 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTiny Autoregressive Recursive Models
Mar 09, 2026Tiny Recursive Models (TRMs) have recently demonstrated remarkable performance on ARC-AGI, showing that very small models can compete against large foundation models through a two-step refinement mechanism that updates an internal reasoning state $z$ and the predicted output $y$. Naturally, such refinement is of interest for any predictor; it is therefore natural to wonder whether the TRM mechanism could be effectively re-adopted in autoregressive models. However, TRMs cannot be simply compared to standard models because they lack causal predictive structures and contain persistent latent states that make it difficult to isolate specific performance gains. In this paper, we propose the Autoregressive TRM and evaluate it on small autoregressive tasks. To understand its efficacy, we propose a suite of models that gradually transform a standard Transformer to a Tiny Autoregressive Recursive Model in a controlled setting that fixes the block design, token stream, and next-token objective. Across compute-matched experiments on character-level algorithmic tasks, we surprisingly find that there are some two-level refinement baselines that show strong performance. Contrary to expectations, we find no reliable performance gains from the full Autoregressive TRM architecture. These results offer potential promise for two-step refinement mechanisms more broadly but caution against investing in the autoregressive TRM-specific model as a fruitful research direction.
Learning a Dense Reasoning Reward Model from Expert Demonstration via Inverse Reinforcement Learning
Oct 02, 2025We reframe and operationalise adversarial inverse reinforcement learning (IRL) to large language model reasoning, learning a dense, token-level reward model for process supervision directly from expert demonstrations rather than imitating style via supervised fine-tuning. The learned reasoning reward serves two complementary roles: (i) it provides step-level feedback to optimise a reasoning policy during training; and (ii) it functions at inference as a critic to rerank sampled traces under fixed compute budgets. We demonstrate that our approach prioritises correctness over surface form, yielding scores that correlate with eventual answer validity and enabling interpretable localisation of errors within a trace. Empirically, on GSM8K with Llama3 and Qwen2.5 backbones, we demonstrate: (i) dense reasoning rewards can be used as a learning signal to elicit reasoning, and (ii) predictive performance is improved from reward-guided reranking (notably for Llama-based policies). By unifying training signals, inference-time selection, and token-level diagnostics into a single reasoning reward, this work suggests reusable process-level rewards with broad potential to enhance multi-step reasoning in language models.
Towards a Cascaded LLM Framework for Cost-effective Human-AI Decision-Making
Jun 16, 2025



Effective human-AI decision-making balances three key factors: the \textit{correctness} of predictions, the \textit{cost} of knowledge and reasoning complexity, and the confidence about whether to \textit{abstain} automated answers or involve human experts. In this work, we present a cascaded LLM decision framework that adaptively delegates tasks across multiple tiers of expertise -- a base model for initial candidate answers, a more capable and knowledgeable (but costlier) large model, and a human expert for when the model cascade abstains. Our method proceeds in two stages. First, a deferral policy determines whether to accept the base model's answer or regenerate it with the large model based on the confidence score. Second, an abstention policy decides whether the cascade model response is sufficiently certain or requires human intervention. Moreover, we incorporate an online learning mechanism in the framework that can leverage human feedback to improve decision quality over time. We demonstrate this approach to general question-answering (ARC-Easy and ARC-Challenge) and medical question-answering (MedQA and MedMCQA). Our results show that our cascaded strategy outperforms in most cases single-model baselines in accuracy while reducing cost and providing a principled way to handle abstentions.
Few-shot Steerable Alignment: Adapting Rewards and LLM Policies with Neural Processes
Dec 18, 2024



As large language models (LLMs) become increasingly embedded in everyday applications, ensuring their alignment with the diverse preferences of individual users has become a critical challenge. Currently deployed approaches typically assume homogeneous user objectives and rely on single-objective fine-tuning. However, human preferences are inherently heterogeneous, influenced by various unobservable factors, leading to conflicting signals in preference data. Existing solutions addressing this diversity often require costly datasets labelled for specific objectives and involve training multiple reward models or LLM policies, which is computationally expensive and impractical. In this work, we present a novel framework for few-shot steerable alignment, where users' underlying preferences are inferred from a small sample of their choices. To achieve this, we extend the Bradley-Terry-Luce model to handle heterogeneous preferences with unobserved variability factors and propose its practical implementation for reward modelling and LLM fine-tuning. Thanks to our proposed approach of functional parameter-space conditioning, LLMs trained with our framework can be adapted to individual preferences at inference time, generating outputs over a continuum of behavioural modes. We empirically validate the effectiveness of methods, demonstrating their ability to capture and align with diverse human preferences in a data-efficient manner. Our code is made available at: https://github.com/kasia-kobalczyk/few-shot-steerable-alignment.
Discovering Preference Optimization Algorithms with and for Large Language Models
Jun 12, 2024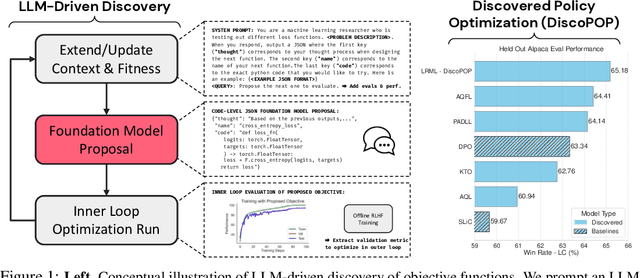

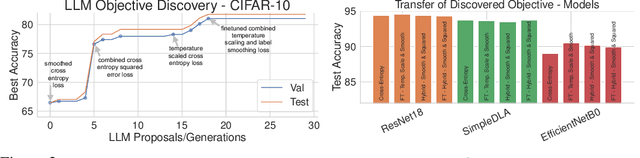
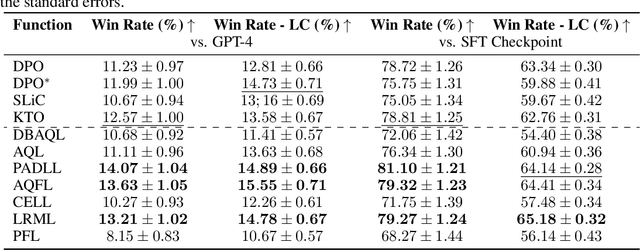
Offline preference optimization is a key method for enhancing and controlling the quality of Large Language Model (LLM) outputs. Typically, preference optimization is approached as an offline supervised learning task using manually-crafted convex loss functions. While these methods are based on theoretical insights, they are inherently constrained by human creativity, so the large search space of possible loss functions remains under explored. We address this by performing LLM-driven objective discovery to automatically discover new state-of-the-art preference optimization algorithms without (expert) human intervention. Specifically, we iteratively prompt an LLM to propose and implement new preference optimization loss functions based on previously-evaluated performance metrics. This process leads to the discovery of previously-unknown and performant preference optimization algorithms. The best performing of these we call Discovered Preference Optimization (DiscoPOP), a novel algorithm that adaptively blends logistic and exponential losses. Experiments demonstrate the state-of-the-art performance of DiscoPOP and its successful transfer to held-out tasks.
This Reads Like That: Deep Learning for Interpretable Natural Language Processing
Oct 25, 2023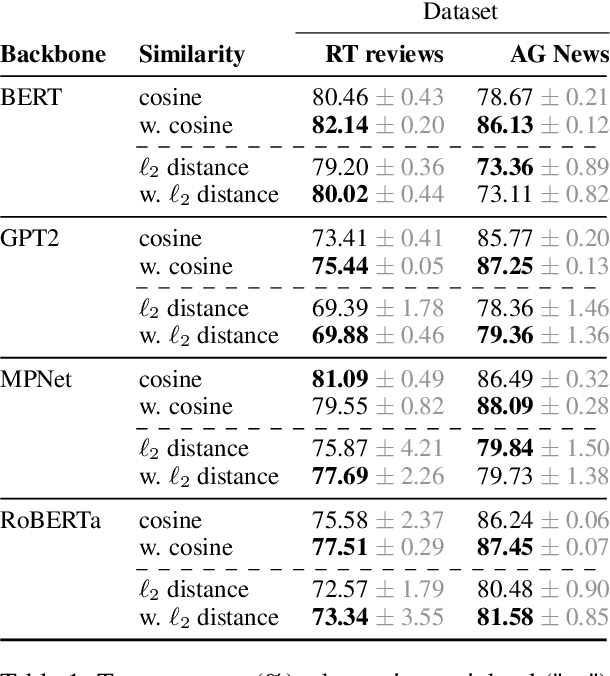
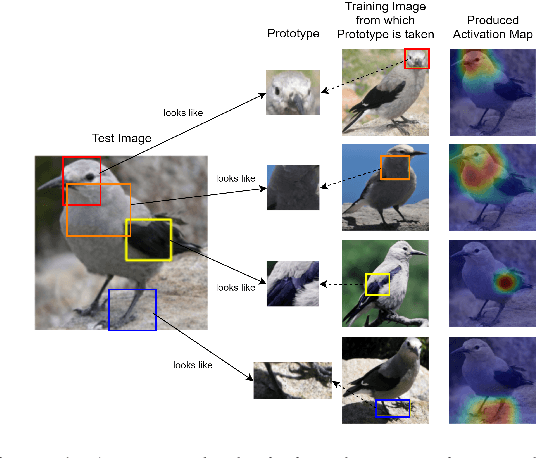
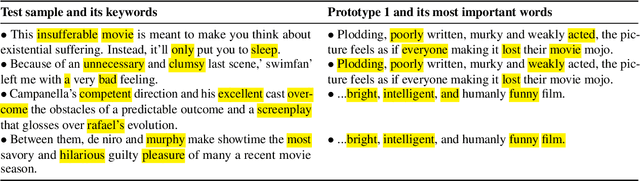

Prototype learning, a popular machine learning method designed for inherently interpretable decisions, leverages similarities to learned prototypes for classifying new data. While it is mainly applied in computer vision, in this work, we build upon prior research and further explore the extension of prototypical networks to natural language processing. We introduce a learned weighted similarity measure that enhances the similarity computation by focusing on informative dimensions of pre-trained sentence embeddings. Additionally, we propose a post-hoc explainability mechanism that extracts prediction-relevant words from both the prototype and input sentences. Finally, we empirically demonstrate that our proposed method not only improves predictive performance on the AG News and RT Polarity datasets over a previous prototype-based approach, but also improves the faithfulness of explanations compared to rationale-based recurrent convolutions.
Natural Language Processing Methods to Identify Oncology Patients at High Risk for Acute Care with Clinical Notes
Sep 28, 2022



Clinical notes are an essential component of a health record. This paper evaluates how natural language processing (NLP) can be used to identify the risk of acute care use (ACU) in oncology patients, once chemotherapy starts. Risk prediction using structured health data (SHD) is now standard, but predictions using free-text formats are complex. This paper explores the use of free-text notes for the prediction of ACU instead of SHD. Deep Learning models were compared to manually engineered language features. Results show that SHD models minimally outperform NLP models; an l1-penalised logistic regression with SHD achieved a C-statistic of 0.748 (95%-CI: 0.735, 0.762), while the same model with language features achieved 0.730 (95%-CI: 0.717, 0.745) and a transformer-based model achieved 0.702 (95%-CI: 0.688, 0.717). This paper shows how language models can be used in clinical applications and underlines how risk bias is different for diverse patient groups, even using only free-text data.
This Looks Like That Does it? Shortcomings of Latent Space Prototype Interpretability in Deep Networks
May 10, 2021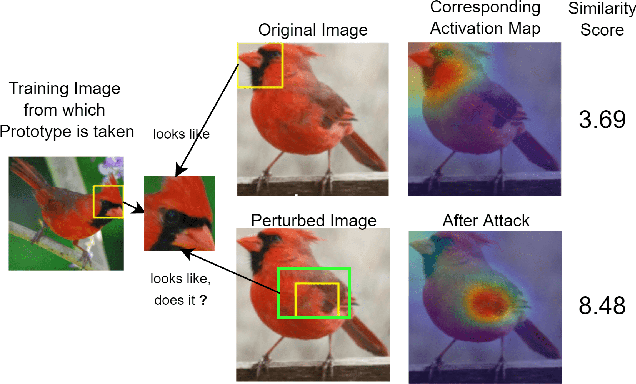

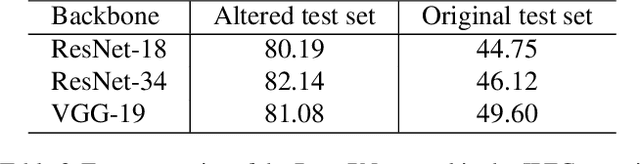
Deep neural networks that yield human interpretable decisions by architectural design have lately become an increasingly popular alternative to post hoc interpretation of traditional black-box models. Among these networks, the arguably most widespread approach is so-called prototype learning, where similarities to learned latent prototypes serve as the basis of classifying an unseen data point. In this work, we point to an important shortcoming of such approaches. Namely, there is a semantic gap between similarity in latent space and similarity in input space, which can corrupt interpretability. We design two experiments that exemplify this issue on the so-called ProtoPNet. Specifically, we find that this network's interpretability mechanism can be led astray by intentionally crafted or even JPEG compression artefacts, which can produce incomprehensible decisions. We argue that practitioners ought to have this shortcoming in mind when deploying prototype-based models in practice.