 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePRIME: A Few Primitives Can Boost Robustness to Common Corruptions
Dec 27, 2021



Despite their impressive performance on image classification tasks, deep networks have a hard time generalizing to many common corruptions of their data. To fix this vulnerability, prior works have mostly focused on increasing the complexity of their training pipelines, combining multiple methods, in the name of diversity. However, in this work, we take a step back and follow a principled approach to achieve robustness to common corruptions. We propose PRIME, a general data augmentation scheme that consists of simple families of max-entropy image transformations. We show that PRIME outperforms the prior art for corruption robustness, while its simplicity and plug-and-play nature enables it to be combined with other methods to further boost their robustness. Furthermore, we analyze PRIME to shed light on the importance of the mixing strategy on synthesizing corrupted images, and to reveal the robustness-accuracy trade-offs arising in the context of common corruptions. Finally, we show that the computational efficiency of our method allows it to be easily used in both on-line and off-line data augmentation schemes.
This Looks Like That Does it? Shortcomings of Latent Space Prototype Interpretability in Deep Networks
May 10, 2021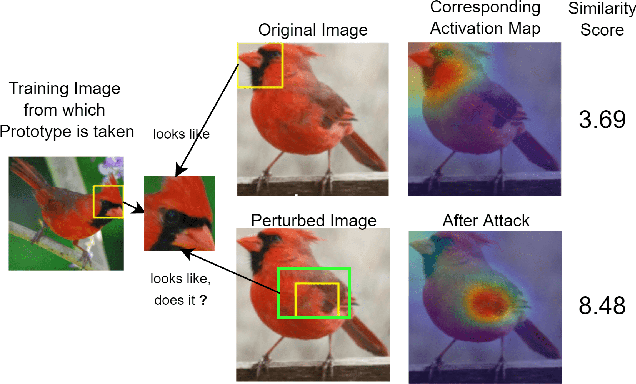
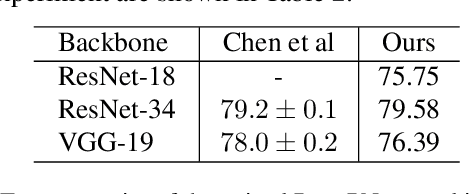

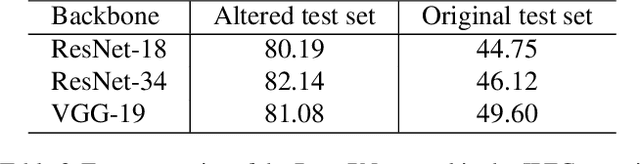
Deep neural networks that yield human interpretable decisions by architectural design have lately become an increasingly popular alternative to post hoc interpretation of traditional black-box models. Among these networks, the arguably most widespread approach is so-called prototype learning, where similarities to learned latent prototypes serve as the basis of classifying an unseen data point. In this work, we point to an important shortcoming of such approaches. Namely, there is a semantic gap between similarity in latent space and similarity in input space, which can corrupt interpretability. We design two experiments that exemplify this issue on the so-called ProtoPNet. Specifically, we find that this network's interpretability mechanism can be led astray by intentionally crafted or even JPEG compression artefacts, which can produce incomprehensible decisions. We argue that practitioners ought to have this shortcoming in mind when deploying prototype-based models in practice.
Attacker Behaviour Profiling using Stochastic Ensemble of Hidden Markov Models
May 28, 2019
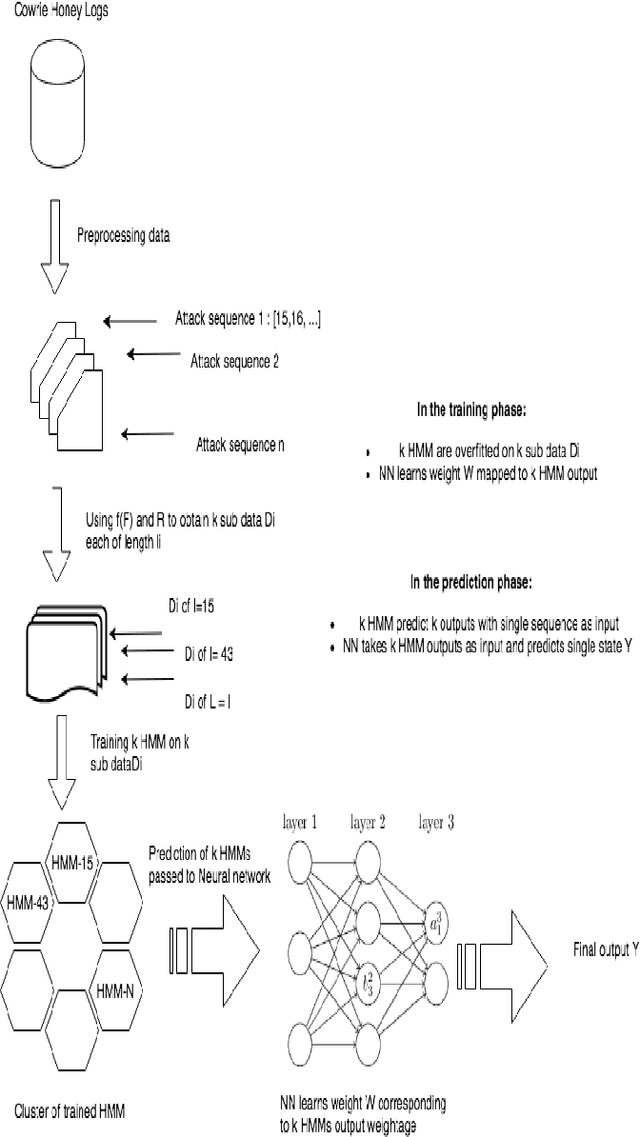
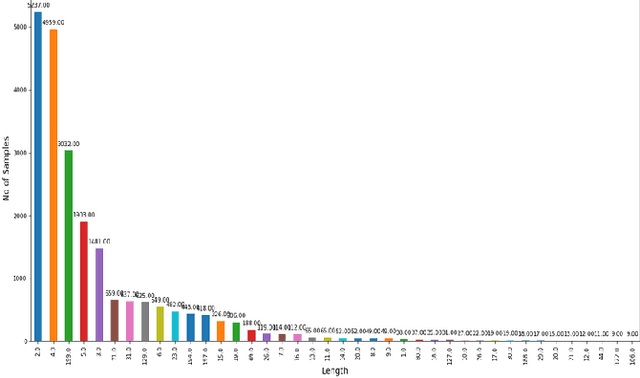

Cyber threat intelligence is one of the emerging areas of focus in information security. Much of the recent work has focused on rule-based methods and detection of network attacks using Intrusion Detection algorithms. In this paper we propose a framework for inspecting and modelling the behavioural aspect of an attacker to obtain better insight predictive power on his future actions. For modelling we propose a novel semi-supervised algorithm called Fusion Hidden Markov Model (FHMM) which is more robust to noise, requires comparatively less training time, and utilizes the benefits of ensemble learning to better model temporal relationships in data. This paper evaluates the performances of FHMM and compares it with both traditional algorithms like Markov Chain, Hidden Markov Model (HMM) and recently developed Deep Recurrent Neural Network (Deep RNN) architectures. We conduct the experiments on dataset consisting of real data attacks on a Cowrie honeypot system. FHMM provides accuracy comparable to deep RNN architectures at significant lower training time. Given these experimental results, we recommend using FHMM for modelling discrete temporal data for significantly faster training and better performance than existing methods.