 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResampled Datasets Are Not Enough: Mitigating Societal Bias Beyond Single Attributes
Jul 04, 2024
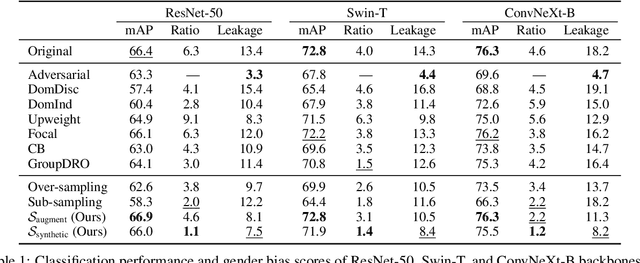
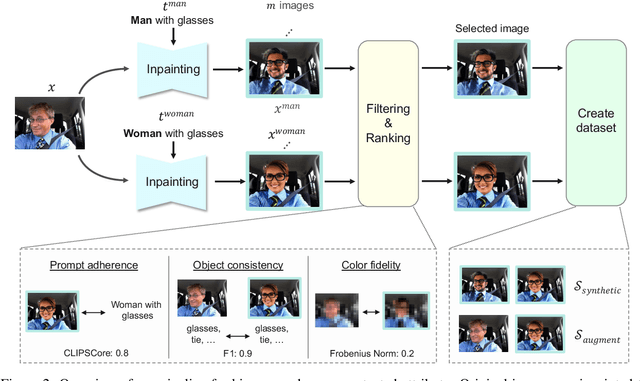
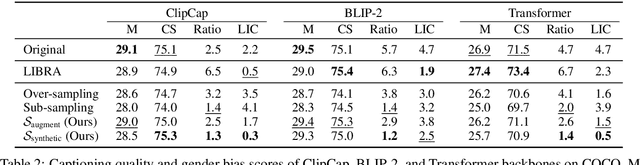
We tackle societal bias in image-text datasets by removing spurious correlations between protected groups and image attributes. Traditional methods only target labeled attributes, ignoring biases from unlabeled ones. Using text-guided inpainting models, our approach ensures protected group independence from all attributes and mitigates inpainting biases through data filtering. Evaluations on multi-label image classification and image captioning tasks show our method effectively reduces bias without compromising performance across various models.
Ethical Considerations for Collecting Human-Centric Image Datasets
Feb 07, 2023
Human-centric image datasets are critical to the development of computer vision technologies. However, recent investigations have foregrounded significant ethical issues related to privacy and bias, which have resulted in the complete retraction, or modification, of several prominent datasets. Recent works have tried to reverse this trend, for example, by proposing analytical frameworks for ethically evaluating datasets, the standardization of dataset documentation and curation practices, privacy preservation methodologies, as well as tools for surfacing and mitigating representational biases. Little attention, however, has been paid to the realities of operationalizing ethical data collection. To fill this gap, we present a set of key ethical considerations and practical recommendations for collecting more ethically-minded human-centric image data. Our research directly addresses issues of privacy and bias by contributing to the research community best practices for ethical data collection, covering purpose, privacy and consent, as well as diversity. We motivate each consideration by drawing on lessons from current practices, dataset withdrawals and audits, and analytical ethical frameworks. Our research is intended to augment recent scholarship, representing an important step toward more responsible data curation practices.
Data augmentation with mixtures of max-entropy transformations for filling-level classification
Mar 08, 2022



We address the problem of distribution shifts in test-time data with a principled data augmentation scheme for the task of content-level classification. In such a task, properties such as shape or transparency of test-time containers (cup or drinking glass) may differ from those represented in the training data. Dealing with such distribution shifts using standard augmentation schemes is challenging and transforming the training images to cover the properties of the test-time instances requires sophisticated image manipulations. We therefore generate diverse augmentations using a family of max-entropy transformations that create samples with new shapes, colors and spectral characteristics. We show that such a principled augmentation scheme, alone, can replace current approaches that use transfer learning or can be used in combination with transfer learning to improve its performance.
PRIME: A Few Primitives Can Boost Robustness to Common Corruptions
Dec 27, 2021



Despite their impressive performance on image classification tasks, deep networks have a hard time generalizing to many common corruptions of their data. To fix this vulnerability, prior works have mostly focused on increasing the complexity of their training pipelines, combining multiple methods, in the name of diversity. However, in this work, we take a step back and follow a principled approach to achieve robustness to common corruptions. We propose PRIME, a general data augmentation scheme that consists of simple families of max-entropy image transformations. We show that PRIME outperforms the prior art for corruption robustness, while its simplicity and plug-and-play nature enables it to be combined with other methods to further boost their robustness. Furthermore, we analyze PRIME to shed light on the importance of the mixing strategy on synthesizing corrupted images, and to reveal the robustness-accuracy trade-offs arising in the context of common corruptions. Finally, we show that the computational efficiency of our method allows it to be easily used in both on-line and off-line data augmentation schemes.
A neural anisotropic view of underspecification in deep learning
Apr 29, 2021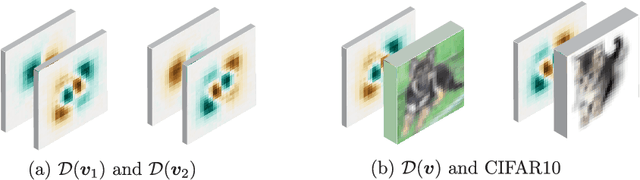



The underspecification of most machine learning pipelines means that we cannot rely solely on validation performance to assess the robustness of deep learning systems to naturally occurring distribution shifts. Instead, making sure that a neural network can generalize across a large number of different situations requires to understand the specific way in which it solves a task. In this work, we propose to study this problem from a geometric perspective with the aim to understand two key characteristics of neural network solutions in underspecified settings: how is the geometry of the learned function related to the data representation? And, are deep networks always biased towards simpler solutions, as conjectured in recent literature? We show that the way neural networks handle the underspecification of these problems is highly dependent on the data representation, affecting both the geometry and the complexity of the learned predictors. Our results highlight that understanding the architectural inductive bias in deep learning is fundamental to address the fairness, robustness, and generalization of these systems.
Improving filling level classification with adversarial training
Feb 08, 2021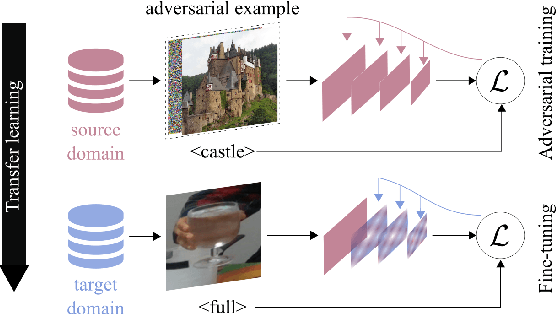
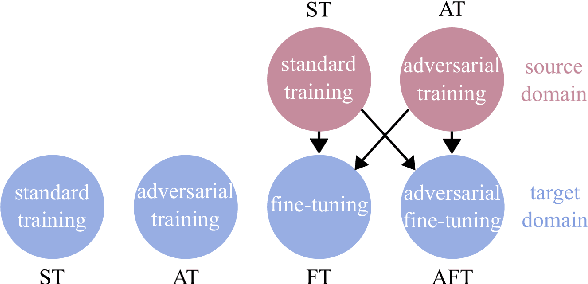


We investigate the problem of classifying - from a single image - the level of content in a cup or a drinking glass. This problem is made challenging by several ambiguities caused by transparencies, shape variations and partial occlusions, and by the availability of only small training datasets. In this paper, we tackle this problem with an appropriate strategy for transfer learning. Specifically, we use adversarial training in a generic source dataset and then refine the training with a task-specific dataset. We also discuss and experimentally evaluate several training strategies and their combination on a range of container types of the CORSMAL Containers Manipulation dataset. We show that transfer learning with adversarial training in the source domain consistently improves the classification accuracy on the test set and limits the overfitting of the classifier to specific features of the training data.
Optimism in the Face of Adversity: Understanding and Improving Deep Learning through Adversarial Robustness
Oct 19, 2020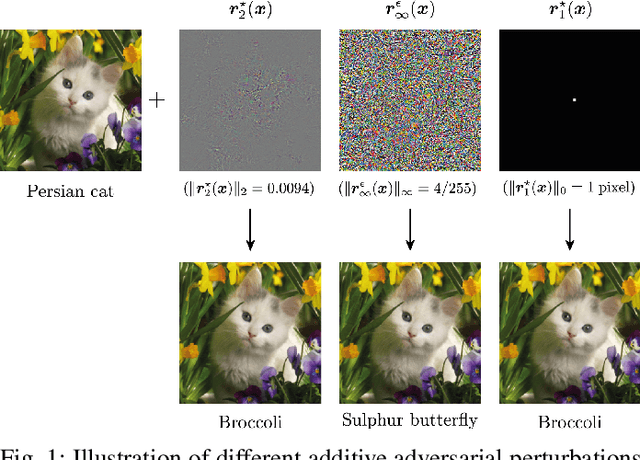
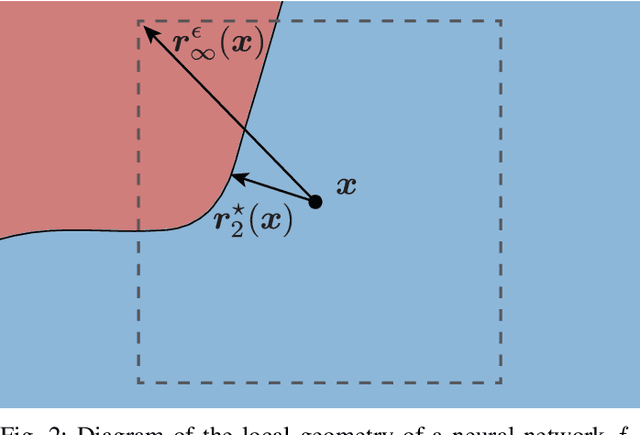
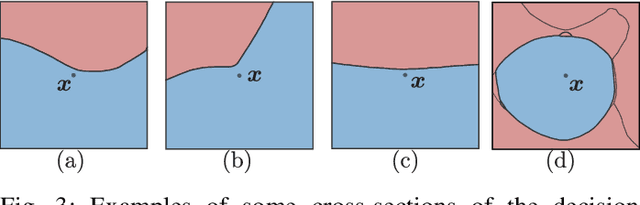
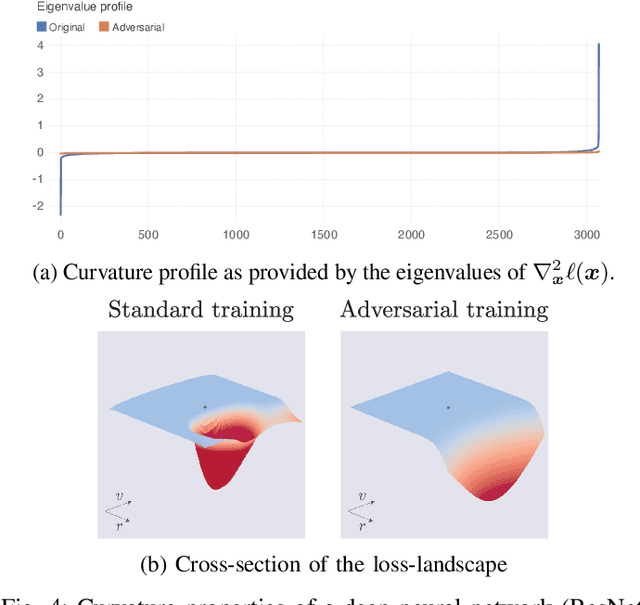
Driven by massive amounts of data and important advances in computational resources, new deep learning systems have achieved outstanding results in a large spectrum of applications. Nevertheless, our current theoretical understanding on the mathematical foundations of deep learning lags far behind its empirical success. Towards solving the vulnerability of neural networks, however, the field of adversarial robustness has recently become one of the main sources of explanations of our deep models. In this article, we provide an in-depth review of the field of adversarial robustness in deep learning, and give a self-contained introduction to its main notions. But, in contrast to the mainstream pessimistic perspective of adversarial robustness, we focus on the main positive aspects that it entails. We highlight the intuitive connection between adversarial examples and the geometry of deep neural networks, and eventually explore how the geometric study of adversarial examples can serve as a powerful tool to understand deep learning. Furthermore, we demonstrate the broad applicability of adversarial robustness, providing an overview of the main emerging applications of adversarial robustness beyond security. The goal of this article is to provide readers with a set of new perspectives to understand deep learning, and to supply them with intuitive tools and insights on how to use adversarial robustness to improve it.
Towards robust sensing for Autonomous Vehicles: An adversarial perspective
Jul 14, 2020
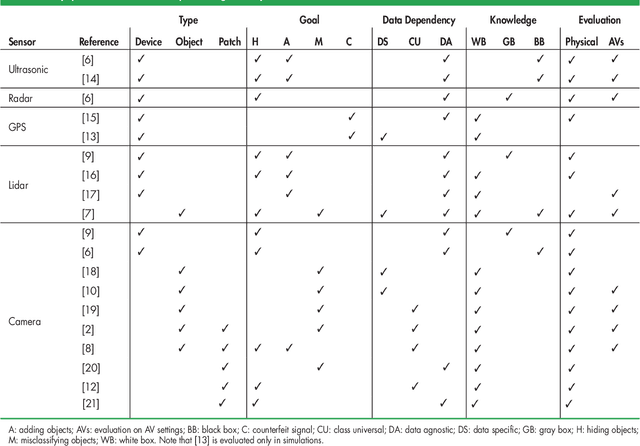

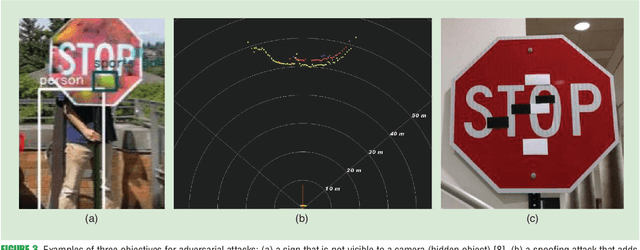
Autonomous Vehicles rely on accurate and robust sensor observations for safety critical decision-making in a variety of conditions. Fundamental building blocks of such systems are sensors and classifiers that process ultrasound, RADAR, GPS, LiDAR and camera signals~\cite{Khan2018}. It is of primary importance that the resulting decisions are robust to perturbations, which can take the form of different types of nuisances and data transformations, and can even be adversarial perturbations (APs). Adversarial perturbations are purposefully crafted alterations of the environment or of the sensory measurements, with the objective of attacking and defeating the autonomous systems. A careful evaluation of the vulnerabilities of their sensing system(s) is necessary in order to build and deploy safer systems in the fast-evolving domain of AVs. To this end, we survey the emerging field of sensing in adversarial settings: after reviewing adversarial attacks on sensing modalities for autonomous systems, we discuss countermeasures and present future research directions.
Neural Anisotropy Directions
Jun 17, 2020


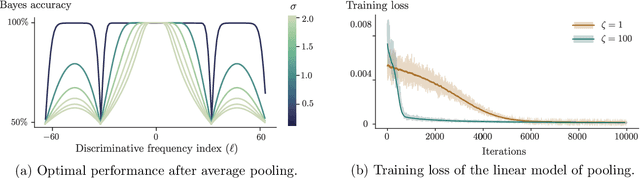
In this work, we analyze the role of the network architecture in shaping the inductive bias of deep classifiers. To that end, we start by focusing on a very simple problem, i.e., classifying a class of linearly separable distributions, and show that, depending on the direction of the discriminative feature of the distribution, many state-of-the-art deep convolutional neural networks (CNNs) have a surprisingly hard time solving this simple task. We then define as neural anisotropy directions (NADs) the vectors that encapsulate the directional inductive bias of an architecture. These vectors, which are specific for each architecture and hence act as a signature, encode the preference of a network to separate the input data based on some particular features. We provide an efficient method to identify NADs for several CNN architectures and thus reveal their directional inductive biases. Furthermore, we show that, for the CIFAR-10 dataset, NADs characterize features used by CNNs to discriminate between different classes.
Hold me tight! Influence of discriminative features on deep network boundaries
Feb 15, 2020

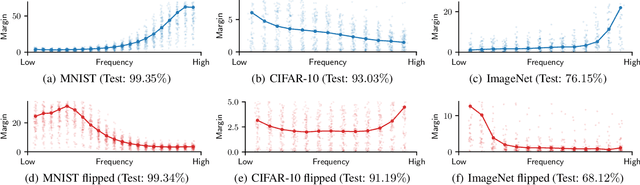

Important insights towards the explainability of neural networks and their properties reside in the formation of their decision boundaries. In this work, we borrow tools from the field of adversarial robustness and propose a new framework that permits to relate the features of the dataset with the distance of data samples to the decision boundary along specific directions. We demonstrate that the inductive bias of deep learning has the tendency to generate classification functions that are invariant along non-discriminative directions of the dataset. More surprisingly, we further show that training on small perturbations of the data samples are sufficient to completely change the decision boundary. This is actually the characteristic exploited by the so-called adversarial training to produce robust classifiers. Our general framework can be used to reveal the effect of specific dataset features on the macroscopic properties of deep models and to develop a better understanding of the successes and limitations of deep learning.