterous hands, and robotic arms, enabling zero-shot sim-to-real transfer from both state and pixel inputs. This is achieved through an integrated stack comprising a physics engine, batch renderer, and training environments. Along with video results, the entire framework is freely available at playground.mujoco.org
PianoMime: Learning a Generalist, Dexterous Piano Player from Internet Demonstrations
Jul 25, 2024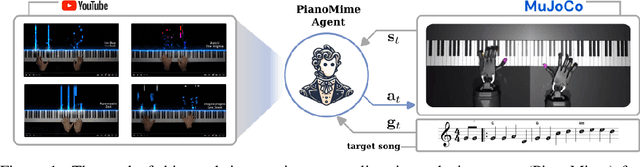
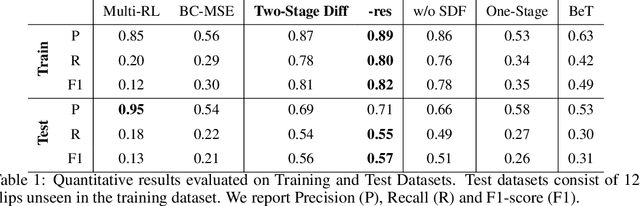
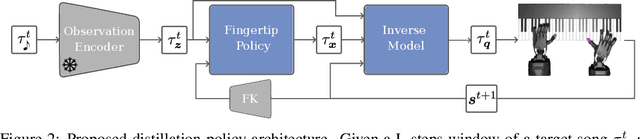

In this work, we introduce PianoMime, a framework for training a piano-playing agent using internet demonstrations. The internet is a promising source of large-scale demonstrations for training our robot agents. In particular, for the case of piano-playing, Youtube is full of videos of professional pianists playing a wide myriad of songs. In our work, we leverage these demonstrations to learn a generalist piano-playing agent capable of playing any arbitrary song. Our framework is divided into three parts: a data preparation phase to extract the informative features from the Youtube videos, a policy learning phase to train song-specific expert policies from the demonstrations and a policy distillation phase to distil the policies into a single generalist agent. We explore different policy designs to represent the agent and evaluate the influence of the amount of training data on the generalization capability of the agent to novel songs not available in the dataset. We show that we are able to learn a policy with up to 56\% F1 score on unseen songs.
RoboPianist: A Benchmark for High-Dimensional Robot Control
Apr 09, 2023



We introduce a new benchmarking suite for high-dimensional control, targeted at testing high spatial and temporal precision, coordination, and planning, all with an underactuated system frequently making-and-breaking contacts. The proposed challenge is mastering the piano through bi-manual dexterity, using a pair of simulated anthropomorphic robot hands. We call it RoboPianist, and the initial version covers a broad set of 150 variable-difficulty songs. We investigate both model-free and model-based methods on the benchmark, characterizing their performance envelopes. We observe that while certain existing methods, when well-tuned, can achieve impressive levels of performance in certain aspects, there is significant room for improvement. RoboPianist provides a rich quantitative benchmarking environment, with human-interpretable results, high ease of expansion by simply augmenting the repertoire with new songs, and opportunities for further research, including in multi-task learning, zero-shot generalization, multimodal (sound, vision, touch) learning, and imitation. Supplementary information, including videos of our control policies, can be found at https://kzakka.com/robopianist/
Predictive Sampling: Real-time Behaviour Synthesis with MuJoCo
Dec 01, 2022We introduce MuJoCo MPC (MJPC), an open-source, interactive application and software framework for real-time predictive control, based on MuJoCo physics. MJPC allows the user to easily author and solve complex robotics tasks, and currently supports three shooting-based planners: derivative-based iLQG and Gradient Descent, and a simple derivative-free method we call Predictive Sampling. Predictive Sampling was designed as an elementary baseline, mostly for its pedagogical value, but turned out to be surprisingly competitive with the more established algorithms. This work does not present algorithmic advances, and instead, prioritises performant algorithms, simple code, and accessibility of model-based methods via intuitive and interactive software. MJPC is available at: github.com/deepmind/mujoco_mpc, a video summary can be viewed at: dpmd.ai/mjpc.
XIRL: Cross-embodiment Inverse Reinforcement Learning
Jun 07, 2021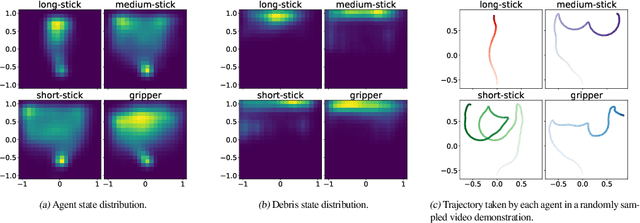

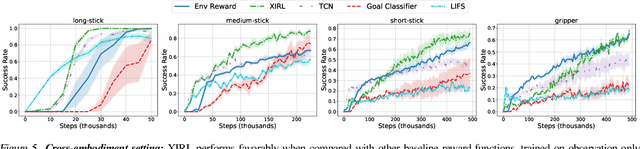
We investigate the visual cross-embodiment imitation setting, in which agents learn policies from videos of other agents (such as humans) demonstrating the same task, but with stark differences in their embodiments -- shape, actions, end-effector dynamics, etc. In this work, we demonstrate that it is possible to automatically discover and learn vision-based reward functions from cross-embodiment demonstration videos that are robust to these differences. Specifically, we present a self-supervised method for Cross-embodiment Inverse Reinforcement Learning (XIRL) that leverages temporal cycle-consistency constraints to learn deep visual embeddings that capture task progression from offline videos of demonstrations across multiple expert agents, each performing the same task differently due to embodiment differences. Prior to our work, producing rewards from self-supervised embeddings has typically required alignment with a reference trajectory, which may be difficult to acquire. We show empirically that if the embeddings are aware of task-progress, simply taking the negative distance between the current state and goal state in the learned embedding space is useful as a reward for training policies with reinforcement learning. We find our learned reward function not only works for embodiments seen during training, but also generalizes to entirely new embodiments. We also find that XIRL policies are more sample efficient than baselines, and in some cases exceed the sample efficiency of the same agent trained with ground truth sparse rewards.
Form2Fit: Learning Shape Priors for Generalizable Assembly from Disassembly
Oct 30, 2019


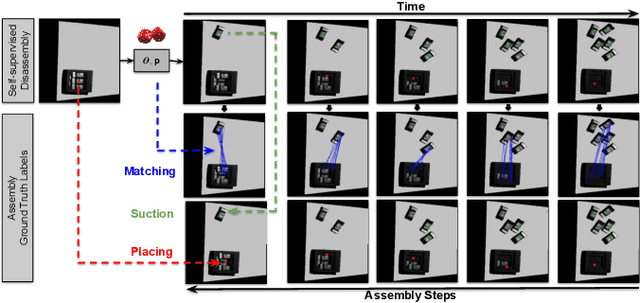
Is it possible to learn policies for robotic assembly that can generalize to new objects? We explore this idea in the context of the kit assembly task. Since classic methods rely heavily on object pose estimation, they often struggle to generalize to new objects without 3D CAD models or task-specific training data. In this work, we propose to formulate the kit assembly task as a shape matching problem, where the goal is to learn a shape descriptor that establishes geometric correspondences between object surfaces and their target placement locations from visual input. This formulation enables the model to acquire a broader understanding of how shapes and surfaces fit together for assembly -- allowing it to generalize to new objects and kits. To obtain training data for our model, we present a self-supervised data-collection pipeline that obtains ground truth object-to-placement correspondences by disassembling complete kits. Our resulting real-world system, Form2Fit, learns effective pick and place strategies for assembling objects into a variety of kits -- achieving $90\%$ average success rates under different initial conditions (e.g. varying object and kit poses), $94\%$ success under new configurations of multiple kits, and over $86\%$ success with completely new objects and kits.