 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge-Informed Kernel State Reconstruction for Interpretable Dynamical System Discovery
Jan 29, 2026Recovering governing equations from data is central to scientific discovery, yet existing methods often break down under noisy, partial observations, or rely on black-box latent dynamics that obscure mechanism. We introduce MAAT (Model Aware Approximation of Trajectories), a framework for symbolic discovery built on knowledge-informed Kernel State Reconstruction. MAAT formulates state reconstruction in a reproducing kernel Hilbert space and directly incorporates structural and semantic priors such as non-negativity, conservation laws, and domain-specific observation models into the reconstruction objective, while accommodating heterogeneous sampling and measurement granularity. This yields smooth, physically consistent state estimates with analytic time derivatives, providing a principled interface between fragmented sensor data and symbolic regression. Across twelve diverse scientific benchmarks and multiple noise regimes, MAAT substantially reduces state-estimation MSE for trajectories and derivatives used by downstream symbolic regression relative to strong baselines.
G-Sim: Generative Simulations with Large Language Models and Gradient-Free Calibration
Jun 10, 2025Constructing robust simulators is essential for asking "what if?" questions and guiding policy in critical domains like healthcare and logistics. However, existing methods often struggle, either failing to generalize beyond historical data or, when using Large Language Models (LLMs), suffering from inaccuracies and poor empirical alignment. We introduce G-Sim, a hybrid framework that automates simulator construction by synergizing LLM-driven structural design with rigorous empirical calibration. G-Sim employs an LLM in an iterative loop to propose and refine a simulator's core components and causal relationships, guided by domain knowledge. This structure is then grounded in reality by estimating its parameters using flexible calibration techniques. Specifically, G-Sim can leverage methods that are both likelihood-free and gradient-free with respect to the simulator, such as gradient-free optimization for direct parameter estimation or simulation-based inference for obtaining a posterior distribution over parameters. This allows it to handle non-differentiable and stochastic simulators. By integrating domain priors with empirical evidence, G-Sim produces reliable, causally-informed simulators, mitigating data-inefficiency and enabling robust system-level interventions for complex decision-making.
* Accepted at the 42nd International Conference on Machine Learning (ICML 2025). 9 pages, 3 figures
Improving LLM Agent Planning with In-Context Learning via Atomic Fact Augmentation and Lookahead Search
Jun 10, 2025Large Language Models (LLMs) are increasingly capable but often require significant guidance or extensive interaction history to perform effectively in complex, interactive environments. Existing methods may struggle with adapting to new information or efficiently utilizing past experiences for multi-step reasoning without fine-tuning. We introduce a novel LLM agent framework that enhances planning capabilities through in-context learning, facilitated by atomic fact augmentation and a recursive lookahead search. Our agent learns to extract task-critical ``atomic facts'' from its interaction trajectories. These facts dynamically augment the prompts provided to LLM-based components responsible for action proposal, latent world model simulation, and state-value estimation. Planning is performed via a depth-limited lookahead search, where the LLM simulates potential trajectories and evaluates their outcomes, guided by the accumulated facts and interaction history. This approach allows the agent to improve its understanding and decision-making online, leveraging its experience to refine its behavior without weight updates. We provide a theoretical motivation linking performance to the quality of fact-based abstraction and LLM simulation accuracy. Empirically, our agent demonstrates improved performance and adaptability on challenging interactive tasks, achieving more optimal behavior as it accumulates experience, showcased in tasks such as TextFrozenLake and ALFWorld.
The AI Imperative: Scaling High-Quality Peer Review in Machine Learning
Jun 09, 2025Peer review, the bedrock of scientific advancement in machine learning (ML), is strained by a crisis of scale. Exponential growth in manuscript submissions to premier ML venues such as NeurIPS, ICML, and ICLR is outpacing the finite capacity of qualified reviewers, leading to concerns about review quality, consistency, and reviewer fatigue. This position paper argues that AI-assisted peer review must become an urgent research and infrastructure priority. We advocate for a comprehensive AI-augmented ecosystem, leveraging Large Language Models (LLMs) not as replacements for human judgment, but as sophisticated collaborators for authors, reviewers, and Area Chairs (ACs). We propose specific roles for AI in enhancing factual verification, guiding reviewer performance, assisting authors in quality improvement, and supporting ACs in decision-making. Crucially, we contend that the development of such systems hinges on access to more granular, structured, and ethically-sourced peer review process data. We outline a research agenda, including illustrative experiments, to develop and validate these AI assistants, and discuss significant technical and ethical challenges. We call upon the ML community to proactively build this AI-assisted future, ensuring the continued integrity and scalability of scientific validation, while maintaining high standards of peer review.
MuJoCo Playground
Feb 12, 2025We introduce MuJoCo Playground, a fully open-source framework for robot learning built with MJX, with the express goal of streamlining simulation, training, and sim-to-real transfer onto robots. With a simple "pip install playground", researchers can train policies in minutes on a single GPU. Playground supports diverse robotic platforms, including quadrupeds, humanoids, dexterous hands, and robotic arms, enabling zero-shot sim-to-real transfer from both state and pixel inputs. This is achieved through an integrated stack comprising a physics engine, batch renderer, and training environments. Along with video results, the entire framework is freely available at playground.mujoco.org
Automatically Learning Hybrid Digital Twins of Dynamical Systems
Oct 31, 2024



Digital Twins (DTs) are computational models that simulate the states and temporal dynamics of real-world systems, playing a crucial role in prediction, understanding, and decision-making across diverse domains. However, existing approaches to DTs often struggle to generalize to unseen conditions in data-scarce settings, a crucial requirement for such models. To address these limitations, our work begins by establishing the essential desiderata for effective DTs. Hybrid Digital Twins ($\textbf{HDTwins}$) represent a promising approach to address these requirements, modeling systems using a composition of both mechanistic and neural components. This hybrid architecture simultaneously leverages (partial) domain knowledge and neural network expressiveness to enhance generalization, with its modular design facilitating improved evolvability. While existing hybrid models rely on expert-specified architectures with only parameters optimized on data, $\textit{automatically}$ specifying and optimizing HDTwins remains intractable due to the complex search space and the need for flexible integration of domain priors. To overcome this complexity, we propose an evolutionary algorithm ($\textbf{HDTwinGen}$) that employs Large Language Models (LLMs) to autonomously propose, evaluate, and optimize HDTwins. Specifically, LLMs iteratively generate novel model specifications, while offline tools are employed to optimize emitted parameters. Correspondingly, proposed models are evaluated and evolved based on targeted feedback, enabling the discovery of increasingly effective hybrid models. Our empirical results reveal that HDTwinGen produces generalizable, sample-efficient, and evolvable models, significantly advancing DTs' efficacy in real-world applications.
Discovering Preference Optimization Algorithms with and for Large Language Models
Jun 12, 2024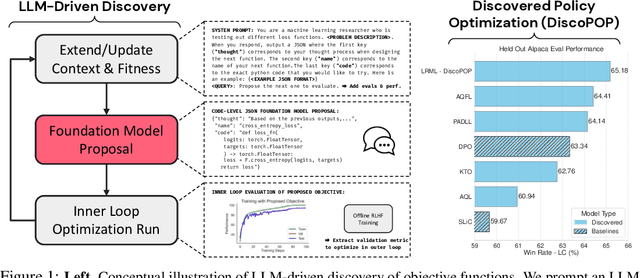

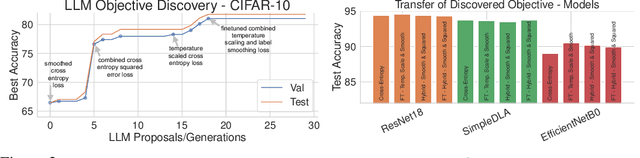
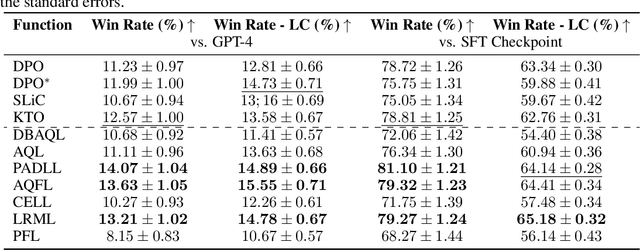
Offline preference optimization is a key method for enhancing and controlling the quality of Large Language Model (LLM) outputs. Typically, preference optimization is approached as an offline supervised learning task using manually-crafted convex loss functions. While these methods are based on theoretical insights, they are inherently constrained by human creativity, so the large search space of possible loss functions remains under explored. We address this by performing LLM-driven objective discovery to automatically discover new state-of-the-art preference optimization algorithms without (expert) human intervention. Specifically, we iteratively prompt an LLM to propose and implement new preference optimization loss functions based on previously-evaluated performance metrics. This process leads to the discovery of previously-unknown and performant preference optimization algorithms. The best performing of these we call Discovered Preference Optimization (DiscoPOP), a novel algorithm that adaptively blends logistic and exponential losses. Experiments demonstrate the state-of-the-art performance of DiscoPOP and its successful transfer to held-out tasks.
ODE Discovery for Longitudinal Heterogeneous Treatment Effects Inference
Mar 16, 2024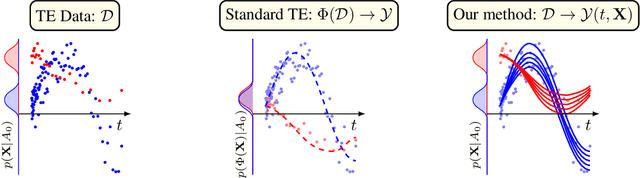

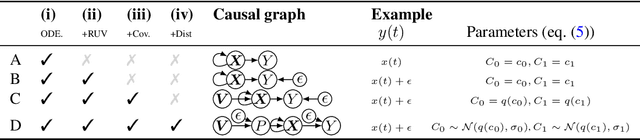
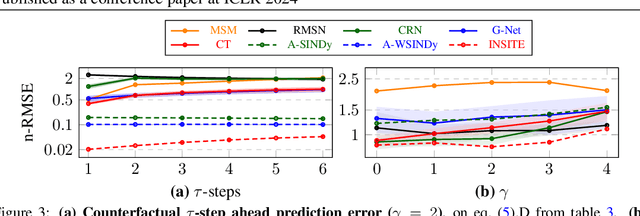
Inferring unbiased treatment effects has received widespread attention in the machine learning community. In recent years, our community has proposed numerous solutions in standard settings, high-dimensional treatment settings, and even longitudinal settings. While very diverse, the solution has mostly relied on neural networks for inference and simultaneous correction of assignment bias. New approaches typically build on top of previous approaches by proposing new (or refined) architectures and learning algorithms. However, the end result -- a neural-network-based inference machine -- remains unchallenged. In this paper, we introduce a different type of solution in the longitudinal setting: a closed-form ordinary differential equation (ODE). While we still rely on continuous optimization to learn an ODE, the resulting inference machine is no longer a neural network. Doing so yields several advantages such as interpretability, irregular sampling, and a different set of identification assumptions. Above all, we consider the introduction of a completely new type of solution to be our most important contribution as it may spark entirely new innovations in treatment effects in general. We facilitate this by formulating our contribution as a framework that can transform any ODE discovery method into a treatment effects method.
Retrieval-Augmented Thought Process as Sequential Decision Making
Feb 12, 2024



Large Language Models (LLMs) have demonstrated their strong ability to assist people and show "sparks of intelligence". However, several open challenges hinder their wider application: such as concerns over privacy, tendencies to produce hallucinations, and difficulties in handling long contexts. In this work, we address those challenges by introducing the Retrieval-Augmented Thought Process (RATP). Given access to external knowledge, RATP formulates the thought generation of LLMs as a multiple-step decision process. To optimize such a thought process, RATP leverages Monte-Carlo Tree Search, and learns a Q-value estimator that permits cost-efficient inference. In addressing the task of question-answering with private data, where ethical and security concerns limit LLM training methods, RATP achieves a 50% improvement over existing in-context retrieval-augmented language models.
Dense Reward for Free in Reinforcement Learning from Human Feedback
Feb 01, 2024
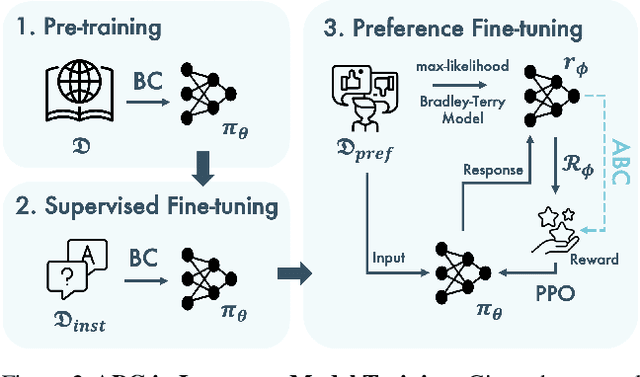
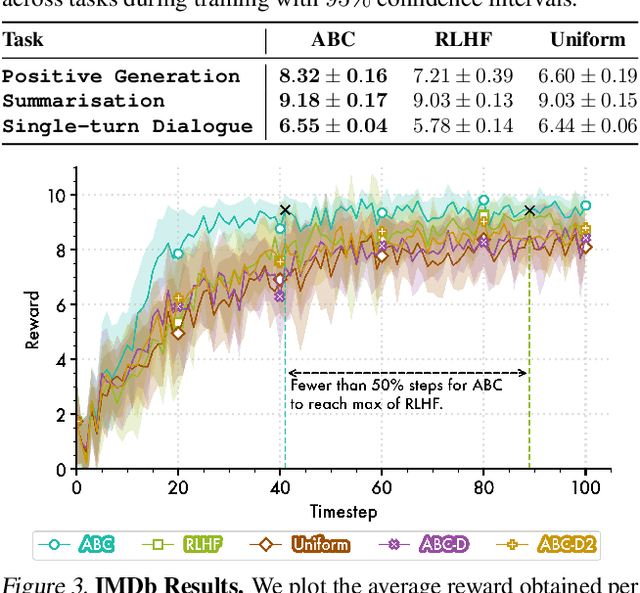
Reinforcement Learning from Human Feedback (RLHF) has been credited as the key advance that has allowed Large Language Models (LLMs) to effectively follow instructions and produce useful assistance. Classically, this involves generating completions from the LLM in response to a query before using a separate reward model to assign a score to the full completion. As an auto-regressive process, the LLM has to take many "actions" (selecting individual tokens) and only receives a single, sparse reward at the end of an episode, a setup that is known to be difficult to optimise in traditional reinforcement learning. In this work we leverage the fact that the reward model contains more information than just its scalar output, in particular, it calculates an attention map over tokens as part of the transformer architecture. We use these attention weights to redistribute the reward along the whole completion, effectively densifying the signal and highlighting the most important tokens, all without incurring extra computational cost or requiring any additional modelling. We demonstrate that, theoretically, this approach is equivalent to potential-based reward shaping, ensuring that the optimal policy remains unchanged. Empirically, we show that it stabilises training, accelerates the rate of learning, and, in practical cases, may lead to better local optima.